Spark GraphX图计算框架原理概述
言之易而为之难,学习大数据之图计算,就是从“浊”中找出“静”的规律,达到“清”的境界;从“安”中找出“生”的状态。
转发请标明原文地址:原文地址
概述
GraphX是Spark中用于图和图计算的组件,GraphX通过扩展Spark RDD引入了一个新的图抽象数据结构,一个将有效信息放入顶点和边的有向多重图。如同Spark的每一个模块一样,它们都有一个基于RDD的便于自己计算的抽象数据结构(如SQL的DataFrame,Streaming的DStream)。为了方便与图计算,GraphX公开了一系列基本运算(InDegress,OutDegress,subgraph等等 ),也有许多用于图计算算法工具包(PageRank,TriangleCount,ConnectedComponents等等算法)。相对于其他分布式图计算框架,Graphx最大的贡献,也是大多数开发喜欢它的原因是,在Spark之上提供了一站式解决方案,可以方便且高效地完成图计算的一整套流水作业;即在实际开发中,可以使用核心模块来完成海量数据的清洗与与分析阶段,SQL模块来打通与数据仓库的通道,Streaming打造实时流处理通道,基于GraphX图计算算法来对网页中复杂的业务关系进行计算,最后使用MLLib以及SparkR来完成数据挖掘算法处理。
图计算
图计算广泛的应用与社交网站中,众所周知,社交网络中复杂的交际关系,比如FaceBook,Twitter等。都需要使用图计算来计算彼此的联系,当一个图的规模非常大的时候,就需要使用分布式图计算框架,Spark GraphX天然的基于Spark分布式框架,因此,更加利于处理大规模的图计算。
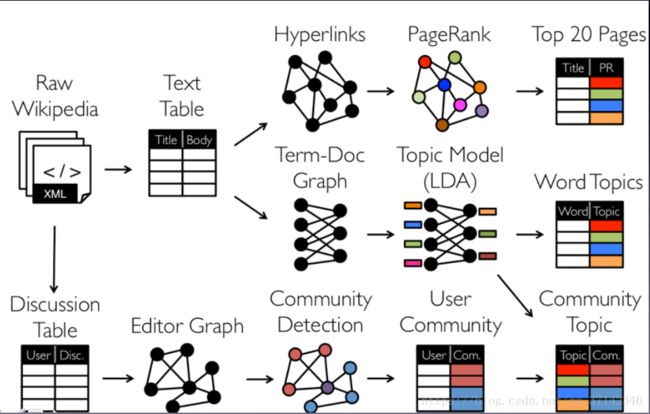
如上图所示,我们可以利用拿到的Wikipedia文本文件,生成TextTable表格,然后提取Hyperlinks超链接,使用PageRank算法来计算网页之间的相关性和重要性,然后提取Top20Pages,这种计算方式也广泛的应用与搜索引擎中,当你在浏览器中搜索某一个关键字,它会使用分词算法提取关键字,使用文本相似度算法获取所有与此关联的网页信息,然后使用图计算算法计算网页超链接之间的联系,推荐给你相关性最强的前20个网页链接。
对于图计算更多的应用,在后面的文章中会具体讲述。
GraphX介绍
1.发展历程

GraphX的特点是离线计算,批量处理,基于同步的BSP模型(Bulk Synchronous Parallel Computing Model,整体同步并行计算模型),这样的优势在于可以提升数据处理的吞吐量和规模,但在速度会稍逊一筹。目前大规模图处理框架还有基于MPI模型的异步图计算模型GraphLab和同样基于BSP模型的Graph等。
与GraphX可以组合使用的分布式图数据库Neo4J。Neo4J是一个 高性能的、非关系、具有完全事务特性的、鲁棒的图数据库。另一个数据库是Titan,Titan是一个分布式的图形数据库,特别为存储和处理大数据图形而优化,它们都可以作为GraphX的持久层,存储大规模图数据。
2.GraphX架构
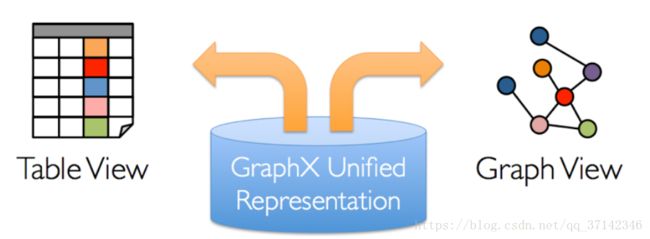
上面提到,Spark的每一个模块,都有自己的抽象数据结构,GraphX的核心抽象是弹性分布式属性图(resilient distribute property graph),一种点和边都带有属性的有向多重图。它同时拥有Table和Graph两种视图,而只需一种物理存储,这两种操作符都有自己独有的操作符,从而获得灵活的操作和较高的执行效率。

GraphX的整体架构可以分为三个部分:
- 存储层和原语层:Graph类是图计算的核心类,内部含有VertexRDD、EdgeRDD和RDD[EdgeTriplet]引用。GraphImpl是Graph类的子类,实现了图操作。
- 接口层:在底层RDD的基础之上实现Pragel模型,BSP模式的计算接口。
- 算法层:基于Pregel接口实现了常用的图算法。包含:PageRank、SVDPlusPlus、TriangleCount、ConnectedComponents、StronglyConnectedConponents等算法。
3.存储结构
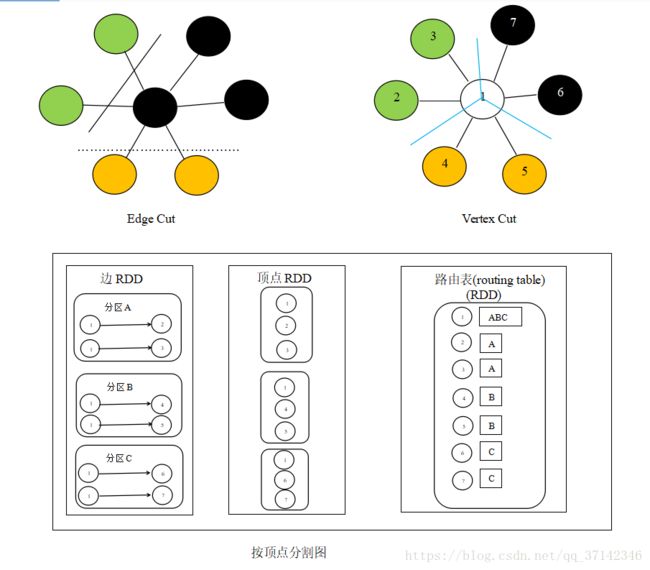
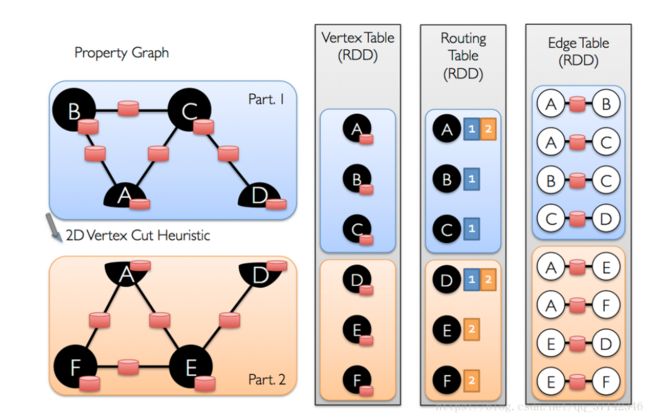
在工业级的应用中,图的规模很大,为了提高处理的速度和数据量,我们希望使用分布式的方式来存储,处理图数据。图的分布式存储大致有两种方式,边分割(Edge Cut),点分割(Vertex Cut),在早期的图计算框架中,使用的是边分割的存储方式,后期考虑到真实世界中大规模图大多是边多于点的图,所以采用点分割方式来存储。点分割能减少网络传输和存储开销,底层实现是将边放到各个节点存储,而进行数据交换的时候将点在各个机器之间广播进行传输。对于边的存储和分区算法主要基于PartitionStrategy中封装的分区方法,用户可以根据具体的需求 进行分区方式的选择,可以在程序中指定边的分区方式。如:
val graph=Graph(vertices,partitionBy(edges,PartitionStrategy.EdgePartition2D))
当边在集群中分布式存储的时候,在有些场景中,我们需要使用顶点的属性,因此,需要点的属性连接到边,那么如何将顶点在集群中传播移动呢?GraphX内部维持了一个路由表(routing table),这样当广播点的边的所在区时就可以通过路由表映射,将需要的带你属性传输到边分区。
使用点分割,好处在于边上没有冗余的数据,而且对于某个点与它的邻居的交互操作,只要满足交换律和结合律即可。不过点分割这样做的代价是有的顶点的属性可能要冗余存储多份,更新点数据时要有数据同步开销。
如下图是官方的介绍图:
4.GraphX编程
GraphX内部提供了三种RDD来对一个有向多重图的属性进行描述。VertexRDD和EdgeRDD都继承于RDD,因此,属性图具有不可变。分布式。容错的特点。属性图的每一个顶点由具有64位长度的唯一标识符(VertexID)作为主键,GraphX对顶点的顺序添加任何约束,每一条边都有相应的源顶点(srcVertex),目标顶点(dstVertex)。对于属性图的改变时通过生成新的图完成的,原图的主要部分(属性和索引)会被重用,通过启发式执行顶点分区,在不同的执行器中进行顶点的划分。与RDD一样,当发生故障的时候 ,图中的每个分区都可以重建。
VertexRDD[A]表示具有A属性的顶点集合。在内部将顶点的属性集合使用一个可重复使用的暗哈希表来存储,因此当两个VertexRDD继承自同一个VertexRDD的时候,它们可以在常数时间内进行合并操作,而不需要重新去计算哈希值。VertexRDD源码如下:
abstract class VertexRDD[VD](sc : org.apache.spark.SparkContext, deps : scala.Seq[org.apache.spark.Dependency[_]]) extends org.apache.spark.rdd.RDD[scala.Tuple2[org.apache.spark.graphx.VertexId, VD]] {
protected implicit def vdTag : scala.reflect.ClassTag[VD]
private[graphx] def partitionsRDD : org.apache.spark.rdd.RDD[org.apache.spark.graphx.impl.ShippableVertexPartition[VD]]
protected override def getPartitions : scala.Array[org.apache.spark.Partition] = { /* compiled code */ }
override def compute(part : org.apache.spark.Partition, context : org.apache.spark.TaskContext) : scala.Iterator[scala.Tuple2[org.apache.spark.graphx.VertexId, VD]] = { /* compiled code */ }
def reindex() : org.apache.spark.graphx.VertexRDD[VD]
private[graphx] def mapVertexPartitions[VD2](f : scala.Function1[org.apache.spark.graphx.impl.ShippableVertexPartition[VD], org.apache.spark.graphx.impl.ShippableVertexPartition[VD2]])(implicit evidence$1 : scala.reflect.ClassTag[VD2]) : org.apache.spark.graphx.VertexRDD[VD2]
override def filter(pred : scala.Function1[scala.Tuple2[org.apache.spark.graphx.VertexId, VD], scala.Boolean]) : org.apache.spark.graphx.VertexRDD[VD] = { /* compiled code */ }
def mapValues[VD2](f : scala.Function1[VD, VD2])(implicit evidence$2 : scala.reflect.ClassTag[VD2]) : org.apache.spark.graphx.VertexRDD[VD2]
def mapValues[VD2](f : scala.Function2[org.apache.spark.graphx.VertexId, VD, VD2])(implicit evidence$3 : scala.reflect.ClassTag[VD2]) : org.apache.spark.graphx.VertexRDD[VD2]
def diff(other : org.apache.spark.graphx.VertexRDD[VD]) : org.apache.spark.graphx.VertexRDD[VD]
def leftZipJoin[VD2, VD3](other : org.apache.spark.graphx.VertexRDD[VD2])(f : scala.Function3[org.apache.spark.graphx.VertexId, VD, scala.Option[VD2], VD3])(implicit evidence$4 : scala.reflect.ClassTag[VD2], evidence$5 : scala.reflect.ClassTag[VD3]) : org.apache.spark.graphx.VertexRDD[VD3]
def leftJoin[VD2, VD3](other : org.apache.spark.rdd.RDD[scala.Tuple2[org.apache.spark.graphx.VertexId, VD2]])(f : scala.Function3[org.apache.spark.graphx.VertexId, VD, scala.Option[VD2], VD3])(implicit evidence$6 : scala.reflect.ClassTag[VD2], evidence$7 : scala.reflect.ClassTag[VD3]) : org.apache.spark.graphx.VertexRDD[VD3]
def innerZipJoin[U, VD2](other : org.apache.spark.graphx.VertexRDD[U])(f : scala.Function3[org.apache.spark.graphx.VertexId, VD, U, VD2])(implicit evidence$8 : scala.reflect.ClassTag[U], evidence$9 : scala.reflect.ClassTag[VD2]) : org.apache.spark.graphx.VertexRDD[VD2]
def innerJoin[U, VD2](other : org.apache.spark.rdd.RDD[scala.Tuple2[org.apache.spark.graphx.VertexId, U]])(f : scala.Function3[org.apache.spark.graphx.VertexId, VD, U, VD2])(implicit evidence$10 : scala.reflect.ClassTag[U], evidence$11 : scala.reflect.ClassTag[VD2]) : org.apache.spark.graphx.VertexRDD[VD2]
def aggregateUsingIndex[VD2](messages : org.apache.spark.rdd.RDD[scala.Tuple2[org.apache.spark.graphx.VertexId, VD2]], reduceFunc : scala.Function2[VD2, VD2, VD2])(implicit evidence$12 : scala.reflect.ClassTag[VD2]) : org.apache.spark.graphx.VertexRDD[VD2]
def reverseRoutingTables() : org.apache.spark.graphx.VertexRDD[VD]
def withEdges(edges : org.apache.spark.graphx.EdgeRDD[_]) : org.apache.spark.graphx.VertexRDD[VD]
private[graphx] def withPartitionsRDD[VD2](partitionsRDD : org.apache.spark.rdd.RDD[org.apache.spark.graphx.impl.ShippableVertexPartition[VD2]])(implicit evidence$13 : scala.reflect.ClassTag[VD2]) : org.apache.spark.graphx.VertexRDD[VD2]
private[graphx] def withTargetStorageLevel(targetStorageLevel : org.apache.spark.storage.StorageLevel) : org.apache.spark.graphx.VertexRDD[VD]
private[graphx] def shipVertexAttributes(shipSrc : scala.Boolean, shipDst : scala.Boolean) : org.apache.spark.rdd.RDD[scala.Tuple2[org.apache.spark.graphx.PartitionID, org.apache.spark.graphx.impl.VertexAttributeBlock[VD]]]
private[graphx] def shipVertexIds() : org.apache.spark.rdd.RDD[scala.Tuple2[org.apache.spark.graphx.PartitionID, scala.Array[org.apache.spark.graphx.VertexId]]]
}
在它的内部提供了很多常用的操作。例如上面的mapValues操作不允许map函数改变VertexID,从而可以复用HashMap中的数据结构。
EdgeRDD[ED,VD]继承自RDD[Edge[ED]],以各种分区策略(PartitionStrategy)将边划分为不同的块。在每个分区中,边属性和邻接结构分别存储,这使得更改属性值的时候能够实现最大限度的复用。其源码如下:
abstract class EdgeRDD[ED](sc : org.apache.spark.SparkContext, deps : scala.Seq[org.apache.spark.Dependency[_]]) extends org.apache.spark.rdd.RDD[org.apache.spark.graphx.Edge[ED]] {
private[graphx] def partitionsRDD : org.apache.spark.rdd.RDD[scala.Tuple2[org.apache.spark.graphx.PartitionID, org.apache.spark.graphx.impl.EdgePartition[ED, VD]]] forSome {type VD}
protected override def getPartitions : scala.Array[org.apache.spark.Partition] = { /* compiled code */ }
override def compute(part : org.apache.spark.Partition, context : org.apache.spark.TaskContext) : scala.Iterator[org.apache.spark.graphx.Edge[ED]] = { /* compiled code */ }
//改变属性,保留邻接结构
def mapValues[ED2](f : scala.Function1[org.apache.spark.graphx.Edge[ED], ED2])(implicit evidence$1 : scala.reflect.ClassTag[ED2]) : org.apache.spark.graphx.EdgeRDD[ED2]
//改变边的方向
def reverse : org.apache.spark.graphx.EdgeRDD[ED]
def innerJoin[ED2, ED3](other : org.apache.spark.graphx.EdgeRDD[ED2])(f : scala.Function4[org.apache.spark.graphx.VertexId, org.apache.spark.graphx.VertexId, ED, ED2, ED3])(implicit evidence$2 : scala.reflect.ClassTag[ED2], evidence$3 : scala.reflect.ClassTag[ED3]) : org.apache.spark.graphx.EdgeRDD[ED3]
private[graphx] def withTargetStorageLevel(targetStorageLevel : org.apache.spark.storage.StorageLevel) : org.apache.spark.graphx.EdgeRDD[ED]
}
除了上面两种RDD之外,还有一种RDD结构为Triplet,它相当于在EdgeRDD的结构上加上了点的属性,对于Triplet,官方给出了详细的介绍,如下图所示:

Triplet的源码如下:
class EdgeTriplet[VD, ED]() extends org.apache.spark.graphx.Edge[ED] {
var srcAttr : VD = { /* compiled code */ }
var dstAttr : VD = { /* compiled code */ }
protected[spark] def set(other : org.apache.spark.graphx.Edge[ED]) : org.apache.spark.graphx.EdgeTriplet[VD, ED] = { /* compiled code */ }
def otherVertexAttr(vid : org.apache.spark.graphx.VertexId) : VD = { /* compiled code */ }
def vertexAttr(vid : org.apache.spark.graphx.VertexId) : VD = { /* compiled code */ }
override def toString() : java.lang.String = { /* compiled code */ }
def toTuple : scala.Tuple3[scala.Tuple2[org.apache.spark.graphx.VertexId, VD], scala.Tuple2[org.apache.spark.graphx.VertexId, VD], ED] = { /* compiled code */ }
}
同VertexRDD和EdgeRDD类似的,它也提供了多种常用的操作,对于这些详细的使用方式,在后期的文章中会详解介绍到,欢迎关注。
参考文献:
《Spark核心技术与高级应用》
《Spark大数据 分析实战》
Spark GraphX官方文档
如果你想和我们一起探讨技术,共同进步,欢迎加群: