Sqoop导入导出的几个例子
导入
例一:从DBMS到HDFS
1.node4下启动mysql
service mysqld start
mysql -u root -p
输入密码:123
2.node4下创建test数据库
create database test;
创建psn表
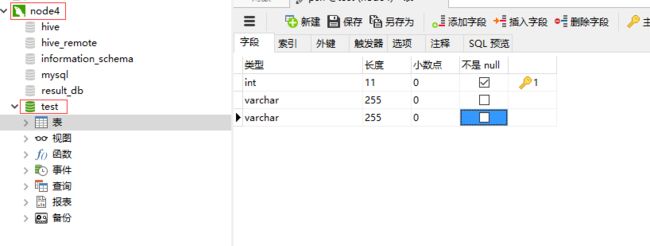
3.node2中创建sqoop_test,编辑sqoop1

import--connectjdbc:mysql://node4/test--usernameroot--password123--as-textfile--columnsid,name,msg--tablepsn--delete-target-dir--target-dir/sqoop/data-m1
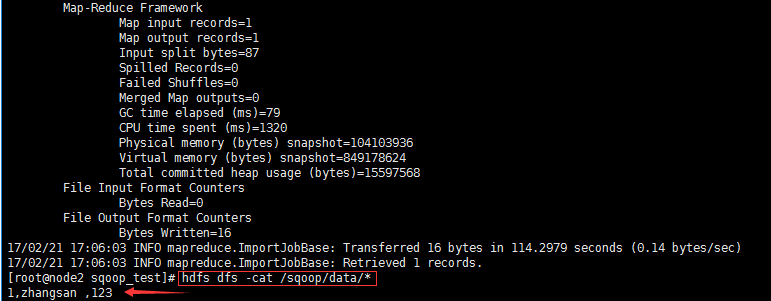
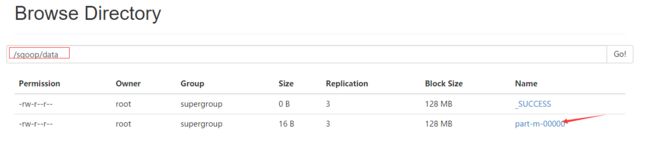
4.执行命令--从DBMS导入到HDFS
sqoop --options-file sqoop1//选项使用脚本
sqoop --options-file sqoop1

例二:从DBMS到Hive
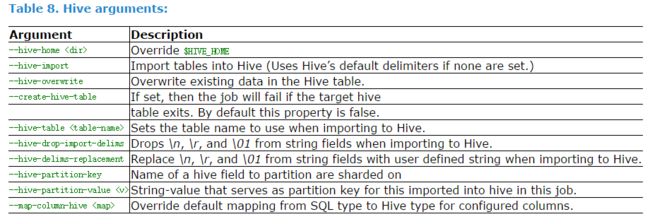
注意!
$CONDITIONS规定
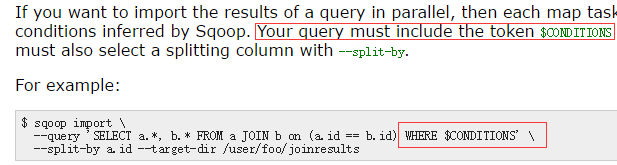
--as-textfile //以文本的方式进行存储
/sqoop/tmp先将数据导入hdfs的临时目录,再将数据导入hive的目录
1.node4下启动mysql
service mysqld start
mysql -u root -p
输入密码:123
2.node4下创建test数据库
create database test;
创建psn表
3.node2中创建sqoop_test,编辑sqoop2
-e,--query和--table两个选项是冲突的,因为一个是指定单表,一个是指定多表的导入;
--warehouse-dir指定导入到hive中的时候到底从哪个目录下面导入;这个选项和hive中的warehouse-dir
配置项很像;
--hive-home指定hive的安装目录,如果节点上面配置了环境变量,并且导入了需要的jar包,那么就不需要
指定了;
sqoop将关系型数据库中的数据导入到hive中去的话,首先需要将数据导入到hdfs上面,因此需要先指定
hdfs上面一个临时存储这些数据的目录,然后才会把hdfs上面的数据导入到hive中去;也就是首先使用mr
到hdfs上面,然后在创建hive的表;可以再打开一个终端,查看hive中的表创建的情况;创建的时候
首先在mysql通过查看表字段,然后在hive中创建;我们没有指定hive表存放在什么位置。这个位置是由
hive的配置文件指定的,需要在那个位置查看;
import--connectjdbc:mysql://node4/test--usernameroot--password123--as-textfile--query'select id, name, msg from psn where id like "1%" and $CONDITIONS'--delete-target-dir-target-dir/sqoop/tmp-m1--hive-home/home/hive-1.2.1--hive-import--create-hive-table--hive-tablet_test
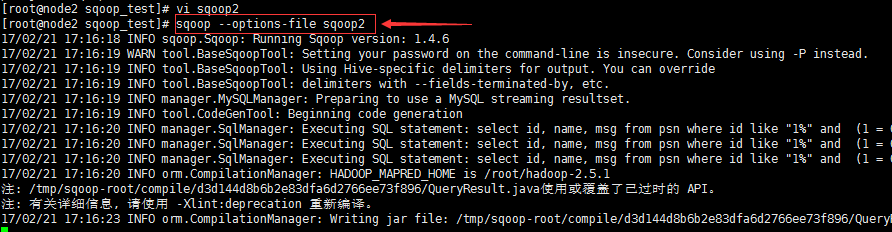
4.执行命令--从DBMS导入到Hive
先启动hive服务端node2: hive --service metastore
再启动hive客户端node1:
hive
sqoop --options-file sqoop2
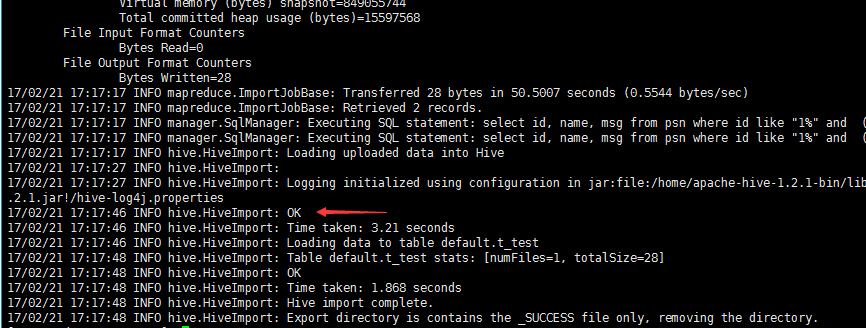
node1查看表t_test是否生成


导出
例三:从HDFS到DBMS
指定HDFS中数据对应的目录
1.node4下启动mysql
service mysqld start
mysql -u root -p
输入密码:123
2.node4下创建test数据库
create database test;
创建h_psn表
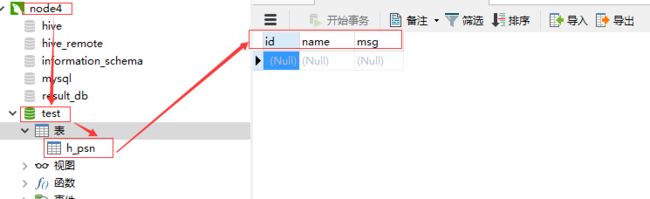
3.node2中创建sqoop_test,编辑sqoop3
export--connectjdbc:mysql://node4/test--usernameroot--password123-m1--columnsid,name,msg--export-dir/sqoop/data--tableh_psn
4.执行sqoop命令
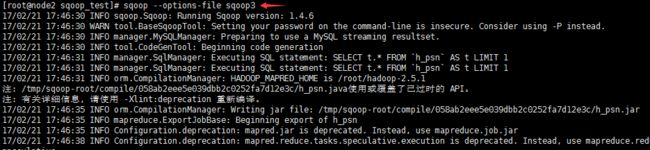
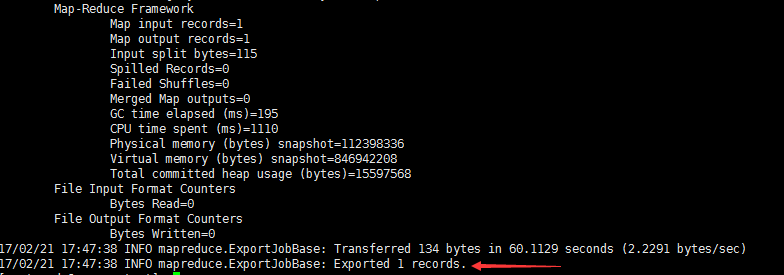
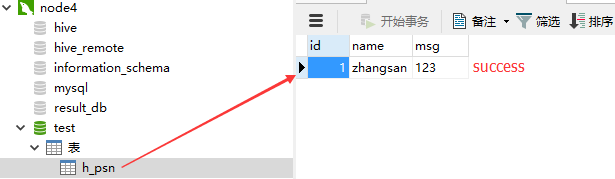
查看mysql中的表,看数据是否导入
例四:从Hive到DBMS

Sqoop的安装非常简单,只需要把下载下来的tar包解压设置两个环境变量就可以了
1.安装部署
下载版本:sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz
官网:http://mirror.bit.edu.cn/apache/sqoop/1.4.6/
1.1把tar包解压到/usr/sqoop
tar -xvzf sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz /usr/ //解压到指定路径
mv sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz sqoop //重命名,可选可不选1.2设置环境变量
把Sqoop添加到PATH文件, vim /etc/profile ,设置
export SQOOP_HOME=/usr/sqoop
export PATH=$PATH:$SQOOP_HOME/bin因为Sqoop需要用到hadoop下面的jar包进行操作,所以需要设置HADOOP_COMMON_HOME 来指明hadoop安装在那个目录下。
[root@srv01 ~]# export HADOOP_COMMON_HOME=/usr/hadoop //指明hadoop安装路径[root@srv01 ~]# export HADOOP_MAPRED_HOME=/usr/hadoop //因为hadoop最终把它的作业转换成mapreduce进行提交执行,实际上和hadoop home目录相同也可以用另一种方式,配置sqoop/conf目录下的sqoop-env.sh
vim sqoop-env.sh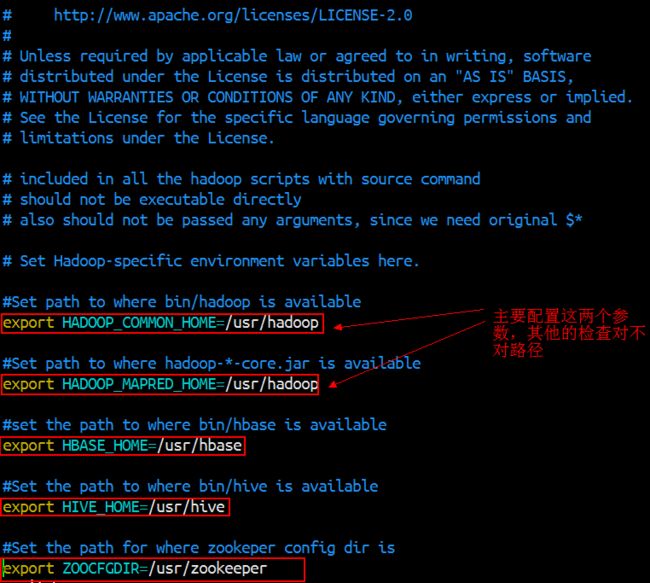
把jdbc驱动包放到sqoop的lib目录下,如果里面有就不需要加(里面有个MySQL驱动包)。
1.3验证安装完成
输入 sqoop help ,如下面所示,表示安装正常,另,没有设置PATH变量的需要到sqoop/bin执行 ./sqoop help
![]()
[root@srv01 ~]# sqoop help
Warning: /usr/sqoop/../hcatalog does not exist! HCatalog jobs will fail.
Please set $HCAT_HOME to the root of your HCatalog installation.
Warning: /usr/sqoop/../accumulo does not exist! Accumulo imports will fail.
Please set $ACCUMULO_HOME to the root of your Accumulo installation.
17/08/12 03:49:43 INFO sqoop.Sqoop: Running Sqoop version: 1.4.6
usage: sqoop COMMAND [ARGS]
Available commands:
codegen Generate code to interact with database records
create-hive-table Import a table definition into Hive
eval Evaluate a SQL statement and display the results
export Export an HDFS directory to a database table
help List available commands
import Import a table from a database to HDFS
import-all-tables Import tables from a database to HDFS
import-mainframe Import datasets from a mainframe server to HDFS
job Work with saved jobs
list-databases List available databases on a server
list-tables List available tables in a database
merge Merge results of incremental imports
metastore Run a standalone Sqoop metastore
version Display version information
See 'sqoop help COMMAND' for information on a specific command.![]()
2.使用Sqoop进行数据迁移
下面通过6个例子展示使用Sqoop进行数据迁移
2.1使用Sqoop导入MySQL数据到HDFS
[root@srv01 ~]# sqoop import --connect jdbc:mysql://localhost:3306/test --username root --password root --table user --columns 'uid,uname' -m 1 -target-dir '/sqoop/user'; //-m 指定map进程数,-target-dir指定存放目录2.2使用Sqoop导入MySQL数据到Hive中
[root@srv01 ~]# sqoop import --hive-import --connect jdbc:mysql://localhost:3306/test --username root --password root --table user --columns 'uid,uname' -m 1 2.3使用Sqoop导入MySQL数据到Hive中,并且指定表名
[root@srv01 ~]# sqoop import --hive-import --connect jdbc:mysql://localhost:3306/test --username root --password root --table user --columns 'uid,uname' -m 1 --hive-table user1; //如果hive中没有这张表,则创建这张表保存对应数据2.4使用Sqoop导入MySQL数据到Hive中,并使用where条件
[root@srv01 ~]# sqoop import --hive-import --connect jdbc:mysql://localhost:3306/test --username root --password root --table user --columns 'uid,uname' -m 1 --hive-table user2 where uid=10;2.5使用Sqoop导入MySQL数据到Hive中,并使用查询语句
[root@srv01 ~]# sqoop import --hive-import --connect jdbc:mysql://localhost:3306/test --username root --password root -m 1 --hive-table user6 --query 'select * from user where uid<10 and $conditions' --target-dir /sqoop/user5;
//and $conditions 必须加在查询语句中,不加报错2.6使用Sqoop将Hive中的数据导出到MySQL中
[root@srv01 ~]# sqoop import --connect jdbc:mysql://localhost:3306/test --username root --password root -m 1 --table user5 --export-dir /sqoop/user5 //两张表的列的个数和类型必须相同
1. 导入实例
1.1 登陆数据库查看表
xiaosi@Qunar:~$ mysql -u root -pEnter password:Welcome to the MySQL monitor. Commands end with ; or \g.Your MySQL connection id is 8Server version: 5.6.30-0ubuntu0.15.10.1-log (Ubuntu)Copyright (c) 2000, 2016, Oracle and/or its affiliates. All rights reserved.Oracle is a registered trademark of Oracle Corporation and/or itsaffiliates. Other names may be trademarks of their respectiveowners.Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.mysql> use test;Reading table information for completion of table and column namesYou can turn off this feature to get a quicker startup with -ADatabase changedmysql> show tables;+-----------------+| Tables_in_test |+-----------------+| employee || hotel_info |+-----------------+
1.2 导入操作
我们选择employee这张表进行导入。
mysql> select * from employee;+--------+---------+-----------------+| name | company | depart |+--------+---------+-----------------+| yoona | qunar | 创新事业部 || xiaosi | qunar | 创新事业部 || jim | ali | 淘宝 || kom | ali | 淘宝 |
导入的命令非常简单,如下:
sqoop import --connect jdbc:mysql://localhost:3306/test --table employee --username root -password root -m 1
上面代码是把test数据库下employee表中数据导入HDFS中,运行结果如下:
16/11/13 16:37:35 INFO mapreduce.Job: The url to track the job: http://localhost:8080/16/11/13 16:37:35 INFO mapreduce.Job: Running job: job_local976138588_000116/11/13 16:37:35 INFO mapred.LocalJobRunner: OutputCommitter set in config null16/11/13 16:37:35 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 116/11/13 16:37:35 INFO mapred.LocalJobRunner: OutputCommitter is org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter16/11/13 16:37:35 INFO mapred.LocalJobRunner: Waiting for map tasks16/11/13 16:37:35 INFO mapred.LocalJobRunner: Starting task: attempt_local976138588_0001_m_000000_016/11/13 16:37:35 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 116/11/13 16:37:35 INFO mapred.Task: Using ResourceCalculatorProcessTree : [ ]16/11/13 16:37:35 INFO db.DBInputFormat: Using read commited transaction isolation16/11/13 16:37:35 INFO mapred.MapTask: Processing split: 1=1 AND 1=116/11/13 16:37:35 INFO db.DBRecordReader: Working on split: 1=1 AND 1=116/11/13 16:37:35 INFO db.DBRecordReader: Executing query: SELECT `name`, `company`, `depart` FROM `employee` AS `employee` WHERE ( 1=1 ) AND ( 1=1 )16/11/13 16:37:35 INFO mapreduce.AutoProgressMapper: Auto-progress thread is finished. keepGoing=false16/11/13 16:37:35 INFO mapred.LocalJobRunner:16/11/13 16:37:35 INFO mapred.Task: Task:attempt_local976138588_0001_m_000000_0 is done. And is in the process of committing16/11/13 16:37:35 INFO mapred.LocalJobRunner:16/11/13 16:37:35 INFO mapred.Task: Task attempt_local976138588_0001_m_000000_0 is allowed to commit now16/11/13 16:37:35 INFO output.FileOutputCommitter: Saved output of task 'attempt_local976138588_0001_m_000000_0' to hdfs://localhost:9000/user/xiaosi/employee/_temporary/0/task_local976138588_0001_m_00000016/11/13 16:37:35 INFO mapred.LocalJobRunner: map16/11/13 16:37:35 INFO mapred.Task: Task 'attempt_local976138588_0001_m_000000_0' done.16/11/13 16:37:35 INFO mapred.LocalJobRunner: Finishing task: attempt_local976138588_0001_m_000000_016/11/13 16:37:35 INFO mapred.LocalJobRunner: map task executor complete.16/11/13 16:37:36 INFO mapreduce.Job: Job job_local976138588_0001 running in uber mode : false16/11/13 16:37:36 INFO mapreduce.Job: map 100% reduce 0%16/11/13 16:37:36 INFO mapreduce.Job: Job job_local976138588_0001 completed successfully16/11/13 16:37:36 INFO mapreduce.Job: Counters: 20File System CountersFILE: Number of bytes read=22247770FILE: Number of bytes written=22733107FILE: Number of read operations=0FILE: Number of large read operations=0FILE: Number of write operations=0HDFS: Number of bytes read=0HDFS: Number of bytes written=120HDFS: Number of read operations=4HDFS: Number of large read operations=0HDFS: Number of write operations=3Map-Reduce FrameworkMap input records=6Map output records=6Input split bytes=87Spilled Records=0Failed Shuffles=0Merged Map outputs=0GC time elapsed (ms)=0Total committed heap usage (bytes)=241696768File Input Format CountersBytes Read=0File Output Format CountersBytes Written=12016/11/13 16:37:36 INFO mapreduce.ImportJobBase: Transferred 120 bytes in 2.4312 seconds (49.3584 bytes/sec)16/11/13 16:37:36 INFO mapreduce.ImportJobBase: Retrieved 6 records.
是不是很眼熟,这就是MapReduce作业的输出日志,说明Sqoop导入数据是通过MapReduce作业完成的,并且是没有Reduce任务的MapReduce。为了验证是否导入成功,查看HDFS的目录,执行如下命令:
xiaosi@Qunar:/opt/hadoop-2.7.2/sbin$ hadoop fs -ls /user/xiaosiFound 2 itemsdrwxr-xr-x - xiaosi supergroup 0 2016-10-26 16:16 /user/xiaosi/datadrwxr-xr-x - xiaosi supergroup 0 2016-11-13 16:37 /user/xiaosi/employee
我们发现多出了一个目录,目录名称正好是表名employee,继续查看目录,会发现有两个文件:
xiaosi@Qunar:/opt/hadoop-2.7.2/sbin$ hadoop fs -ls /user/xiaosi/employeeFound 2 items-rw-r--r-- 1 xiaosi supergroup 0 2016-11-13 16:37 /user/xiaosi/employee/_SUCCESS-rw-r--r-- 1 xiaosi supergroup 120 2016-11-13 16:37 /user/xiaosi/employee/part-m-00000
其中,_SUCCESS是代表作业成功的标志文件,输出结果是part-m-00000文件(有可能会输出_logs文件,记录了作业日志)。查看输出文件内容:
yoona,qunar,创新事业部xiaosi,qunar,创新事业部jim,ali,淘宝kom,ali,淘宝lucy,baidu,搜索jim,ali,淘宝
Sqoop导出的数据文件变成了CSV文件(逗号分割)。这时,如果查看执行Sqoop命令的当前文件夹,会发现多了一个employee.java文件,这是Sqoop自动生成的Java源文件。
xiaosi@Qunar:/opt/sqoop-1.4.6/bin$ ll总用量 116drwxr-xr-x 2 root root 4096 11月 13 16:36 ./drwxr-xr-x 9 root root 4096 4月 27 2015 ../-rwxr-xr-x 1 root root 6770 4月 27 2015 configure-sqoop*-rwxr-xr-x 1 root root 6533 4月 27 2015 configure-sqoop.cmd*-rw-r--r-- 1 root root 12543 11月 13 16:32 employee.java-rwxr-xr-x 1 root root 800 4月 27 2015 .gitignore*-rwxr-xr-x 1 root root 3133 4月 27 2015 sqoop*-rwxr-xr-x 1 root root 1055 4月 27 2015 sqoop.cmd*-rwxr-xr-x 1 root root 950 4月 27 2015 sqoop-codegen*-rwxr-xr-x 1 root root 960 4月 27 2015 sqoop-create-hive-table*-rwxr-xr-x 1 root root 947 4月 27 2015 sqoop-eval*-rwxr-xr-x 1 root root 949 4月 27 2015 sqoop-export*-rwxr-xr-x 1 root root 947 4月 27 2015 sqoop-help*-rwxr-xr-x 1 root root 949 4月 27 2015 sqoop-import*-rwxr-xr-x 1 root root 960 4月 27 2015 sqoop-import-all-tables*-rwxr-xr-x 1 root root 959 4月 27 2015 sqoop-import-mainframe*-rwxr-xr-x 1 root root 946 4月 27 2015 sqoop-job*-rwxr-xr-x 1 root root 957 4月 27 2015 sqoop-list-databases*-rwxr-xr-x 1 root root 954 4月 27 2015 sqoop-list-tables*-rwxr-xr-x 1 root root 948 4月 27 2015 sqoop-merge*-rwxr-xr-x 1 root root 952 4月 27 2015 sqoop-metastore*-rwxr-xr-x 1 root root 950 4月 27 2015 sqoop-version*-rwxr-xr-x 1 root root 3987 4月 27 2015 start-metastore.sh*-rwxr-xr-x 1 root root 1564 4月 27 2015 stop-metastore.sh*
查看源文件看到employee类实现了Writable接口,表名该类的作用是序列化和反序列化,并且该类的属性包含了employee表中的所有字段,所以该类可以存储employee表中的一条记录。
public class employee extends SqoopRecord implements DBWritable, Writable {private final int PROTOCOL_VERSION = 3;public int getClassFormatVersion() { return PROTOCOL_VERSION; }protected ResultSet __cur_result_set;private String name;public String get_name() {return name;}public void set_name(String name) {this.name = name;}public employee with_name(String name) {this.name = name;return this;}private String company;public String get_company() {return company;}public void set_company(String company) {this.company = company;}public employee with_company(String company) {this.company = company;return this;}private String depart;public String get_depart() {return depart;}public void set_depart(String depart) {this.depart = depart;}public employee with_depart(String depart) {this.depart = depart;return this;}public boolean equals(Object o) {if (this == o) {return true;}if (!(o instanceof employee)) {return false;}employee that = (employee) o;boolean equal = true;equal = equal && (this.name == null ? that.name == null : this.name.equals(that.name));equal = equal && (this.company == null ? that.company == null : this.company.equals(that.company));equal = equal && (this.depart == null ? that.depart == null : this.depart.equals(that.depart));return equal;}
2. 导入过程
从前面的样例大致了解到Sqoop是通过MapReducer作业进行导入工作,在做作业中,会从表中读取一行行的记录,然后将其写入HDFS中。

(1)第一步,Sqoop会通过JDBC来获取所需要的数据库元数据,例如,导入表的列名,数据类型等。
(2)第二步,这些数据库的数据类型(varchar, number等)会被映射成Java的数据类型(String, int等),根据这些信息,Sqoop会生成一个与表名同名的类用来完成反序列化工作,保存表中的每一行记录。
(3)第三步,Sqoop启动MapReducer作业
(4)第四步,启动的作业在input的过程中,会通过JDBC读取数据表中的内容,这时,会使用Sqoop生成的类进行反序列化操作
(5)第五步,最后将这些记录写到HDFS中,在写入到HDFS的过程中,同样会使用Sqoop生成的类进行序列化
如上图所示,Sqoop的导入作业通常不只是由一个Map任务完成,也就是说每个任务会获取表的一部分数据,如果只由一个Map任务完成导入的话,那么在第四步时,作业会通过JDBC执行如下SQL:
select col1, col2,... From table;
这样就能获取表的全部数据,如果由多个Map任务来完成,那就必须对表进行水平切分,水平切分的依据通常会是表的主键。Sqoop在启动MapReducer作业时,会首先通过JDBC查询切分列的最大值和最小值,在根据启动任务数(使用-m命令指定)划分出每个任务所负责的数据,实质上在第四步时,每个任务执行的SQL为:
select col1, col2,... From table WHERE id > 0 AND id < 50000;select col1, col2,... From table WHERE id > 5000 AND id < 100000;...
使用sqoop进行并行导入的话,切分列的数据分布会很大程度上会影响性能,如果在均匀分布的情况下,性能最好。在最坏的情况下,数据严重倾斜,所有数据都集中在某一个切分区中,那么此时的性能与串行导入性能没有差别,所以在导入之前,有必要对切分列的数据进行抽样检测,了解数据的分布。
Sqoop可以对导入过程进行精细的控制,不用每次都导入一个表的所有字段。Sqoop允许我们指定表的列,在查询中加入WHERE子句,甚至可以自定义查询SQL语句,并且在SQL语句中,可以任意使用目标数据库所支持的函数。
在开始的例子中,我们导入的数据存放到了HDFS中,将这份数据导入Hive之前,必须在Hive中创建该表,Sqoop提供了相应的命令:
sqoop create-hive-table --connect jdbc:mysql://localhost:3306/test --table employee --username root -password root --fields-terminated-by ','
3. 导出实例
与Sqoop导入功能相比,Sqoop的导出功能使用频率相对较低,一般都是将Hive的分析结果导出到关系数据库中以供数据分析师查看,生成报表等。
在将Hive中表导出到数据库时,必须在数据库中新建一张来接受数据的表,需要导出的Hive表为order_info,如下:
hive (test)> desc order_info;OKuid stringorder_time stringbusiness stringTime taken: 0.096 seconds, Fetched: 3 row(s)
我们在mysql中新建一张用于接受数据的表,如下:
mysql> create table order_info(id varchar(50), order_time varchar(20), business varchar(10));Query OK, 0 rows affected (0.09 sec)
备注:
在Hive中,字符串数据类型为String类型,但在关系性数据库中,有可能是varchar(10),varchar(20),这些必须根据情况自己指定,这也是必须由用户事先将表创建好的原因。
接下来,执行导入操作,执行命令如下:
sqoop export --connect jdbc:mysql://localhost:3306/test --table order_info --export-dir /user/hive/warehouse/test.db/order_info --username root -password root -m 1 --fields-terminated-by '\t'
对于上面这条导出命令,--connect,--table和--export-dir这三个选项是必须的。其中,export-dir为导出表的HDFS路径,同时将Hive表的列分隔符通过--fields-terminated-by告知Sqoop。上面代码是把Hive的test数据库下ordedr_info表中数据导入mysql中,运行结果如下:
16/11/13 19:21:43 INFO mapreduce.Job: The url to track the job: http://localhost:8080/16/11/13 19:21:43 INFO mapreduce.Job: Running job: job_local1384135708_000116/11/13 19:21:43 INFO mapred.LocalJobRunner: OutputCommitter set in config null16/11/13 19:21:43 INFO mapred.LocalJobRunner: OutputCommitter is org.apache.sqoop.mapreduce.NullOutputCommitter16/11/13 19:21:43 INFO mapred.LocalJobRunner: Waiting for map tasks16/11/13 19:21:43 INFO mapred.LocalJobRunner: Starting task: attempt_local1384135708_0001_m_000000_016/11/13 19:21:43 INFO mapred.Task: Using ResourceCalculatorProcessTree : [ ]16/11/13 19:21:43 INFO mapred.MapTask: Processing split: Paths:/user/hive/warehouse/test.db/order_info/order.txt:0+378516/11/13 19:21:43 INFO Configuration.deprecation: map.input.file is deprecated. Instead, use mapreduce.map.input.file16/11/13 19:21:43 INFO Configuration.deprecation: map.input.start is deprecated. Instead, use mapreduce.map.input.start16/11/13 19:21:43 INFO Configuration.deprecation: map.input.length is deprecated. Instead, use mapreduce.map.input.length16/11/13 19:21:43 INFO mapreduce.AutoProgressMapper: Auto-progress thread is finished. keepGoing=false16/11/13 19:21:43 INFO mapred.LocalJobRunner:16/11/13 19:21:43 INFO mapred.Task: Task:attempt_local1384135708_0001_m_000000_0 is done. And is in the process of committing16/11/13 19:21:43 INFO mapred.LocalJobRunner: map16/11/13 19:21:43 INFO mapred.Task: Task 'attempt_local1384135708_0001_m_000000_0' done.16/11/13 19:21:43 INFO mapred.LocalJobRunner: Finishing task: attempt_local1384135708_0001_m_000000_016/11/13 19:21:43 INFO mapred.LocalJobRunner: map task executor complete.16/11/13 19:21:44 INFO mapreduce.Job: Job job_local1384135708_0001 running in uber mode : false16/11/13 19:21:44 INFO mapreduce.Job: map 100% reduce 0%16/11/13 19:21:44 INFO mapreduce.Job: Job job_local1384135708_0001 completed successfully16/11/13 19:21:44 INFO mapreduce.Job: Counters: 20File System CountersFILE: Number of bytes read=22247850FILE: Number of bytes written=22734115FILE: Number of read operations=0FILE: Number of large read operations=0FILE: Number of write operations=0HDFS: Number of bytes read=3791HDFS: Number of bytes written=0HDFS: Number of read operations=12HDFS: Number of large read operations=0HDFS: Number of write operations=0Map-Reduce FrameworkMap input records=110Map output records=110Input split bytes=151Spilled Records=0Failed Shuffles=0Merged Map outputs=0GC time elapsed (ms)=0Total committed heap usage (bytes)=226492416File Input Format CountersBytes Read=0File Output Format CountersBytes Written=016/11/13 19:21:44 INFO mapreduce.ExportJobBase: Transferred 3.7021 KB in 2.3262 seconds (1.5915 KB/sec)16/11/13 19:21:44 INFO mapreduce.ExportJobBase: Exported 110 records.
导出完毕之后,我们可以在mysql中通过order_info表进行查询:
mysql> select * from order_info limit 5;+-----------------+------------+----------+| id | order_time | business |+-----------------+------------+----------+| 358574046793404 | 2016-04-05 | flight || 358574046794733 | 2016-08-03 | hotel || 358574050631177 | 2016-05-08 | vacation || 358574050634213 | 2015-04-28 | train || 358574050634692 | 2016-04-05 | tuan |+-----------------+------------+----------+5 rows in set (0.00 sec)
4. 导出过程
其实在了解了导入过程后,导出过程就变的更容易理解了,如下图所示:

同样,Sqoop根据目标表(数据库)的结构会生成一个Java类(第一步和第二步),该类的作用为序列化和反序列化。接着会启动一个MapReduce作业(第三步),在作业中会用生成的Java类从HDFS中读取数据(第四步),并生成一批INSERT语句,每条语句对会向mysql的目标表插入多条数据(第五步),这样读入的时候是并行的,写入的时候也是并行的,但是其写入性能会受限于目标数据库的写入性能。
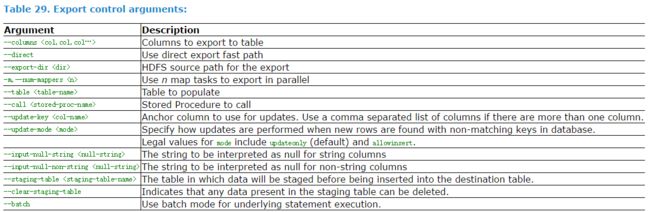
工具通用选项
import和export工具有些通用的选项,如下表所示:
| 选项 | 含义说明 |
--connect |
指定JDBC连接字符串 |
--connection-manager |
指定要使用的连接管理器类 |
--driver |
指定要使用的JDBC驱动类 |
--hadoop-mapred-home |
指定$HADOOP_MAPRED_HOME路径 |
--help |
打印用法帮助信息 |
--password-file |
设置用于存放认证的密码信息文件的路径 |
-P |
从控制台读取输入的密码 |
--password |
设置认证密码 |
--username |
设置认证用户名 |
--verbose |
打印详细的运行信息 |
--connection-param-file |
可选,指定存储数据库连接参数的属性文件 |
数据导入工具import
import工具,是将HDFS平台外部的结构化存储系统中的数据导入到Hadoop平台,便于后续分析。我们先看一下import工具的基本选项及其含义,如下表所示:
| 选项 | 含义说明 |
--append |
将数据追加到HDFS上一个已存在的数据集上 |
--as-avrodatafile |
将数据导入到Avro数据文件 |
--as-sequencefile |
将数据导入到SequenceFile |
--as-textfile |
将数据导入到普通文本文件(默认) |
--boundary-query |
边界查询,用于创建分片(InputSplit) |
--columns |
从表中导出指定的一组列的数据 |
--delete-target-dir |
如果指定目录存在,则先删除掉 |
--direct |
使用直接导入模式(优化导入速度) |
--direct-split-size |
分割输入stream的字节大小(在直接导入模式下) |
--fetch-size |
从数据库中批量读取记录数 |
--inline-lob-limit |
设置内联的LOB对象的大小 |
-m,--num-mappers |
使用n个map任务并行导入数据 |
-e,--query |
导入的查询语句 |
--split-by |
指定按照哪个列去分割数据 |
--table |
导入的源表表名 |
--target-dir |
导入HDFS的目标路径 |
--warehouse-dir |
HDFS存放表的根路径 |
--where |
指定导出时所使用的查询条件 |
-z,--compress |
启用压缩 |
--compression-codec |
指定Hadoop的codec方式(默认gzip) |
--null-string |
果指定列为字符串类型,使用指定字符串替换值为null的该类列的值 |
--null-non-string |
如果指定列为非字符串类型,使用指定字符串替换值为null的该类列的值 |
下面,我们通过实例来说明,在实际中如何使用这些选项。
- 将MySQL数据库中整个表数据导入到Hive表
1bin/sqoopimport--connect jdbc:mysql://10.95.3.49:3306/workflow --table project --username shirdrn -P --hive-import-- --default-character-set=utf-8将MySQL数据库workflow中project表的数据导入到Hive表中。
- 将MySQL数据库中多表JION后的数据导入到HDFS
1bin/sqoopimport--connect jdbc:mysql://10.95.3.49:3306/workflow --username shirdrn -P --query'SELECT users.*, tags.tag FROM users JOIN tags ON (users.id = tags.user_id) WHERE $CONDITIONS'--split-byusers.id--target-dir/hive/tag_db/user_tags -- --default-character-set=utf-8这里,使用了
--query选项,不能同时与--table选项使用。而且,变量$CONDITIONS必须在WHERE语句之后,供Sqoop进程运行命令过程中使用。上面的--target-dir指向的其实就是Hive表存储的数据目录。
- 将MySQL数据库中某个表的数据增量同步到Hive表
1bin/sqoop job --create your-sync-job --import--connect jdbc:mysql://10.95.3.49:3306/workflow --table project --username shirdrn -P --hive-import--incremental append --check-columnid--last-value 1 -- --default-character-set=utf-8这里,每次运行增量导入到Hive表之前,都要修改
--last-value的值,否则Hive表中会出现重复记录。
- 将MySQL数据库中某个表的几个字段的数据导入到Hive表
1bin/sqoopimport--connect jdbc:mysql://10.95.3.49:3306/workflow --username shirdrn --P --table tags --columns'id,tag'--create-hive-table -target-dir/hive/tag_db/tags -m 1 --hive-table tags --hive-import-- --default-character-set=utf-8我们这里将MySQL数据库workflow中tags表的id和tag字段的值导入到Hive表tag_db.tags。其中
--create-hive-table选项会自动创建Hive表,--hive-import选项会将选择的指定列的数据导入到Hive表。如果在Hive中通过SHOW TABLES无法看到导入的表,可以在conf/hive-site.xml中显式修改如下配置选项:1<property>2<name>javax.jdo.option.ConnectionURLname>3<value>jdbc:derby:;databaseName=hive_metastore_db;create=truevalue>4property>然后再重新运行,就能看到了。
- 使用验证配置选项
1sqoopimport--connect jdbc:mysql://db.foo.com/corp --table EMPLOYEES --validate --validator org.apache.sqoop.validation.RowCountValidator --validation-threshold org.apache.sqoop.validation.AbsoluteValidationThreshold --validation-failurehandler org.apache.sqoop.validation.AbortOnFailureHandler上面这个是官方用户手册上给出的用法,我们在实际中还没用过这个,有感兴趣的可以验证尝试一下。
数据导出工具export
export工具,是将HDFS平台的数据,导出到外部的结构化存储系统中,可能会为一些应用系统提供数据支持。我们看一下export工具的基本选项及其含义,如下表所示:
| 选项 | 含义说明 |
--validate |
启用数据副本验证功能,仅支持单表拷贝,可以指定验证使用的实现类 |
--validation-threshold |
指定验证门限所使用的类 |
--direct |
使用直接导出模式(优化速度) |
--export-dir |
导出过程中HDFS源路径 |
-m,--num-mappers |
使用n个map任务并行导出 |
--table |
导出的目的表名称 |
--call |
导出数据调用的指定存储过程名 |
--update-key |
更新参考的列名称,多个列名使用逗号分隔 |
--update-mode |
指定更新策略,包括:updateonly(默认)、allowinsert |
--input-null-string |
使用指定字符串,替换字符串类型值为null的列 |
--input-null-non-string |
使用指定字符串,替换非字符串类型值为null的列 |
--staging-table |
在数据导出到数据库之前,数据临时存放的表名称 |
--clear-staging-table |
清除工作区中临时存放的数据 |
--batch |
使用批量模式导出 |
下面,我们通过实例来说明,在实际中如何使用这些选项。这里,我们主要结合一个实例,讲解如何将Hive中的数据导入到MySQL数据库。
首先,我们准备几个表,MySQL数据库为tag_db,里面有两个表,定义如下所示:
01 |
CREATE TABLE tag_db.users ( |
02 |
id INT(11) NOT NULL AUTO_INCREMENT, |
03 |
name VARCHAR(100) NOT NULL, |
04 |
PRIMARY KEY (`id`) |
05 |
) ENGINE=InnoDB DEFAULT CHARSET=utf8; |
06 |
07 |
CREATE TABLE tag_db.tags ( |
08 |
id INT(11) NOT NULL AUTO_INCREMENT, |
09 |
user_id INT NOT NULL, |
10 |
tag VARCHAR(100) NOT NULL, |
11 |
PRIMARY KEY (`id`) |
12 |
) ENGINE=InnoDB DEFAULT CHARSET=utf8; |
这两个表中存储的是基础数据,同时对应着Hive中如下两个表:
01 |
CREATE TABLE users ( |
02 |
id INT, |
03 |
name STRING |
04 |
); |
05 |
06 |
CREATE TABLE tags ( |
07 |
id INT, |
08 |
user_id INT, |
09 |
tag STRING |
10 |
); |
我们首先在上述MySQL的两个表中插入一些测试数据:
1 |
INSERT INTO tag_db.users(name) VALUES('jeffery'); |
2 |
INSERT INTO tag_db.users(name) VALUES('shirdrn'); |
3 |
INSERT INTO tag_db.users(name) VALUES('sulee'); |
4 |
5 |
INSERT INTO tag_db.tags(user_id, tag) VALUES(1, 'Music'); |
6 |
INSERT INTO tag_db.tags(user_id, tag) VALUES(1, 'Programming'); |
7 |
INSERT INTO tag_db.tags(user_id, tag) VALUES(2, 'Travel'); |
8 |
INSERT INTO tag_db.tags(user_id, tag) VALUES(3, 'Sport'); |
然后,使用Sqoop的import工具,将MySQL两个表中的数据导入到Hive表,执行如下命令行:
1 |
bin/sqoop import --connect jdbc:mysql://10.95.3.49:3306/tag_db --table users --username shirdrn -P --hive-import -- --default-character-set=utf-8 |
2 |
bin/sqoop import --connect jdbc:mysql://10.95.3.49:3306/tag_db --table tags --username shirdrn -P --hive-import -- --default-character-set=utf-8 |
导入成功以后,再在Hive中创建一个用来存储users和tags关联后数据的表:
1 |
CREATE TABLE user_tags ( |
2 |
id STRING, |
3 |
name STRING, |
4 |
tag STRING |
5 |
); |
执行如下HQL语句,将关联数据插入user_tags表:
1 |
FROM users u JOIN tags t ON u.id=t.user_id INSERT INTO TABLE user_tags SELECT CONCAT(CAST(u.idAS STRING), CAST(t.id AS STRING)), u.name, t.tag; |
将users.id与tags.id拼接的字符串,作为新表的唯一字段id,name是用户名,tag是标签名称。
再在MySQL中创建一个对应的user_tags表,如下所示:
1 |
CREATE TABLE tag_db.user_tags ( |
2 |
id varchar(200) NOT NULL, |
3 |
name varchar(100) NOT NULL, |
4 |
tag varchar(100) NOT NULL |
5 |
); |
使用Sqoop的export工具,将Hive表user_tags的数据同步到MySQL表tag_db.user_tags中,执行如下命令行:
1 |
bin/sqoop export --connect jdbc:mysql://10.95.3.49:3306/tag_db --username shirdrn --P --table user_tags --export-dir /hive/user_tags --input-fields-terminated-by '\001' -- --default-character-set=utf-8 |
执行导出成功后,可以在MySQL的tag_db.user_tags表中看到对应的数据。
如果在导出的时候出现类似如下的错误:
01 |
14/02/27 17:59:06 INFO mapred.JobClient: Task Id : attempt_201402260008_0057_m_000001_0, Status : FAILED |
02 |
java.io.IOException: Can't export data, please check task tracker logs |
03 |
at org.apache.sqoop.mapreduce.TextExportMapper.map(TextExportMapper.java:112) |
04 |
at org.apache.sqoop.mapreduce.TextExportMapper.map(TextExportMapper.java:39) |
05 |
at org.apache.hadoop.mapreduce.Mapper.run(Mapper.java:145) |
06 |
at org.apache.sqoop.mapreduce.AutoProgressMapper.run(AutoProgressMapper.java:64) |
07 |
at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:764) |
08 |
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:364) |
09 |
at org.apache.hadoop.mapred.Child$4.run(Child.java:255) |
10 |
at java.security.AccessController.doPrivileged(Native Method) |
11 |
at javax.security.auth.Subject.doAs(Subject.java:396) |
12 |
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1190) |
13 |
at org.apache.hadoop.mapred.Child.main(Child.java:249) |
14 |
Caused by: java.util.NoSuchElementException |
15 |
at java.util.AbstractList$Itr.next(AbstractList.java:350) |
16 |
at user_tags.__loadFromFields(user_tags.java:225) |
17 |
at user_tags.parse(user_tags.java:174) |
18 |
at org.apache.sqoop.mapreduce.TextExportMapper.map(TextExportMapper.java:83) |
19 |
... 10 more |
通过指定字段分隔符选项--input-fields-terminated-by,指定Hive中表字段之间使用的分隔符,供Sqoop读取解析,就不会报错了。
mysql数据导入导出到hdfs
mysql导入到hdfs bin/sqoop help import 查看帮助bin/sqoop import \--connect jdbc:mysql://hadoop-senior0.ibeifeng.com:3306/study \--username root \--password 123456 \--table my_user \--target-dir /output1 \--query 'select id, account from my_user where $CONDITIONS' \--num-mappers 1 \--as-parquetfile如果没有指定路径会默认存储在/user/beifeng/下面即是用户主目录==============================================================hdfs导出到mysql bin/sqoop help export help查看帮助bin/sqoop export \--connect jdbc:mysql://hadoop-senior.ibeifeng.com:3306/test \--username root \--password 123456 \--table my_user \--export-dir /user/beifeng/sqoop/exp/user/ \--num-mappers 1导出的目录下的文件要以逗号分隔,因为mysql表默认是以逗号分隔的,或者加上一个参数指定输出分隔符,就会以指定的分隔符来区分不同的字段;导出到mysql中的表是已存在的
mysql数据导入导出到hive
bin/sqoop import \--connect jdbc:mysql://hadoop-senior.ibeifeng.com:3306/test \--username root \--password 123456 \--table my_user \--fields-terminated-by '\t' \--delete-target-dir \--num-mappers 1 \--hive-import \--hive-database default \--hive-table user_hive实质上是首先导入数据到hdfs上,然后用一个load语句加载数据到hive===============================================================bin/sqoop export \--connect jdbc:mysql://hadoop-senior.ibeifeng.com:3306/test \--username root \--password 123456 \--table my_user2 \--export-dir /user/hive/warehouse/user_hive \--num-mappers 1 \--input-fields-terminated-by '\t'
二. hive数据导入导出数据到mysql
[plain] view plain copy
- sqoop export -connect jdbc:mysql://localhost:3306/sqoop
- -username root -password hadoop -table hive_student -export-dir
- /hive/student/student --input-fields-terminated-by '\t'
三.mysql数据库数据导入hive中
[plain] view plain copy
- sqoop import --connect jdbc:mysql://localhost:3306/sqoop
- -username root -password hadoop -table test -hive-import -m 1
三.hbase与关系型数据库数据互导
从Mysql导入到Hbase中
参数说明:
test 为mysql中要传入到hbase表中的表名。
mysql_sqoop_test 传入hbase中的表名
--column-family hbase表中的列族
--hbase-row-key 在hbase中那一列作为rowkey
使用范例:
[plain] view plain copy
- sqoop import --connect jdbc:mysql://10.120.10.11:3306/sqoop
- --username sqoop --password sqoop --table test --hbase-create-table
- --hbase-table mysql_sqoop_test --column-family info --hbase-row-key id -m 1
前提:安装好 sqoop、hbase。
下载jbdc驱动:mysql-connector-java-5.1.10.jar
将 mysql-connector-java-5.1.10.jar 复制到 /usr/lib/sqoop/lib/ 下
MySQL导入HBase命令:
sqoop import --connect jdbc:mysql://10.10.97.116:3306/rsearch --table researchers --hbase-table A --column-family person --hbase-row-key id --hbase-create-table --username 'root' -P
说明:
--connect jdbc:mysql://10.10.97.116:3306/rsearch 表示远程或者本地 Mysql 服务的URI,3306是Mysql默认监听端口,rsearch是数据库,若是其他数据库,如Oracle,只需修改URI即可。
--table researchers 表示导出rsearch数据库的researchers表。
--hbase-table A 表示在HBase中建立表A。
--column-family person 表示在表A中建立列族person。
--hbase-row-key id 表示表A的row-key是researchers表的id字段。
--hbase-create-table 表示在HBase中建立表。
--username 'root' 表示使用用户root连接Mysql。
注意:
HBase的所有节点必须能够访问MySQL数据库,不然会出现如下错误:
java.sql.SQLException: null, message from server: "Host '10.10.104.3' is not allowed to connect to this MySQL server"
[plain] view plain copy
- 在MySQL数据库服务器节点上执行以下命令允许远程机器使用相应用户访问本地数据库服务器:
- [root@gc01vm6 htdocs] # /opt/lampp/bin/mysql
- mysql> use mysql;
- Database changed
- mysql> GRANT ALL PRIVILEGES ON rsearch.* TO 'root'@'10.10.104.3' IDENTIFIED BY '' WITH GRANT OPTION;
- mysql> GRANT ALL PRIVILEGES ON rsearch.* TO 'root'@'10.10.104.5' IDENTIFIED BY '' WITH GRANT OPTION;
- mysql> GRANT ALL PRIVILEGES ON rsearch.* TO 'root'@'10.10.104.2' IDENTIFIED BY '' WITH GRANT OPTION;
这里10.10.104.2,10.10.104.3,10.10.104.5 是HBase节点。
一、使用Sqoop将MySQL中的数据导入到HDFS/Hive/HBase


二、使用Sqoop将HDFS/Hive/HBase中的数据导出到MySQL

2.3 HBase中的数据导出到mysql
目前没有直接的命令将HBase中的数据导出到MySQL,但可以先将HBase中的数据导出到HDFS中,再将数据导出到MySQL。
三、使用Sqoop将Oracle中的数据导入到HDFS/Hive/HBase
下面只给出将Oracle中的数据导入HBase,其他情况下的命令行选项与MySQL的操作相似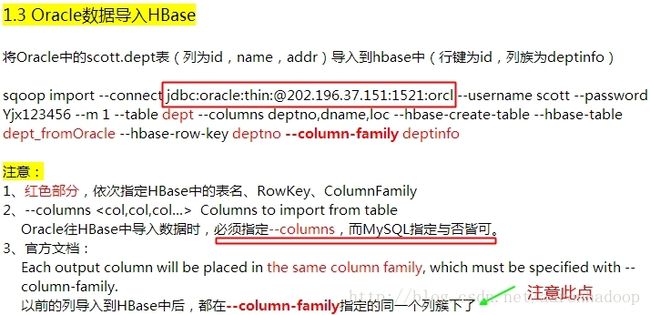
测试连接
bin/sqoop list-databases \
--connect jdbc:mysql://com.james:3306 \
--username root \
--password-file file:///home/taojiamin/data/passwd.pwd
密码文件
本地文件: file:///home/user/password
hdfs文件: /user/user/password
注意: 密码文件直接vim编辑会报错, 应采用重定向追加或覆盖写入操作
echo -n "password" >> /home/taojiamin/data/passwd.pwd
&& chmod 400 /home/taojiamin/data/passwd.pwd
echo -n 不换行输出;
bin/sqoop import \
--connect jdbc:mysql://apache.bigdata.com:3306/testdb \
--username root \
-P \
--table user \
--append \ //将mysql表的数据追加到HDFS上已存在的数据集
--target-dir /input/sqoop/import \
-m 1 \
--fields-terminated-by ","
bin/sqoop import \
--connect jdbc:mysql://com.hadoop05:3306/testdb \
--username root \
--password-file file:///home/hadoop/mypasswd \
--table user \
--target-dir /sqoop/input \
-m 1 \
--fields-terminated-by '\t' \
--delete-target-dir
全量导入例如:
bin/sqoop import \ (输入命令)
--connect jdbc:mysql://bigdata.ibeifeng.com:3306/testdb \ (指定连接jdbc端口和数据库名称)
--username root \ (数据库用户名)
--password root123 \ (密码 若不适用明文指定数据库密码 则可以用-P)
--table user \ (指定数据库中的一张表)
--target-dir /input/import \ (指定数据导入到HDFS上的目录)
--delete-target-dir \ //如果目标目录已存在,则先删除
--num-mappers 1 \ (指定使用导入数据的map个数,mapreduce(V1)中的方式可以用-m 1 代替(过时))
--fields-terminated-by "," (目标文件的分隔符, 默认情况下,导入HDFS的每行数据分隔符是逗号)
部分字段导入:
bin/sqoop import \
--connect jdbc:mysql://com.apache.bigdata:3306/sqoop \
--username root \
-P \
--table user \
--columns "id,account" \
--target-dir /sqoop/query1 \
-m 1 \
--delete-target-dir \
--fields-terminated-by "\t"
查询导入://待复习
query,where子句必须有$CONDITONS(固定写法) 不能使用 --table
bin/sqoop import \
--connect jdbc:mysql://bigdata.ibeifeng.com:3306/testdb \
--username root \
-P \
--query 'select id,account from user where account="fff" and $CONDITIONS' \
--target-dir /input/query \
-m 1 \
--delete-target-dir \
--fields-terminated-by "\t"
增量导入3个参数
注意:
1.--append and --delete-target-dir can not be used together.
2.--check-column 不是使用CHAR/NCHAR/VARCHAR/VARNCHAR/ LONGVARCHAR/LONGNVARCHAR这样的数据类型
后面跟 唯一 不重复的列 类似主键
3.--incremental 支持两种模式
append 告诉sqoop是整型数据自增长的方式来区分从哪里开始增量导入
lastmodified 告诉sqoop是最后一次修改文件的时间戳来区分从哪里开始增量导入
bin/sqoop import \
--connect jdbc:mysql://com.apache.bigdata:3306/sqoop \
--username root \
-P \
--table user \
--num-mappers 1 \
--target-dir /sqoop/incremental \
--fields-terminated-by "|" \
--check-column id \ 选择ID 作为主键
--incremental append \ 选择ID来区分从哪里开始增量导入
--last-value 3 选择从id为3之后的行开始导入数据
通过【--options-file】指定文件,运行程序
可以将Sqoop的命令选项写在文件,通过【--options-file】指定文件,进行运行程序。
vim sqoop_script
export
--connect
jdbc:mysql://bigdata.ibeifeng.com:3306/testdb
--username
root
--password
root123
--table
hive2mysql
--num-mappers
1
--export-dir
/user/hive/warehouse/db01.db/dept
--fields-terminated-by
"\t"
$ bin/sqoop --options-file ~/sqoop_script
列出mysql数据库中的所有数据库
sqoop list-databases –connect jdbc:mysql://localhost:3306/ –username root –password 123456
连接mysql并列出test数据库中的表
sqoop list-tables –connect jdbc:mysql://localhost:3306/test –username root –password 123456
命令中的test为mysql数据库中的test数据库名称 username password分别为mysql数据库的用户密码
将关系型数据的表结构复制到hive中,只是复制表的结构,表中的内容没有复制过去。
sqoop create-hive-table –connect jdbc:mysql://localhost:3306/test
–table sqoop_test –username root –password 123456 –hive-table
test
其中 –table sqoop_test为mysql中的数据库test中的表 –hive-table
test 为hive中新建的表名称