Ubuntu下Hadoop环境的配置
1:jdk的配置。详情请看jdk的配置 http://www.linuxidc.com/Linux/2012-11/74190.htm
2:hadoop的安装 下载地址 http://labs.xiaonei.com/apache-mirror/hadoop/core/hadoop-0.20.2/hadoop-0.20.2.tar.gz
1、安装java和ssh
在Ubuntu下使用apt-get就可以很方便地将JDK和ssh安装好,Ubuntu一般默认安装有ssh客户端,并没有安装服务器端,输入"apt-get install ssh"便会将服务器安装好,然后使用"/etc/init.d/ssh start"将服务器运行起来。
2、创建hadoop用户组和hadoop用户
#addgroup hadoop
#adduser --ingroup hadoop hadoop
3、配置ssh
切换到hadoop用户下
#su - hadoop
生成密钥对
hadoop@ubuntu:~$ssh-keygen -t rsa -P ""
将公钥拷贝到服务器上
hadoop@ubuntu:~$cat $HOME/.ssh/id_rsa.pub >> $HOME/.ssh/authorized_keys
4、安装Hadoop
Hadoop不需要安装解压后就可以用了,以root用户运行下面的命令。
#cd /usr/local
#tar xzf hadoop-0.20.0.tar.gz
#mv hadoop-0.20.0 hadoop
#chown -R hadoop:hadoop hadoop
5、配置Hadoop
打开conf/hadoop-env.sh,修改其中一句就ok了。将“#export JAVA_HOME=/usr/lib/j2sdk1.5-sun”改成“export JAVA_HOME=/usr/lib/jvm/java-6-sun“就好了,当然要看安装的java版本了,Ubuntu 9.10的源的Java版本就是1.6。
接着修改core-site.xml文件,填入以下内容(/local/hadoop-datastore/hadoop-hadoop目录必须存在,并且需要将目录属主改成hadoop用户,${user.name}这个变量不知道是哪儿定义的):
scheme and authority determine the FileSystem implementation. The
uri's scheme determines the config property (fs.SCHEME.impl) naming
the FileSystem implementation class. The uri's authority is used to
determine the host, port, etc. for a filesystem.
The actual number of replications can be specified when the file is created.
The default is used if replication is not specified in create time.
然后编辑mapred-site.xml文件,输入以下内容:
at. If "local", then jobs are run in-process as a single map
and reduce task.
原文中似乎将这两段配置均放在了hadoop-site.xml配置文件中,0.20.0版本之后的Hadoop似乎不再有这个配置文件了,取而代之是core-site.xml,如果将这些内容全部放入这个文件中会出问题。TaskTracker和JobTracker将运行不起来,log记录的错误为:
2009-10-31 21:43:28,399 ERROR org.apache.hadoop.mapred.TaskTracker: Can not start task tracker because java.lang.RuntimeException: Not a host:port pair: local
这个错误让我郁闷了好久,偶然的机会在一个台湾的网页上看到说必须将第二段放入mapred-site.xml文件中,这样果然ok了 ^_^
Ubuntu 12.10 +Hadoop 1.2.1版本集群配置
在Ubuntu 12.10 上安装部署Openstack http://www.linuxidc.com/Linux/2013-08/88184.htm
Ubuntu 12.04 OpenStack Swift单节点部署手册 http://www.linuxidc.com/Linux/2013-08/88182.htm
在Ubuntu上安装OpenStack的Swift组件-installing openstack object storage http://www.linuxidc.com/Linux/2013-08/88180.htm
OpenStack Hands on lab系列 http://www.linuxidc.com/Linux/2013-08/88170.htm
二、准备安装环境
我的本机是环境是windows8.1系统 +VMvare9虚拟机。VMvare中虚拟了3个ubuntu 12.10的系统,JDK版本为1.7.0_17.集群环境为一个master,两个slave,节点代号分别为node1,node2,node3.保证以下ip地址可以相互ping通,并且在/etc/hosts中进行配置
| 机器名 | Ip地址 | 作用 |
| node1 | 202.193.74.173 | NameNode,JobTraker |
| node2 | 202.193.75.231 | DataNode,TaskTraker |
| node3 |
202.193.74.3 |
DataNode,TaskTraker |
三、安装环境
1、首先修改机器名
使用root权限,使用命令:
sudo vi /etc/hosts
其中node1、node2、node3的/etc/hosts配置为:
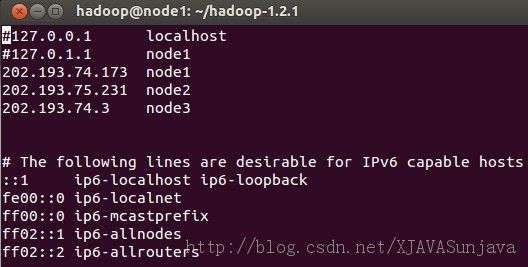
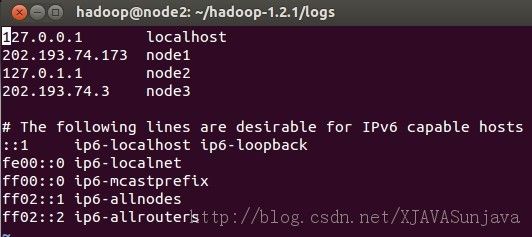
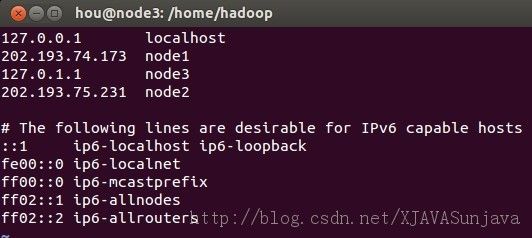
/etc/hosts的配置很重要,如果配置的不合适会出各种问题,会影响到后面的SSH配置以及Hadoop的DataNode节点的启动。
2、安装JDK
Ubuntu下的JDK配置请参考: http://www.linuxidc.com/Linux/2012-05/59858.htm
3、添加用户
在root权限下使用以下命令添加hadoop用户,在三个虚拟机上都添加这个用户
sudo adduser hadoop
将下载到的hadoop-1.2.1.tar文件放到/home/hadoop/目录下解压,然后修改解压后的文件夹的权限,命令如下:
sudo tar -xvzf hadoop-1.2.1.tar #解压命令
chown -R hadoop:hadoop hadoop-1.2.1(文件夹名)
4、安装和配置SSH
1)在三台实验机器上使用以下命令安装ssh:
sudo apt-get install ssh
安装以后执行测试:
netstat -nat #查看22端口是否开启
ssh localhost #测试ssh是否成功连接
输入当前用户名和密码按回车确认,说明安装成功,同时ssh登陆需要密码。
这种默认安装方式完后,默认配置文件是在/etc/ssh/目录下。sshd配置文件是:/etc/ssh/sshd_config
接下来请看第2页精彩内容: http://www.linuxidc.com/Linux/2013-09/90600p2.htm
2)配置SSH无密码访问
在Hadoop启动以后,Namenode是通过SSH(Secure Shell)来启动和停止各个datanode上的各种守护进程的,这就须要在节点之间执行指令的时候是不须要输入密码的形式,故我们须要配置SSH运用无密码公钥认证的形式。
以本文中的三台机器为例,现在node1是主节点,他须要连接node2和node3。须要确定每台机器上都安装了ssh,并且datanode机器上sshd服务已经启动。
( 说明:hadoop@hadoop~]$ssh-keygen -t rsa
这个命令将为hadoop上的用户hadoop生成其密钥对,询问其保存路径时直接回车采用默认路径,当提示要为生成的密钥输入passphrase的时候,直接回车,也就是将其设定为空密码。生成的密钥对id_rsa,id_rsa.pub,默认存储在/home/hadoop/.ssh目录下然后将id_rsa.pub的内容复制到每个机器(也包括本机)的/home/dbrg/.ssh/authorized_keys文件中,如果机器上已经有authorized_keys这个文件了,就在文件末尾加上id_rsa.pub中的内容,如果没有authorized_keys这个文件,直接复制过去就行.)
3)首先设置namenode的ssh为无需密码自动登陆
切换到hadoop用户( 保证用户hadoop可以无需密码登录,因为我们后面安装的hadoop属主是hadoop用户。)
su hadoop
cd /home/hadoop
ssh-keygen -t rsa
最后一个命令输入完成以后一直按回车
完成后会在/home/hadoop/目录下产生完全隐藏的文件夹.ssh
进入.ssh文件夹,然后将id_rsa.pub复制到authorized_keys文件,命令如下
cd .ssh # 进入.ssh目录
cp id_rsa.pub authorized_keys #生成authorized_keys文件
ssh localhost #测试无密码登陆,第一可能需要密码
ssh node1 #同上一个命令一样
node1无密码登陆的效果:
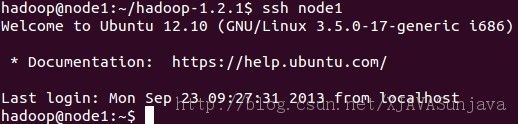
4)配置node1无密码访问node2和node3
首先以node2为例,node3参照node2的方法
在node2中执行以下命令:
su hadoop
cd /home/hadoop
ssh-keygen -t rsa #生成公钥和私钥,一路回车
在node1中进入/home/hadoop/.ssh目录中,复制authorized_keys到node2的.ssh文件夹中
执行以下命令
scp authorized_keys hadoop@node2:/home/hadoop/.ssh #复制authorized_keys到node2的.ssh目录中去
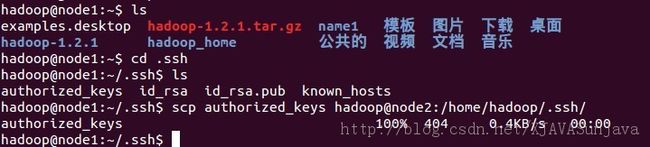
修改已经传输到node2的authorized_keys的许可权限,需要root权限
chmod 644 authorized_keys
ssh node2 #测试无密码访问node2
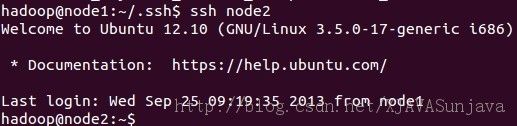
node3同上面的执行步骤
Ubuntu 13.04上搭建Hadoop环境
首先要了解一下Hadoop的运行模式:
单机模式(standalone)
单机模式是Hadoop的默认模式。当首次解压Hadoop的源码包时,Hadoop无法了解硬件安装环境,便保守地选择了最小配置。在这种默认模式下所有3个XML文件均为空。当配置文件为空时,Hadoop会完全运行在本地。因为不需要与其他节点交互,单机模式就不使用HDFS,也不加载任何Hadoop的守护进程。该模式主要用于开发调试MapReduce程序的应用逻辑。
伪分布模式(Pseudo-Distributed Mode)
伪分布模式在“单节点集群”上运行Hadoop,其中所有的守护进程都运行在同一台机器上。该模式在单机模式之上增加了代码调试功能,允许你检查内存使用情况,HDFS输入输出,以及其他的守护进程交互。
全分布模式(Fully Distributed Mode)
Hadoop守护进程运行在一个集群上。
版本:Ubuntu 13.04,Hadoop 1.2.0
1.添加hadoop用户到系统用户
安装前要做一件事——添加一个名为hadoop到系统用户,专门用来做Hadoop测试。
~$ sudo addgroup hadoop
~$ sudo adduser --ingroup hadoop hadoop
现在只是添加了一个用户hadoop,它并不具备管理员权限,因此我们需要将用户hadoop添加到管理员组:
~$ sudo usermod -aG admin hadoop
2、安装JDK
教程很多,参考http://www.linuxidc.com/Linux/2012-11/74189.htm。这里不多说。我安装的是JDK 1.7 64位版本
3.安装ssh
由于Hadoop用ssh通信,先安装ssh
sudo apt-get install openssh-server
ssh安装完成以后,先启动服务:
sudo /etc/init.d/ssh start
启动后,可以通过如下命令查看服务是否正确启动:
ps -e | grep ssh
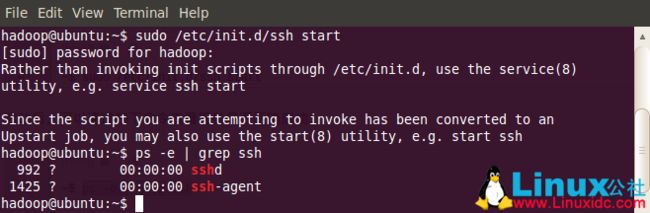
建立ssh无密码登录本机.首先要转换成hadoop用户:
01.su - hadoop
作为一个安全通信协议,使用时需要密码,因此我们要设置成免密码登录,生成私钥和公钥:
hadoop@scgm-ProBook:~$ ssh-keygen -t rsa -P ""
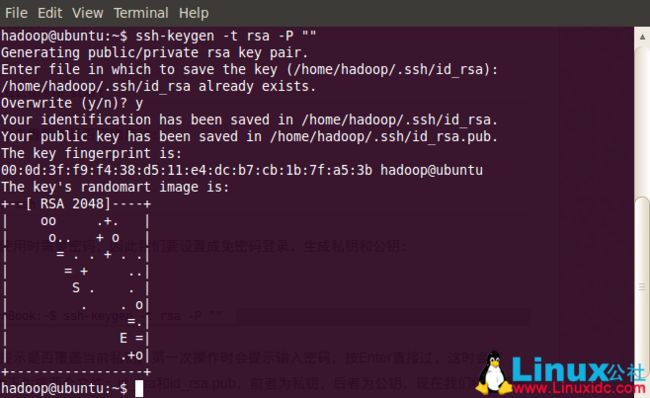
因为我已有私钥,所以会提示是否覆盖当前私钥。第一次操作时会提示输入密码,按Enter直接过,这时会在~/home/{username}/.ssh下生成两个文件:id_rsa和id_rsa.pub,前者为私钥,后者为公钥,现在我们将公钥追加到authorized_keys中(authorized_keys用于保存所有允许以当前用户身份登录到ssh客户端用户的公钥内容):
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
现在可以登入ssh确认以后登录时不用输入密码:
ssh localhost
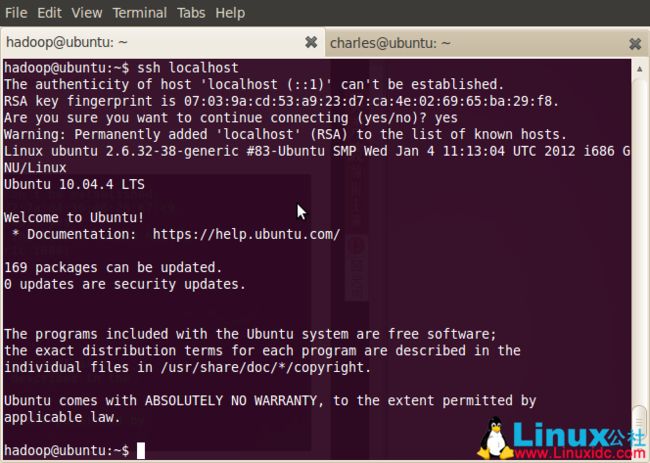
登出:
exit
第二次登录:
ssh localhost
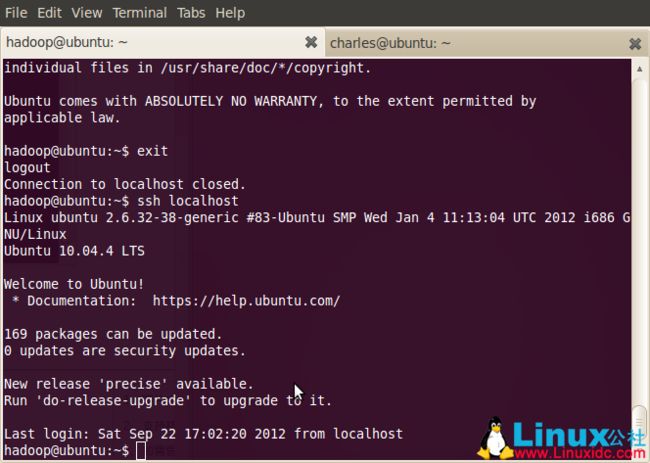
登出:
exit
这样以后登录就不用输入密码了。
Ubuntu上搭建Hadoop环境(单机模式+伪分布模式)
最近一直在自学Hadoop,今天花点时间搭建一个开发环境,并整理成文。
首先要了解一下Hadoop的运行模式:
单机模式(standalone)
单机模式是Hadoop的默认模式。当首次解压Hadoop的源码包时,Hadoop无法了解硬件安装环境,便保守地选择了最小配置。在这种默认模式下所有3个XML文件均为空。当配置文件为空时,Hadoop会完全运行在本地。因为不需要与其他节点交互,单机模式就不使用HDFS,也不加载任何Hadoop的守护进程。该模式主要用于开发调试MapReduce程序的应用逻辑。
伪分布模式(Pseudo-Distributed Mode)
伪分布模式在“单节点集群”上运行Hadoop,其中所有的守护进程都运行在同一台机器上。该模式在单机模式之上增加了代码调试功能,允许你检查内存使用情况,HDFS输入输出,以及其他的守护进程交互。
全分布模式(Fully Distributed Mode)
Hadoop守护进程运行在一个集群上。
版本:Ubuntu 10.04.4,hadoop 1.0.2
1.添加hadoop用户到系统用户
安装前要做一件事——添加一个名为hadoop到系统用户,专门用来做Hadoop测试。
~$ sudo addgroup hadoop
~$ sudo adduser --ingroup hadoop hadoop
现在只是添加了一个用户hadoop,它并不具备管理员权限,因此我们需要将用户hadoop添加到管理员组:
~$ sudo usermod -aG admin hadoop
2.安装ssh
由于Hadoop用ssh通信,先安装ssh
~$ sudo apt-get install openssh-server
ssh安装完成以后,先启动服务:
~$ sudo /etc/init.d/ssh start
启动后,可以通过如下命令查看服务是否正确启动:
~$ ps -e | grep ssh
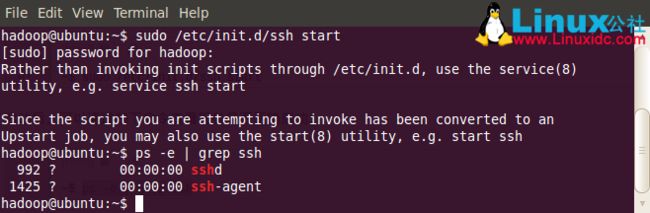
作为一个安全通信协议,使用时需要密码,因此我们要设置成免密码登录,生成私钥和公钥:
hadoop@scgm-ProBook:~$ ssh-keygen -t rsa -P ""

CentOS安装和配置Hadoop2.2.0
Hadoop2.2.0的部署
机器环境:
操作系统:CentOS 6.4 64位系统
Hadoop版本:hadoop-2.2.0,在CentOS下自行编译后的64位版本。
操作步骤:
1.假设共四台机器,每台机器的用户名均设为myhadoop(为了安装配置的方便,另外也是为了权限问题)
机器名 IP地址 分配
hadoop1 10.172.169.191 namenode,ResourceManager
hadoop2 10.172.169.192 datanode,NodeManager
hadoop3 10.172.169.193 datanode , NodeManager
hadoop4 10.172.169.194 datanode , NodeManager
2.每台机器均安装好javajdk并配置好相应的环境变量。要求每台机器的安装路径以及java环境变量设置一致。
3.关闭防火墙
切换到root帐户
开启:chkconfigiptables on
关闭:chkconfigiptables off
重启后永久生效
4.每台都配置/etc/host文件
在root账户下,打开/etc/host文件,添加IP地址解析
hadoop1 10.172.169.191
hadoop2 10.172.169.192
hadoop3 10.172.169.193
hadoop4 10.172.169.194
5.配置ssh无密码登录
(1).在namenode机器上
cd /home/myhadoop
ssh-keygen -t rsa
一路回车
(2).导入公钥到本机认证文件
cat ~/.ssh/id_rsa.pub>>~/.ssh/authorized_keys
(3).导入公钥到其他datanode节点认证文件
scp ~/.ssh/authorized_keys [email protected]:/home/myhadoop/.ssh/authorized_keys
scp ~/.ssh/authorized_keys [email protected]:/home/myhadoop/.ssh/authorized_keys
scp ~/.ssh/authorized_keys [email protected]:/home/myhadoop/.ssh/authorized_keys
(4).修改所有机器上的文件权限
chmod 700 ~/.ssh
chmod 600 ~/.ssh/authorized_keys
(5).测试是否可以ssh无密码登录。
如果namenode可以无密码登录到各个datanode机器,则说明配置成功。