solr-5.0.0 在windows下的安装和配置使用ik中文分词器(单机版)
什么是solr:
以前再做项目的时候(像crm,erp,等企业项目(一般企业内部项目))的时候都是用的模糊查询,像什么like,limit等。但是在一些大型门户网站、电商网站,再用这种方法去数据库查,首先人多的时候响应慢数据库压力大,就单这方面就存在问题,而且搜索完整性很差。当用户量大的时候,总不能每搜索一次都需要查询一遍数据库吧。
Solr与Lucene的区别:
Lucene是一个开放源代码的全文检索引擎工具包,它不是一个完整的全文检索引擎,Lucene提供了完整的查询引擎和索引引擎,目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者以Lucene为基础构建全文检索引擎。
Solr的目标是打造一款企业级的搜索引擎系统,它是一个搜索引擎服务,可以独立运行,通过Solr可以非常快速的构建企业的搜索引擎,通过Solr也可以高效的完成站内搜索功能。
windows下安装配置solr
运行环境:
Solr:solr-5.0.0 下载地址:http://archive.apache.org/dist/lucene/solr/5.0.0/ 需要下载solr-5.0.0.zip。
jdk:jdk1.8.0_151
tomcat:tomcat-8.5.23
(需要注意的是:Solr 必须运行在Java1.6 或更高版本的Java 虚拟机中,5.0之后需要tomcat7及以上版本,tomcat 的 版本需要和jdk 的版本对应,否则启动tomcat的时候会报错,solr6.0以上,官方建议使用jdk8,tomcat8。和solr4部署流程有略微差别)
1.确保安装jdk环境:
安装验证java -version
2.新建安装目录:如:D:\tomcat-solr)
3.安装tomcat并修改端口号
例:D:\tomcat-solr\apache-tomcat-8.5.23 - 8084
首先查看端口是否被占用。 ps -aux|grep 8084 修改tomcat端口号例如8084.
修改/tomcat-solr/apache-tomcat-8.5.23 - 8084/conf下的server.xml .
修改端口
connectionTimeout="20000"
redirectPort="8443"/>
三个端口不要有冲突。8084 在下面会用到。记得修改配置。
以下tomcat目录均以/tomcat-solr/apache-tomcat-8.5.23 - 8085目录为例子。
4.解压solr-5.0.0.zip,解压文件到D:\tomcat-solr\:
解压完后,将D:\tomcat-solr\apache-tomcat-8.5.23 - 8084\webapps文件夹下的solr.war 放到 D:\tomcat-solr\apache-tomcat-8.5.23 - 8084\webapps文件夹下解压solr 文件,解压之后删除solr.war 。
(注意:解压后一定要删除solr.war这个war包,不然启动tomcat的时候会自动解压这个war包那么会覆盖我们解压过的solr文件夹,导致我们之后在solr文件夹里面做的一些操作被覆盖了。)
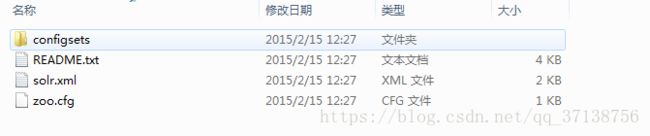
解压solr-5.0.0.zip文件后得到的目录结构为:
解压solr.war得到的目录:
5.新建solrHome文件夹例如/tomcat-solr/solrHome
6.修改tomcat 内容具体如下:
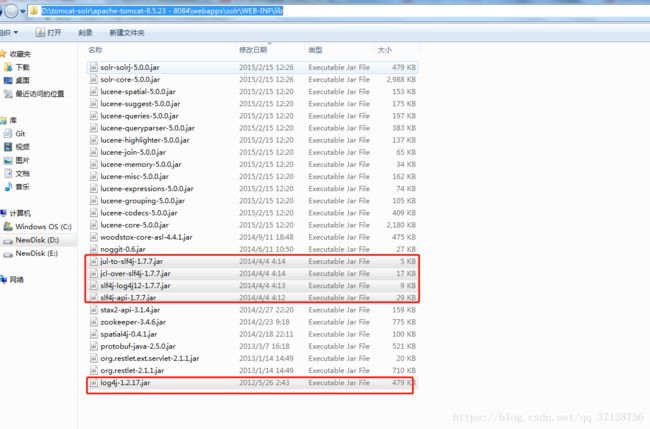
6.1: 将D:\tomcat-solr\Solr\solr-5.0.0\server\lib\ext
下的所有jar拷贝到tomcat下的webapps/solr/WEB-INF/lib下(一共5个jar包)
(例如:tomcat路径)D:\tomcat-solr\apache-tomcat-8.5.23 - 8084\webapps\solr\WEB-INF\lib)
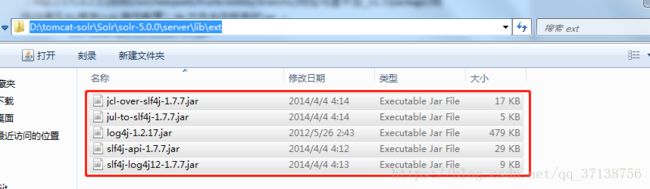
拷贝到tomcat下的webapps/solr/WEB-INF/lib下(拷贝一共5个jar包):
6.2 下载ik分词器所需jar包,mysql数据库链接所需jar包,数据库定时同步更新数据和索引所需jar包,关系型数据库导入到solr服务器所需jar包
百度网盘:链接:https://pan.baidu.com/s/1uFZErnj4nrG__D1Acx3ciw 密码:2gf9
CSDN资源库:https://download.csdn.net/download/qq_37138756/10506156
solr-dataimportscheduler-1.0.jar
solr-dataimporthandler-5.0.0.jar
solr-dataimporthandler-extras-5.0.0.jar
solr-analyzer-extra-5.1.0.jar
IKAnalyzer-5.0.jar
mysql-connector-java-5.1.35.jar
拷贝到tomcat下的webapps/solr/WEB-INF/lib下(下载一共6个jar包):

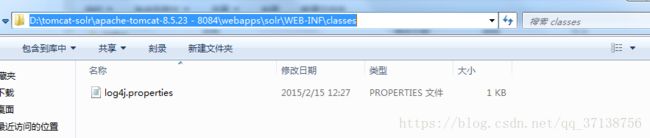
6.3: 将D:\tomcat-solr\Solr\solr-5.0.0\example\resources\log4j.properties 复制到tomcat下的webapps/solr/WEB-INF/classes 复制到tomcat下的webapps/solr/WEB-INF/classes
(如果/webapps/solr/WEB-INF下 没有classes,创建clssses文件)
修改log4j.properties文件。修改solr.log= 为tomcat下的/logs目录。

复制到tomcat下的webapps/solr/WEB-INF/classes :
6.4 修改D:\tomcat-solr\apache-tomcat-8.5.23 - 8084\webapps\solr\WEB-INF
文件夹下的web.xml具体内容如下:

(D:\tomcat-solr\solrHome 为第5步骤创建solrHome目录)
7.配置solr数据.
7.1 将Solr\solr-5.0.0\server\solr下的内容,拷贝到\tomcat-solr\solrHome目录下。
(例:D:\tomcat-solr\Solr\solr-5.0.0\server\solr\* D:\tomcat-solr\solrHome\)
在文件夹下的\tomcat-solr\solrHome,创建一个文件夹core(下面有用到)
(例如 D:\tomcat-solr\solrHome\core).
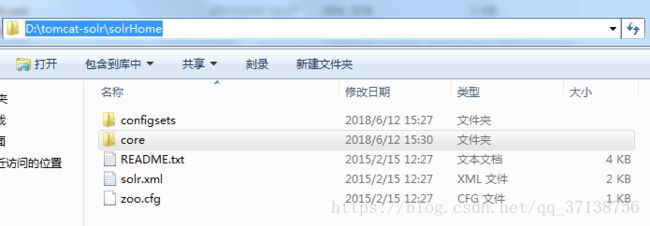
将D:\tomcat-solr\Solr\solr-5.0.0\example\example-DIH\solr\solr 下的所有文件
放到D:\tomcat-solr\solrHome\core文件下的内容.
(data 在有数据后才会创建,拷贝是没有的)

启动tomcat配置,打开网址信息如下:http://localhost:8084/solr
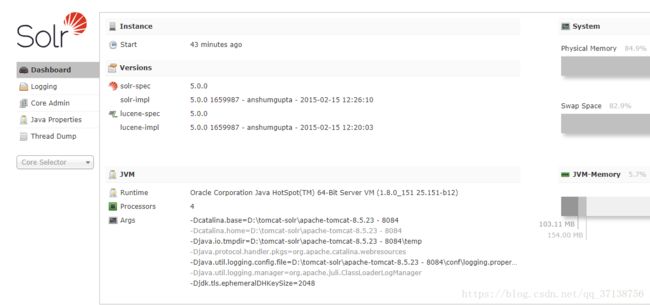
1、DashBoard:solr的版本信息、jvm的相关信息还有一些内存信息。
2、Logging:日志信息,也有日志级别,刚进入查看的时候肯定是有几个警告(warn)信息的,因为复制solr的时候路径发生了变化导致找不到文件,但是并不影响。
3、Core Admin:SolrCore的管理页面,也就是一个solr实例(前面说过Collection1就是一个solr实例),可以理解为一个数据库,所以外部可以对该solr实例中的数据进行增删改查操作。一个solr工程可以有多个SolrCore,它们之间不相互影响。
4、Java Properties:顾名思义,java的相关配置,比如类路径,文件编码等。
5、Thread Dump:solr服务器当前活跃的一些线程的相关信息。
以上的5个了解一下就行。
6、Core Selector:选择一个Solr实例进行操作。
选择Core Admin 点击Add Core

点击Core Admin 开始创建仓库。
(name 为新建的名称
instanceDir 为你创建solrHome目录下的文件名,在solrHome下创建的目录,刚刚已经创建core文件夹,必须和上面你创建的solrHome下的文件名一样。
dataDir 表示你core的数据目录,当前索引数据默认放在data下,
config和schema默认就可以)
(注意:在创建的时候会创建失败,因为在7.1操作的时候已经创建了core,如需创建更换别的名称即可)
7.2 打开D:\tomcat-solr\solrHome\core\conf 下的修改schema.xml 文件夹
7.2.1配置ik分词器,在

7.2.2 添加如下内容:在field 下面添加 静态域 ,使用ik分词器

<Field />
Field相当于Java中的类属性,用户存放数据,因此用户根据业务需要去定义相关的Field(域),一般来说,每一种对应着一种数据,用户对同一种数据进行相同的操作。Field的定义主要是对属性进行赋值。
name:域名城,域的标示名称,在进行索引、查询所使用名称。
type:该属性指定域类型,指定该种类所对应的域类型,对应着相应的数据处理方式
default:给该域设置一个默认值,如果用户没有对该属性进行赋值时,该域将填充一个默认值。
indexed:该域的数据是否进行索引。填充值为true后者false
stored:是否进行存储,因为在搜索是否可以返回所有的数据。填充值为true或者falsemultivalued:是否使用多值,如果使用true,表明单个文档的该属性可能含有多个值

除了静态域以外,常用的域类型还有:动态域,复制域(本文只用到了静态域,和主键域)
url="jdbc:mysql://localhost:3306/testmaven"
user="root"
password="root"
/>
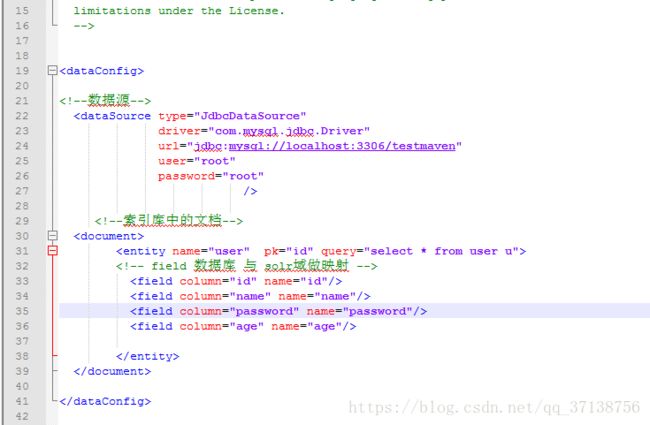
url="jdbc:mysql://localhost:3306/testmaven" 数据库连接地址和库名字
user="neeq" 用户名
password="neeqneeq" 密码
name : 用以标识entity,唯一
query : 获取用于 全量导入 需要导入的数据的sql
pk: 指定数据库主键(可选)。使用增量导入时必选。它跟schema.xml中定义的uniqueKey没有必然的联系,但他们可以相同
8.数据导入
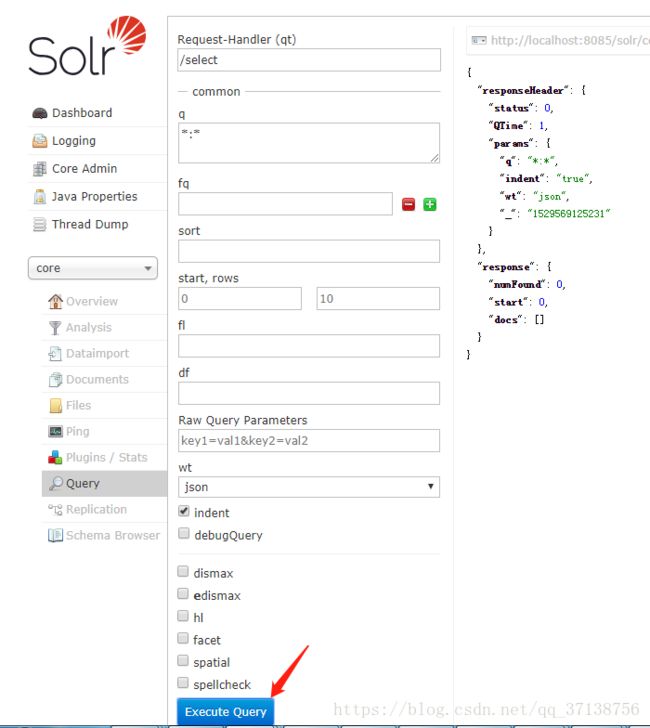
8.1打开网址信息点击按钮query,点击Execute Query按钮,查看索引结果:
8.2点击Dataimport ,选择Execute 执行。数据导入成功

commad 参数取值:
full-import : 全量导入
delta-import : 增量导入
reload-config : 若solr-data-config.xml已经改变,又不想重启solr,而要重新启动加载配置时,可以使用这个值
abort : 终止一个在运行的操作
其他参数:
clean : 决定在建立索引之前,删除以前的索引(默认:true)
commit : 决定这个操作之后是否要commit(默认:true)
optimize : 决定这个操作之后是否要优化(默认:true)
entity : entity是document下面的标签(solr-data-config.xml)。使用这个参数可以有选择的执行一个或多个。如果不选择此参数那么所有的都会被运行
debug : 是否以调试模式运行,适用于交互式开发中。(若以调试默认运行,默认不会自动提交,需加参数commit=true)
全量导入和增量导入的区别:
solr索引设置完成后,需要根据数据库的变化及时更新索引,索引的更新有两种方式:
全量导入:删除solr服务器上的所以索引,然后重新导入数据
增量导入:值更新修改的数据,可能是修改,添加的数据
增量导入注意事项:
增量导入时切忌将clean参数设为false,否则将删除以前的索引
(逻辑删除可通过设置deletedPKQuery进行增量导入(如:deletedPKQuery =“select id_ from user where logo_yn = 0”)
物理删除数据增量导入是无效的,需自己额外处理(如写个存储过程让deletedPKQuery调用;或使用Solrj方法删除))
8.3点击Query按钮。右侧界面出现数据,导入数据成功,确保有数据情况下,查看数据内容
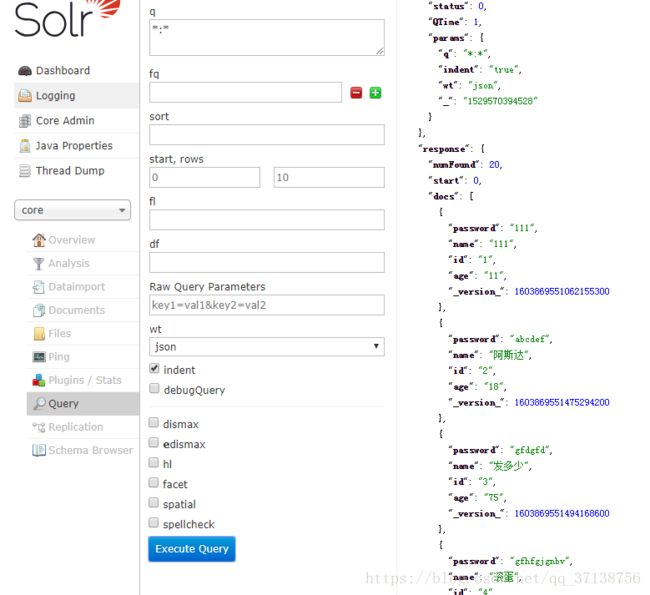
数据查询成功以后,solr使用ik分词器基本配置已经完成。