爱丁堡NLP课程Python练习题CPSLP: Assignment
CPSLP: Assignment 1
Imagine you are a Data Scientist working for the National Records of Scotland Government Office. You have been asked you to investigate and prepare a report on the recent trends in names that parents are choosing.
You have been given 2 files, the first of which is called scotbabies2015.txt This file contains a list of all the first names of babies born in Scotland in 2015 in random order. The format of the file is as follows (fields are separated by a single tab):
FIRSTNAME GENDER
For example, the first four lines in the file are:
Jackson BOY
Briar-Rose GIRL
Sophie GIRL
Skylar GIRL
The first part of your task is to create a module called babynames.py which contains a class called Babies. This class should contain some internal attribute(s) to store information from the input file. You will have to decide the data-structure(s) for the attribute(s) so that it can represent the baby names, the associated gender and the count (frequency) of that name. You can use any combination of dictionaries, lists and tuples to design this data-structure.
Your class should contain an init (self, filename) constructor, taking a file name as an argument. This should call a method called read_names_from_file(self, filename), which should parse the file and populate your chosen data structure with the contents. By doing this, your class will then have some kind of internal way of representing and storing the data. You should then add the following methods to the class in order to access that data in meaningful ways:
-
get_total_births(self, gender=None)
Returns an int of the total number of babies born. (note: *return*, not print, the answers!)
-
get_names_beginning_with(self, first_char, gender=None) Takes as input a string containing a single character and returns an alphabetically sorted list of baby names that start with that character.
-
get_top_N(self, N, gender=None)
Takes a positive integer N and returns a list of tuples of the top N names [(name1,count1), (name2,count2), ...] ordered from most-common to least-common.
-
get_gender_ratio(self, gender)
Returns a suitable data type representing the result of the following equation: (number babies of given gender) / (total number of births)
Note that some methods include the optional argument “gender”. You should design these methods to handle the case when this argument is optionally set to either the string "BOY" or "GIRL" such that the output is restricted to that gender - e.g. get_total_births(gender=“GIRL") would return the total number of girls born.
Notice some names such as ‘Jamie’ can be "BOY" or “GIRL".
The second file you have been given is called namesdb.txt. This file contains a list of names, with their gender, origin and meaning. For example, in the sample lines
James M English, Replace
Savanna F Spanish, From the open plain
the name “James” is a male name of English origin which has a meaning related to “Replace”. The name “Savanna” is a female name of Spanish origin, which has a meaning related to “From the open plain.”
Your second related task is to estimate the proportions of the different origins of the names which have been given to babies in 2015. To do this, you should add the following 2 methods to your Babies class:
-
read_origins_from_file(self, origins_filename)
Parses a file like namesdb.txt and loads the necessary information (i.e. for the method below to work) into a suitable attribute data structure. (Hint: regular expression(s) will be needed to parse this file format).
-
get_origin_counts(self)
Returns a list of tuples of the origin counts, e.g. [(origin1,count1), (origin2,count2), ...] ordered from most-common to least-common. This should give the counts calculated according to the names babies have actually been given. Therefore, it will be necessary to combine the information loaded from both data files in this method.
NOTE: the origin counts can only be an approximation, since not all names contained in scotbabies.txt appear in the namesdb.txt file - that is fine, don’t worry about it! In addition, as a simplification, you don't need to bother taking into account the gender of the babies when estimating the counts for baby name origins. Specifically, some names exist for both boys and girls, but have different origins listed. If we were being careful, we would take this into account, but for this exercise you don’t need to worry about that level of detail! So, just ignore the gender when making counts of name origins.
You should design all your methods to check whether the input is suitable and print a message to the user if it is not - e.g. if they input the wrong datatype or something that is invalid. It is good programming practice to think of all the inputs that could crash a module or function and to make sure it has built-in contingency for such examples.
We will test your module automatically by importing it and checking the result of the methods with different arguments - e.g. :
import babynames
babies_test = babynames.Babies("scotbabies2015.txt") print( babies_test.get_total_births() )
print( babies_test.get_total_births(gender=“BOY”) ) print( babies_test.get_top_N(20) )
…
You therefore need to be very careful to stick to the interface specified here. You should test your code in a similar way as above to make sure it has the expected output.
When preparing your code, you need to think about the following criteria that are generally used for grading (again, this is an exercise here and won’t be graded, but you should always think in terms of these criteria, as the next assignment will use these for grading):
-
Functionality
Does your code meet the project requirements (i.e. does it work and give the correct answers)? Did you manage to implement all the of requested methods or only some? Does the code run efficiently?
-
Legibility
Is your code well structured, with meaningful variable names and useful comments and documentation?
-
Robustness
How well does your code handle incorrect or unsuitable inputs? What validation have you done?
-
Design
How suitable are your data structures? How well have you avoided code duplication?
You are encouraged to discuss the assignment with fellow course-mates, but all code should be completed individually.
You should submit your code electronically - please see separate announcement for details as to where and by which deadline.
Good luck!
使用的语言是python
代码:
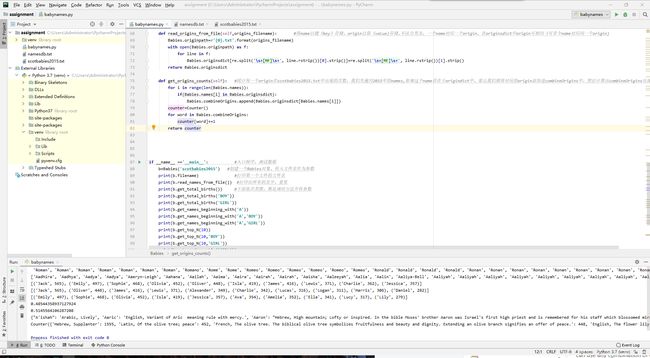
from collections import Counter
import re
class Babies:
names=[] #姓名列表
genders=[] #性别列表
filepath='' #第一个文件path
originpath='' #第二个文件path
originsdict = {} #组成姓名和起源的字典
combineOrigins=[] #排除掉2015年的名字在字典中没有项目,所有的名字对应的起源的列表,有重复项
def __init__(self, filename): #构造函数
self.filename=filename
Babies.filepath=r'{0}.txt'.format(filename)
with open(Babies.filepath) as f: #读取txt里面的内容到f
for line in f: #按行读取
Babies.names.append(line.rstrip().split()[0]) #split切割每行,第一个单词为name,保存到names列表,rstrip()的意思是去除行尾的\n(txt文件每行结尾都有个换行符)
Babies.genders.append(line.rstrip().split()[1]) #同上,存第二个单词,性别
def read_names_from_file(self): #返回一个names列表
return Babies.names
def get_total_births(self,gender=None): #这个方法为返回总共的出生人数,gender没有参数则默认为None,统计总人数。gender为BOY为男性,GIRL为女性
if(gender!=None):
count = 0
for i in range(len(Babies.genders)):
if (Babies.genders[i] == gender):
count = count + 1
return count
else:
return len(Babies.names)
def get_names_beginning_with(self,first_char,gender=None): #得到以first_char为首字母的姓名列表,并按照字母排序,if(gender!=None)按性别,else不按性别
birthslist=[]
if(gender!=None):
with open(Babies.filepath) as f:
for line in f:
if(line.rstrip().split()[1]==gender):
birthslist.append(line.rstrip().split()[0])
birthslist.sort()
return birthslist
else:
for i in range(len(Babies.names)):
if (Babies.names[i][0] == first_char):
birthslist.append(Babies.names[i])
birthslist.sort()
return birthslist
def get_top_N(self,N,gender=None): #统计出现频率最高的N个姓名,返回姓名和出现次数的元组,if(gender!=None)为按性别,else为不分性别统计
if(gender!=None):
nameslistbygender=[]
with open(Babies.filepath) as f:
for line in f:
if(line.rstrip().split()[1]==gender):
nameslistbygender.append(line.rstrip().split()[0])
counter=Counter()
for word in nameslistbygender:
counter[word]+=1
return counter.most_common(N)
else:
counter = Counter()
for word in Babies.names:
counter[word] += 1
return counter.most_common(N)
def get_gender_ratio(self,gender): #计算性别占比
count = 0
for i in range(len(Babies.genders)):
if (Babies.genders[i] == gender):
count = count + 1
return count/len(Babies.genders)
def read_origins_from_file(self,origins_filename): #将name以键(key)存储,origin以值(value)存储.不区分男女,一个name对应一个origin,在originsdict中origin可相同(可多个name对应同一个origin)
Babies.originpath=r'{0}.txt'.format(origins_filename)
with open(Babies.originpath) as f:
for line in f:
Babies.originsdict[re.split('\s+[MF]\s+', line.rstrip())[0].strip()]=re.split('\s+[MF]\s+', line.rstrip())[1].strip()
return Babies.originsdict
def get_origins_counts(self): #统计每一个origin在scotbabies2015.txt中出现的次数,我们先遍历2015年的names,如果这个name存在于origindict中,那么我们就将对应的origin添加进combineOrigins中,然后计算出combineOrigins出现的频率
for i in range(len(Babies.names)):
if(Babies.names[i] in Babies.originsdict):
Babies.combineOrigins.append(Babies.originsdict[Babies.names[i]])
counter=Counter()
for word in Babies.combineOrigins:
counter[word]+=1
return counter
if __name__ =='__main__': #入口程序,测试数据
b=Babies('scotbabies2015') #创建一个Babies对象,传入文件名作为参数
print(b.filename) #打印第一个文件的文件名
print(b.read_names_from_file()) #打印出所有的名字,重复
print(b.get_total_births()) #下面依次类推,都是调用方法并传参数
print(b.get_total_births('BOY'))
print(b.get_total_births('GIRL'))
print(b.get_names_beginning_with('A'))
print(b.get_names_beginning_with('A','BOY'))
print(b.get_names_beginning_with('A','GIRL'))
print(b.get_top_N(10))
print(b.get_top_N(10,'BOY'))
print(b.get_top_N(10,'GIRL'))
print(b.get_gender_ratio('GIRL'))
print(b.get_gender_ratio('BOY'))
print(b.read_origins_from_file('namesdb'))
print(b.get_origins_counts())
数据和代码参考资源信息下载
访问我的github