Lucene全文检索
Demo地址:https://github.com/UserFengFeng/Lucene-Maven.git
伸手党======>> Luke、IKAnalyzer7.2.0.jar:
链接:https://pan.baidu.com/s/1vaifZeSG5Uj5HmSYU89GXQ
提取码:dbnm
复制这段内容后打开百度网盘手机App,操作更方便哦关于它的介绍,请自行百度,不过多解释。
全文检索首先将要查询的目标文档中的词提取出来,组成索引(相当于书的目录),通过查询索引达到搜索目标文档的目的,这种先建立索引,在对索引进行搜索的过程叫做全文检索(Full-textSearch)。
有两个概念叫:正排索引,倒排索引
Lucene是apache下的一个开源的全文检索引擎工具包,提供了完整的查询引擎和索引引擎,部分文本分析引擎。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能。
Lucene和搜索引擎不同,Lucene是一套用java或其他语言写的全文检索的工具包,为应用程序提供了很多个api接口去调用,可以简单理解为是一套实现全文检索的类库,搜索引擎是一个全文检索系统,它是一个单独运行的软件。
Lucene和luke结合使用。
Demo: Maven+Lucene
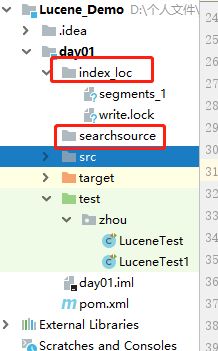
1.目录结构:
2.pom.xml文件
4.0.0
day01
day01
1.0-SNAPSHOT
war
day01 Maven Webapp
http://www.example.com
UTF-8
1.7
1.7
junit
junit
4.11
test
org.apache.lucene
lucene-core
7.2.0
org.apache.lucene
lucene-analyzers-common
7.2.0
org.apache.lucene
lucene-analyzers-smartcn
7.2.0
org.apache.lucene
lucene-queryparser
7.2.0
org.apache.lucene
lucene-highlighter
7.2.0
com.janeluo
ikanalyzer
2012_u6
day01
maven-clean-plugin
3.1.0
maven-resources-plugin
3.0.2
maven-compiler-plugin
3.8.0
maven-surefire-plugin
2.22.1
maven-war-plugin
3.2.2
maven-install-plugin
2.5.2
maven-deploy-plugin
2.8.2
3.Test类
package zhou;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.StringField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.queries.function.valuesource.LongFieldSource;
import org.apache.lucene.store.FSDirectory;
import org.junit.Before;
import org.junit.Test;
import java.awt.*;
import java.io.*;
import java.nio.file.Path;
import java.nio.file.Paths;
import static org.apache.lucene.document.Field.Store.YES;
public class LuceneTest {
@Before
public void setUp() throws Exception{
}
/*
* 导入索引
* */
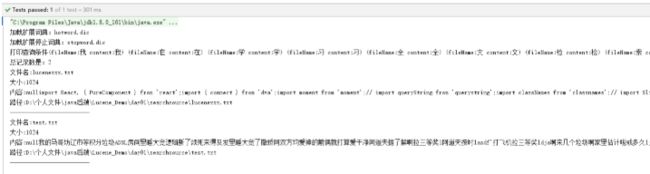
@Test
public void importIndex() throws IOException {
// 获得索引库的位置
// 项目路径下创建索引库的文件夹index_loc
Path path = Paths.get("D:\\个人文件\\java后端\\Lucene_Demo\\day01\\index_loc");
// 打开索引库
FSDirectory dir = FSDirectory.open(path);
// 创建分词器
Analyzer al = new StandardAnalyzer();
// 创建索引的写入的配置对象
IndexWriterConfig iwc = new IndexWriterConfig(al);
// 创建索引的Writer
IndexWriter iw = new IndexWriter(dir, iwc);
/*
* 采集原始文档
* 创建searchsource文件,放入原始文档文件
* */
File sourceFile = new File("D:\\个人文件\\java后端\\Lucene_Demo\\day01\\searchsource");
// 获得文件夹下的所有文件
File[] files = sourceFile.listFiles();
// 遍历每一个文件
for(File file : files) {
// 获得file的属性
String fileName = file.getName();
FileInputStream inputStream = new FileInputStream(file);
InputStreamReader streamReader = new InputStreamReader(inputStream);
BufferedReader reader = new BufferedReader(streamReader);
String line;
// StringBuilder builder = new StringBuilder();
String content = null;
while ((line =reader.readLine()) != null) {
// builder.append(line);
content += line;
}
reader.close();
inputStream.close();
String path1 = file.getPath();
// StringField不分词
Field fName = new StringField("fileName", fileName, YES);
Field fcontent = new TextField("content", content, YES);
Field fsize = new TextField("size", "1024", YES);
Field fpath = new TextField("path", path1, YES);
// 创建文档对象
Document document = new Document();
// 把域加入到文档中
document.add(fName);
document.add(fcontent);
document.add(fsize);
document.add(fpath);
// 把文档写入到索引库
iw.addDocument(document);
}
// 提交
iw.commit();
iw.close();
}
}4.Field常用类型

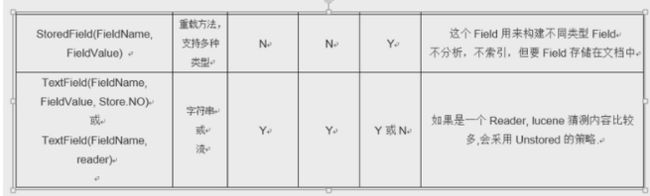
注意:LongField分析会乱码,也能被分析,但是意义不大。
5.分词器介绍



6.分词器案例
Test类:
package zhou;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
import org.apache.lucene.analysis.tokenattributes.OffsetAttribute;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.StringField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.store.FSDirectory;
import org.junit.Before;
import org.junit.Test;
import java.io.*;
import java.nio.file.Path;
import java.nio.file.Paths;
import static org.apache.lucene.document.Field.Store.YES;
public class LuceneTest1 {
@Before
public void setUp() throws Exception {
}
@Test
public void importIndex() throws IOException {
// 创建分词器(对中文分词不太良好)
// StandardAnalyzer al = new StandardAnalyzer();
Analyzer al = new CJKAnalyzer();
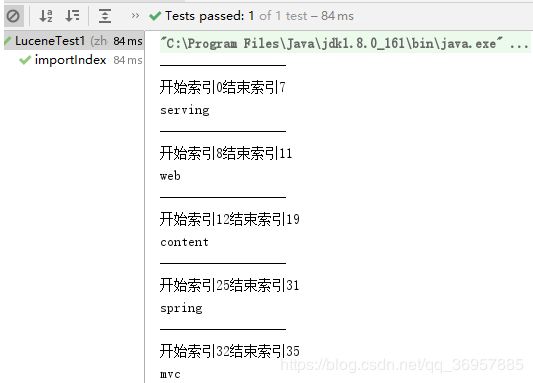
// 分词
TokenStream stream = al.tokenStream("content", "Serving web content with spring mvc");
// 分词对象的重置
stream.reset();
// 获得每一个语汇的偏移量属性对象
OffsetAttribute oa = stream.addAttribute(OffsetAttribute.class);
// 获得分词的语汇属性
CharTermAttribute ca = stream.addAttribute(CharTermAttribute.class);
// 遍历分词的语汇流
while (stream.incrementToken()) {
System.out.println("------------------");
System.out.println("开始索引" + oa.startOffset() + "结束索引" + oa.endOffset());
System.out.println(ca);
}
}
}
7.IKAnalyzer中文分词器
注意:该jar需要另外导入,试了好几个版本的Maven在线导入都不行,只能换离线了
引入IKAnalyzer的jar包及配置文件:https://pan.baidu.com/s/1SrKHlv_YSKy8ffb28ZFtbQ
目录结构:
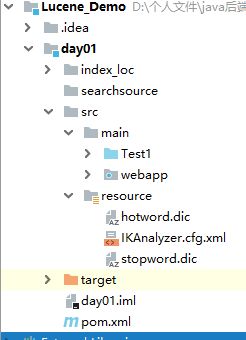
配置文件的名称不能随便改,因为它的源码里面是写死的,不然会抛出异常。
java.lang.RuntimeException: Main Dictionary not found!!!
at org.wltea.analyzer.dic.Dictionary.loadMainDict(Dictionary.java:200)
at org.wltea.analyzer.dic.Dictionary.(Dictionary.java:69)
at org.wltea.analyzer.dic.Dictionary.initial(Dictionary.java:86)
at org.wltea.analyzer.core.IKSegmenter.init(IKSegmenter.java:85)
at org.wltea.analyzer.core.IKSegmenter.(IKSegmenter.java:65)
at org.wltea.analyzer.lucene.IKTokenizer.(IKTokenizer.java:78)
at org.wltea.analyzer.lucene.IKTokenizer.(IKTokenizer.java:64)
at org.wltea.analyzer.lucene.IKAnalyzer.createComponents(IKAnalyzer.java:64)
at org.apache.lucene.analysis.Analyzer.tokenStream(Analyzer.java:198)
at zhou.LuceneTest1.importAnalyzer(LuceneTest1.java:29)...
源码固定写死位置(也可进行更改源码自行定义):
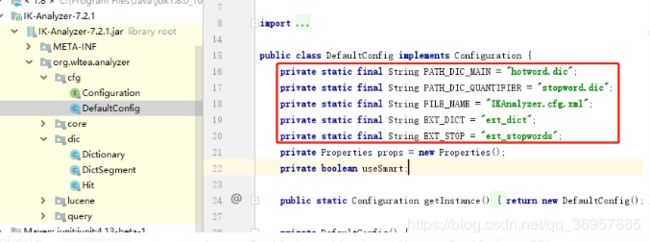
Test类
package zhou;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.cjk.CJKAnalyzer;
import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
import org.apache.lucene.analysis.tokenattributes.OffsetAttribute;
import org.junit.Before;
import org.junit.Test;
import org.wltea.analyzer.core.IKSegmenter;
import org.wltea.analyzer.core.Lexeme;
import org.wltea.analyzer.lucene.IKAnalyzer;
import java.io.*;
public class LuceneTest1 {
@Before
public void setUp() throws Exception {
}
@Test
public void importAnalyzer() throws IOException {
// 创建分词器
// StandardAnalyzer al = new StandardAnalyzer();
// Analyzer al = new CJKAnalyzer();
Analyzer al = new IKAnalyzer();
// 分词
TokenStream stream = al.tokenStream("content", "当前市场不稳定,得赶紧稳盘抛出。");
// 分词对象的重置
stream.reset();
// 获得每一个语汇的偏移量属性对象
OffsetAttribute oa = stream.addAttribute(OffsetAttribute.class);
// 获得分词的语汇属性
CharTermAttribute ca = stream.addAttribute(CharTermAttribute.class);
// 遍历分词的语汇流
while (stream.incrementToken()) {
System.out.println("------------------");
System.out.println("开始索引" + oa.startOffset() + "结束索引" + oa.endOffset());
System.out.println(ca);
}
}
}8.Luke的使用(管理索引库)


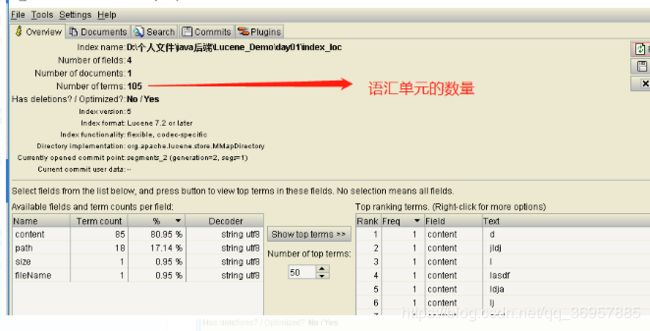
9.添加索引
public class LuceneTest2 {
@Before
public void setUp() throws Exception {
}
/*
* 导入索引
* */
@Test
public void importIndex() throws IOException {
IndexWriter iw = getIndexWriter();
/*
* 采集原始文档
* 创建searchsource文件,放入原始文档文件
* */
File file = new File("D:\\个人文件\\java后端\\Lucene_Demo\\day01\\searchsource\\test.txt");
String content = readFileContent(file);
String fileName = file.getName();
String filePath = file.getPath();
// StringField不分词
Field fName = new StringField("fileName", fileName, YES);
Field fcontent = new TextField("content", content, YES);
// 此处1024是要获取文件大小,本人偷懒请忽略
Field fsize = new TextField("size", "1024", YES);
Field fpath = new TextField("path", filePath, YES);
// 创建文档对象
Document document = new Document();
// 把域加入到文档中
document.add(fName);
document.add(fcontent);
document.add(fsize);
document.add(fpath);
// 把文档写入到索引库
iw.addDocument(document);
// 提交
iw.commit();
iw.close();
}
public IndexWriter getIndexWriter() throws IOException {
// 获得索引库的位置
// 项目路径下创建索引库的文件夹index_loc
Path path = Paths.get("D:\\个人文件\\java后端\\Lucene_Demo\\day01\\index_loc");
// 打开索引库
FSDirectory dir = FSDirectory.open(path);
// 创建分词器
Analyzer al = new IKAnalyzer();
// 创建索引的写入的配置对象
IndexWriterConfig iwc = new IndexWriterConfig(al);
// 创建索引的Writer
IndexWriter iw = new IndexWriter(dir, iwc);
return iw;
}
// 获取文件内容
public String readFileContent(File file) {
BufferedReader reader = null;
StringBuffer sbf = new StringBuffer();
try {
reader = new BufferedReader(new FileReader(file));
String tempStr;
while ((tempStr = reader.readLine()) != null) {
sbf.append(tempStr);
}
reader.close();
return sbf.toString();
} catch (IOException e) {
e.printStackTrace();
} finally {
if (reader != null) {
try {
reader.close();
} catch (IOException e1) {
e1.printStackTrace();
}
}
}
return sbf.toString();
}
}10.删除索引
(1)删除全部
// 删除索引
@Test
public void deleteIndex() throws IOException {
IndexWriter iw = getIndexWriter();
iw.deleteAll();
iw.commit();
iw.close();
}(2)删除符合条件的索引
@Test
public void deleteIndexByQuery() throws IOException {
IndexWriter iw = getIndexWriter();
// 创建语汇单元项
Term term = new Term("content", "三");
// 创建根据语汇单元的查询对象
TermQuery query = new TermQuery(term);
iw.deleteDocuments(query);
iw.commit();
iw.close();
}11.分词语汇单元查询
创建查询
对要搜索的信息创建Query查询对象,Lucene会根据Query查询对象生成最终的查询语法,类似关系数据库Sql语法一样Lucene也有自己的查询语法,比如:“name:lucene”表示查询Field的name为“Lucene”的文档信息。
可通过两种方法创建查询对象:
(1)使用Lucene提供Query子类
Query是一个抽象类,Lucene提供了很多查询对象,比如TermQuery项精确查询。NumericRangeQuery数字范围查询等。
Query query = new TermQuery(new Term("name", "lucene"));(2)使用QueryParse解析插叙表达式
QueryParse会将用户输入的查询表达式解析成Query对象实例
QueryParse queryParse = new QueryParse("name", new IKAnalyzer());
Query query = queryParse.parse("name:lucene");Test类
package zhou;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.StringField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.Term;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TermQuery;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.FSDirectory;
import org.junit.Before;
import org.junit.Test;
import org.wltea.analyzer.lucene.IKAnalyzer;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileReader;
import java.io.IOException;
import java.nio.file.Path;
import java.nio.file.Paths;
import static org.apache.lucene.document.Field.Store.YES;
public class LuceneTest3 {
@Before
public void setUp() throws Exception {
}
@Test
public void queryIndex() throws IOException {
Path path = Paths.get("D:\\个人文件\\java后端\\Lucene_Demo\\day01\\index_loc");
FSDirectory open = FSDirectory.open(path);
// 创建索引的读取对象
DirectoryReader reader = DirectoryReader.open(open);
// 创建索引库的所有对象
IndexSearcher is = new IndexSearcher(reader);
// 创建语汇单元的对象(查询语汇单元文件名称为test.txt的文件)
Term term = new Term("fileName", "test.txt");
// 创建分词的语汇查询对象
TermQuery tq = new TermQuery(term);
// 查询(前多少条)
TopDocs result = is.search(tq, 100);
// 总记录数
int total = (int) result.totalHits;
System.out.println("总记录数是:" + total);
for (ScoreDoc sd : result.scoreDocs) {
// 获得文档的id
int id = sd.doc;
// 获得文档对象
Document doc = is.doc(id);
String fileName = doc.get("fileName");
String size = doc.get("size");
String content = doc.get("content");
String path1 = doc.get("path");
System.out.println("文件名:" + fileName);
System.out.println("大小:" + size);
System.out.println("内容:" + content);
System.out.println("路径:" + path);
System.out.println("-------------------------");
}
}
}12.数值范围查询对象
1.NumericRangeQuery
指定数字范围查询,如下:
// 文件大小在0到1024的文件
@Test
public void rangeQuery() throws IOException {
IndexSearcher is = getDirReader();
// 创建数值范围查询对象
Query tq = NumericRangeQuery.newLongRange("size", 01, 1001, true, true);
printDoc(is, tq);
}
public IndexSearcher getDirReader() throws IOException {
Path path = Paths.get("D:\\个人文件\\java后端\\Lucene_Demo\\day01\\index_loc");
FSDirectory open = FSDirectory.open(path);
// 创建索引的读取对象
DirectoryReader reader = DirectoryReader.open(open);
// 创建索引库的所有对象
IndexSearcher is = new IndexSearcher(reader);
return is;
}
// 打印结果
public static void printDoc(IndexSearcher is, Query tq) throws IOException {
// 查询(前多少条)
TopDocs result = is.search(tq, 100);
// 总记录数
int total = (int) result.totalHits;
System.out.println("总记录数是:" + total);
for (ScoreDoc sd : result.scoreDocs) {
// 获得文档的id
int id = sd.doc;
// 获得文档对象
Document doc = is.doc(id);
String fileName = doc.get("fileName");
String size = doc.get("size");
String content = doc.get("content");
String path1 = doc.get("path");
System.out.println("文件名:" + fileName);
System.out.println("大小:" + size);
System.out.println("内容:" + content);
System.out.println("路径:" + path1);
System.out.println("-------------------------");
}
}13.多查询对象联合查询
/*
* 多个条件的组合查询
* */
@Test
public void queryIndex2() throws IOException {
IndexSearcher is = getDirReader();
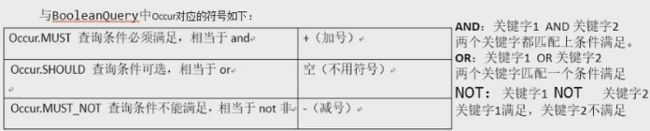
// 创建BooleanQuery查询对象,这种查询对象可以控制是& | !
BooleanQuery bq = new BooleanQuery();
// 创建一个分词的语汇查询对象
Query query = new TermQuery(new Term("fileName", "test.txt"));
Query query1 = new TermQuery(new Term("content", "test.txt"));
bq.add(query, BooleanClause.Occur.MUST);
// SHOULD 可有可无
bq.add(query1, BooleanClause.Occur.SHOULD);
System.out.println("查询条件" + bq);
printDoc(is, bq);
}
public IndexSearcher getDirReader() throws IOException {
Path path = Paths.get("D:\\个人文件\\java后端\\Lucene_Demo\\day01\\index_loc");
FSDirectory open = FSDirectory.open(path);
// 创建索引的读取对象
DirectoryReader reader = DirectoryReader.open(open);
// 创建索引库的所有对象
IndexSearcher is = new IndexSearcher(reader);
return is;
}
// 打印结果
public static void printDoc(IndexSearcher is, Query tq) throws IOException {
// 查询(前多少条)
TopDocs result = is.search(tq, 100);
// 总记录数
int total = (int) result.totalHits;
System.out.println("总记录数是:" + total);
for (ScoreDoc sd : result.scoreDocs) {
// 获得文档的id
int id = sd.doc;
// 获得文档对象
Document doc = is.doc(id);
String fileName = doc.get("fileName");
String size = doc.get("size");
String content = doc.get("content");
String path1 = doc.get("path");
System.out.println("文件名:" + fileName);
System.out.println("大小:" + size);
System.out.println("内容:" + content);
System.out.println("路径:" + path1);
System.out.println("-------------------------");
}
}14.解析查询
(1) QueryParse查询
/*
* 查询条件的解析查询
* 第一种
* */
@Test
public void queryIndex3() throws IOException, ParseException {
IndexSearcher is = getDirReader();
IKAnalyzer ik = new IKAnalyzer();
// 创建查询解析对象
QueryParser parser = new QueryParser("content", ik);
// 解析查询对象(换言之就是根据如下这句话解析出来后,查询在fileName这个域中的内容)
Query query = parser.parse("我在学习全文检索技术Lucene");
System.out.println("打印查询条件" + query);
printDoc(is, query);
}
/*
* 解析查询
* 第二种
* */
@Test
public void queryIndex4() throws IOException, ParseException {
IndexSearcher is = getDirReader();
IKAnalyzer ik = new IKAnalyzer();
// 创建查询解析对象
QueryParser parser = new QueryParser("content", ik);
// 自己写查询对象条件 AND OR || !
Query query = parser.parse("content: 我 AND 你是 ! 好的");
System.out.println("打印查询条件" + query);
printDoc(is, query);
}
(2)多域条件解析查询
MultiFieldQueryParse组合域查询。
通过MultiFieldQueryParse对多个域查询,比如商品信息查询,输入关键字需要从商品名称和商品内容中查询。
// 设置组合查询域
String[] fields = {"fileName", "fileContent"};
// 创建查询解析器
QueryParse queryParse = new MultiFieldQueryParse(fields, new IKAnalyzer());
// 查询文件名、文件内容包括“java”关键字的文档
Query query = queryParse.parse("java");Test类:
/*
* 多域条件解析查询
* */
@Test
public void multiFieldQuery() throws IOException, ParseException {
IndexSearcher is = getDirReader();
IKAnalyzer ik = new IKAnalyzer();
String[] fields = {"fileName", "content"};
MultiFieldQueryParser parser = new MultiFieldQueryParser(fields, ik);
Query query = parser.parse("我在学习全文检索技术Lucene");
System.out.println("打印查询条件" + query);
printDoc(is, query);
}