理解tfrecord读取数据——错误OutOfRangeError (see above for traceback)的解决
转载自:TFRecord读取数据
前言
关于Tensorflow读取数据,官网给出了三种方法:
- 供给数据(Feeding): 在TensorFlow程序运行的每一步, 让Python代码来供给数据。
- 从文件读取数据: 在TensorFlow图的起始, 让一个输入管线从文件中读取数据。
- 预加载数据: 在TensorFlow图中定义常量或变量来保存所有数据(仅适用于数据量比较小的情况)。
使用Tensorflow训练神经网络时,我们可以用多种方式来读取自己的数据。如果数据集比较小,而且内存足够大,可以选择直接将所有数据读进内存,然后每次取一个batch的数据出来。如果数据较多,可以每次直接从硬盘中进行读取,不过这种方式的读取效率就比较低了。此篇博客就主要讲一下Tensorflow官方推荐的一种较为高效的数据读取方式——tfrecord。
从宏观来讲,tfrecord其实是一种数据存储形式。使用tfrecord时,实际上是先读取原生数据,然后转换成tfrecord格式,再存储在硬盘上。而使用时,再把数据从相应的tfrecord文件中解码读取出来。那么使用tfrecord和直接从硬盘读取原生数据相比到底有什么优势呢?其实,Tensorflow有和tfrecord配套的一些函数,可以加快数据的处理。实际读取tfrecord数据时,先以相应的tfrecord文件为参数,创建一个输入队列,这个队列有一定的容量(视具体硬件限制,用户可以设置不同的值),在一部分数据出队列时,tfrecord中的其他数据就可以通过预取进入队列,并且这个过程和网络的计算是独立进行的。也就是说,网络每一个iteration的训练不必等待数据队列准备好再开始,队列中的数据始终是充足的,而往队列中填充数据时,也可以使用多线程加速。
1. tfrecord格式简介
tfrecord文件中的数据是通过tf.train.Example Protocol Buffer的格式存储的,下面是tf.train.Example的定义
message Example {
Features features = 1;
};
message Features{
map featrue = 1;
};
message Feature{
oneof kind{
BytesList bytes_list = 1;
FloatList float_list = 2;
Int64List int64_list = 3;
}
}; 上述代码可以看出,tf.train.Example 的数据结构很简单。tf.train.Example中包含了一个从属性名称到取值的字典,其中属性名称为一个字符串,属性的取值可以为字符串(BytesList ),浮点数列表(FloatList )或整数列表(Int64List )。例如我们可以将图片转换为字符串进行存储,图像对应的类别标号作为整数存储,而用于回归任务的ground-truth可以作为浮点数存储。通过后面的代码我们会对tfrecord的这种字典形式有更直观的认识。
2.用自己的数据生成对应tfrecord文件
例子:
# !usr/bin/env python3
# -*- coding:utf-8 -*-
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
from scipy import misc
import scipy.io as sio
# 这两个函数(_bytes_feature和_int64_feature)是将我们的原生数据进行转换用的,
# 尤其是图片要转换成字符串再进行存储。这两个函数的定义来自官方的示例。
def _bytes_feature(value):
return tf.train.Feature(bytes_list=tf.train.BytesList(value=[value]))
def _int64_feature(value):
return tf.train.Feature(int64_list=tf.train.Int64List(value=[value]))
data_path = './Data/'
tfrecords_filename = data_path+'train.tfrecords'
# 创建一个TFRecordWriter实例,相当于待会写数据的入口
writer = tf.python_io.TFRecordWriter(tfrecords_filename)
# img_height = 32
# img_width = 32
# sio.loadmat(test.mat)
txtfile = data_path + 'train.txt'
fr = open(txtfile)
for i in fr.readlines():
item = i.split()
# train.txt文件内容格式:F:\ShenKH\VSCode\TFRecord\Data\0_10.jpg
label = i.split('\\')[-1].split('_')[0]
img = np.float64(misc.imread(item[0]))
# print(label)
# print(item[0])
oriImage_height, oriImage_width, oriImage_depth = img.shape
# print(img.shape)
img_raw = img.tostring()
example = tf.train.Example(features=tf.train.Features(feature={
'height': _int64_feature(oriImage_height),
'width': _int64_feature(oriImage_width),
'label': _int64_feature(int(label)),
'image_raw': _bytes_feature(img_raw)}
))
writer.write(example.SerializeToString())
writer.close()
fr.close()
print('done')import tensorflow as tf
import os
TFRECORD_PATH = 'D:\\skin_leson_data\\Validation\\flip_valid_add-two_tfrecord\\valid_flip_addTWOoption.tfrecords'
#图片存放位置
images_dir = 'D:\\skin_leson_data\\Validation\\flip_Valid_resized_256_200'
annotations_dir = 'D:\\skin_leson_data\\Validation\\flip_valid_add-two-option-gt'
# 1.定义一个将已有的数据转换成Feature数据结构的函数(官方教程中的函数)
def _bytes_feature(value):
return tf.train.Feature(bytes_list=tf.train.BytesList(value=[value]))
# def _int64_feature(value):
# return tf.train.Feature(int64_list=tf.train.Int64List(value=[value]))
# 获取文件列表
files_img = tf.gfile.Glob(os.path.join(images_dir,'*.jpg')) # 列出images_dir下所有jpg文件路径
files_anno = tf.gfile.Glob(os.path.join(annotations_dir,'*.png')) # 列出annotations_dir下所有png文件路径
print(len(files_img))
print(len(files_anno))
# 4.定义一个TFRecord的writer
# 创建一个TFRecordWriter实例,相当于待会写数据的入口
writer = tf.python_io.TFRecordWriter(TFRECORD_PATH)
# 5.逐个文件来写入TFRecoder文件
for i in range(len(files_img)):
print(i)
# 这里可能有些教程里会使用skimage或者opencv来读取文件,但是我试了一下opencv的方法
# 一个400MB左右的训练集先用cv2.imread转换成numpy数组再转成string,最后写入TFRecord
# 得到的文件有17GB,所以这里推荐使用FastGFile方法,生成的tfrecord文件会变小,
# 唯一不好的一点就是这种方法需要在读取之后再进行一次解码。
img = tf.gfile.FastGFile(files_img[i], 'rb').read()
anno = tf.gfile.FastGFile(files_anno[i], 'rb').read()
# 按照第一部分中Example Protocol Buffer的格式来定义要存储的数据格式
example = tf.train.Example(features=tf.train.Features(feature={
'raw_image': _bytes_feature(img),
'anno': _bytes_feature(anno)
}))
# 最后将example写入TFRecord文件
writer.write(example.SerializeToString())
writer.close()3.从tfrecord文件读取数据及测试
例子:
from scipy import misc
import tensorflow as tf
import numpy as np
import scipy.io as sio
import matplotlib.pyplot as plt
tfrecord_filename = './Data/train.tfrecords'
def read_and_decode(filename_queue, random_crop=False,
random_clip=False, shuffle_batch=True):
reader = tf.TFRecordReader()
_, serialized_example = reader.read(filename_queue)
features = tf.parse_single_example(
serialized_example, features={
'height': tf.FixedLenFeature([], tf.int64),
'width': tf.FixedLenFeature([], tf.int64),
'label': tf.FixedLenFeature([], tf.int64),
'image_raw': tf.FixedLenFeature([], tf.string)
}
)
image = tf.decode_raw(features['image_raw'], tf.float64)
height = tf.cast(features['height'], tf.int32)
# width = features['width']
width = tf.cast(features['width'], tf.int32)
label = tf.cast(features['label'], tf.int32)
image = tf.reshape(image, [32, 32, 3])
if shuffle_batch:
images, labels, widths, heights = tf.train.shuffle_batch(
[image, label, width, height],
batch_size=4,
num_threads=2,
capacity=100,
min_after_dequeue=2)
else:
images, labels, widths, heights = tf.train.batch(
[image, label, width, height],
batch_size=4,
num_threads=2,
capacity=100)
return images, labels, widths, heights
def test_run(tfrecord_filename):
# 用tfrecord文件创建一个输入队列
filename_queue = tf.train.string_input_producer([tfrecord_filename],
num_epochs=10)
images, labels, widths, heights = read_and_decode(
filename_queue, shuffle_batch=False)
with tf.Session() as sess:
tf.global_variables_initializer().run()
tf.local_variables_initializer().run()
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
for i in range(1):
img, lab, wid, hei = sess.run([images, labels, widths, heights])
print('batch' + str(i) + ':')
print(wid)
print(lab)
# print('width:%d \n', wid[i])
plt.imshow(img[i])
plt.show()
coord.request_stop()
coord.join(threads)
test_run(tfrecord_filename)def read_tfrecord(tfrecord_file):
# 1. 把所有的TFRecord文件名列表写入队列中(只有一个就写一个文件名在列表中,多个就写多个)
# queue = tf.train.string_input_producer([tfrecord_file], shuffle=True)
queue = tf.train.string_input_producer([tfrecord_file])
# 2. 创建一个读取器
reader = tf.TFRecordReader()
# 3. 将队列中的tfrecord文件读取为example格式
_, serialized_example = reader.read(queue)
# 4. 根据定义数据的方式对应说明读取的方式
features = tf.parse_single_example(
serialized_example,features={
'raw_image': tf.FixedLenFeature([], tf.string),
'anno': tf.FixedLenFeature([], tf.string)
}
)
img = features['raw_image']
anno= features['anno']
# 5. 对图片进行解码
img = tf.image.decode_jpeg(img, channels=3)
anno= tf.image.decode_png(anno, channels=1)
return img, anno
def load_skinlesion(self, sess, count, height, width):
# Add images,annotations
images, annotations= read_tfrecord(TRAIN_FILE)
i = 0
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(coord=coord)
try:
while not coord.should_stop() and i < count:
image, annotation = sess.run([images, annotations])
self.add_image("skin lesions", image_id=i, path=None,
width=width, height=height, image=image,
mask=annotation)
i += 1
except tf.errors.OutOfRangeError:
print('done!')
finally:
coord.request_stop()
coord.join(threads)取tfrecord文件中的数据主要是应用read_and_decode()这个函数,可以看到其中有个参数是filename_queue,其实我们并不是直接从tfrecord文件进行读取,而是要先利用tfrecord文件创建一个输入队列,如本文开头所述那样。关于这点,到后面真正的测试代码我再介绍。
在read_and_decode()中,一上来我们先定义一个reader对象,然后使用reader得到serialized_example,这是一个序列化的对象,接着使用tf.parse_single_example()函数对此对象进行初步解析。从代码中可以看到,解析时,我们要用到之前定义的那些键。对于图像这种转换成字符串的数据,要进一步使用tf.decode_raw()函数进行解析,这里要特别注意函数里的第二个参数,也就是解析后的类型。之前图片在转成字符串之前是什么类型的数据,那么这里的参数就要填成对应的类型,否则会报错。对于label、width、height这样的数据就不用再解析了,我们得到的features对象就是个字典,利用键就可以拿到对应的值,如代码所示。
在实际测试的时候
从TFRecords文件中读取数据, 首先需要用tf.train.string_input_producer生成一个解析队列。之后调用tf.TFRecordReader的tf.parse_single_example解析器。如下图:
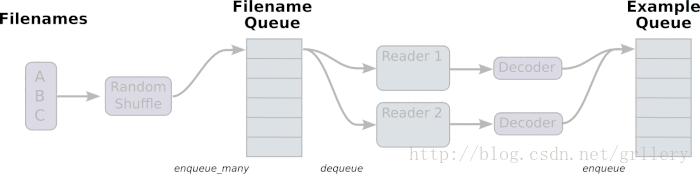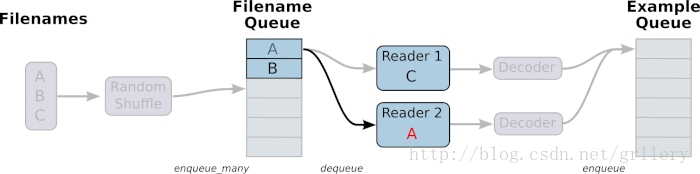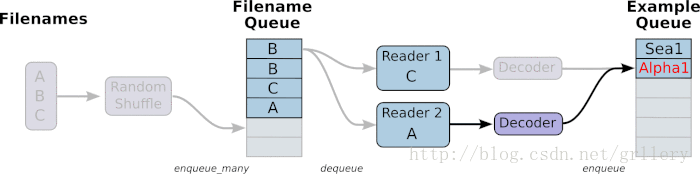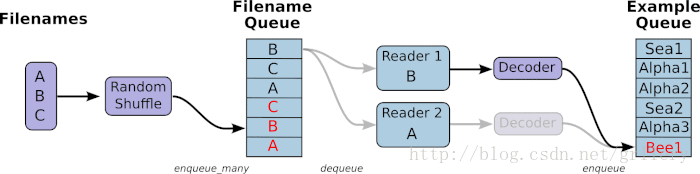
解析器首先读取解析队列,返回serialized_example对象,之后调用tf.parse_single_example操作将Example协议缓冲区(protocol buffer)解析为张量。
使用tf.train函数添加QueueRunner到tensorflow中。在运行任何训练步骤之前,需要调用tf.train.start_queue_runners函数,否则tensorflow将一直挂起。
tf.train.start_queue_runners 这个函数将会启动输入管道的线程,填充样本到队列中,以便出队操作可以从队列中拿到样本。这种情况下最好配合使用一个tf.train.Coordinator,这样可以在发生错误的情况下正确地关闭这些线程。如果你对训练迭代数做了限制,那么需要使用一个训练迭代数计数器,并且需要被初始化。
推荐的代码模板如下:
# Create the graph, etc.
init_op = tf.initialize_all_variables()
# Create a session for running operations in the Graph.
sess = tf.Session()
# Initialize the variables (like the epoch counter).
sess.run(init_op)
# Start input enqueue threads.
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
try:
while not coord.should_stop():
# Run training steps or whatever
sess.run(train_op)
except tf.errors.OutOfRangeError:
print 'Done training -- epoch limit reached'
finally:
# When done, ask the threads to stop.
coord.request_stop()
# Wait for threads to finish.
coord.join(threads)
sess.close()在tf.train中要创建这些队列和执行入队操作,就要添加QueueRunner到一个使用tf.train.add_queue_runner函数的数据流图中。每个QueueRunner负责一个阶段,处理那些需要在线程中运行的入队操作的列表。一旦数据流图构造成功,tf.train.start_queue_runners函数就会要求数据流图中每个QueueRunner去开始它的线程运行入队操作。
在执行训练的时候,队列会被后台的线程填充好。如果设置了最大训练迭代数(epoch),在某些时候,样本出队的操作可能会抛出一个tf.OutOfRangeError的错误。这是因为tensorflow的队列已经到达了最大实际的最大迭代数,没有更多可用的样本了。这也是为何推荐代码模板需要用try..except ..finally结构来处理这种错误。
参考链接:
http://blog.csdn.net/u010358677/article/details/70544241
https://www.jianshu.com/p/78467f297ab5
https://wxinlong.github.io/2017/05/13/tfrecords/
其他
若出现以下错误:
OutOfRangeError (see above for traceback): RandomShuffleQueue '_2_shuffle_batch/random_shuffle_queue' is closed and has insufficient elements (requested 100, current size 0)
[[Node: shuffle_batch = QueueDequeueManyV2[component_types=[DT_DOUBLE, DT_INT64, DT_INT64], timeout_ms=-1, _device="/job:localhost/replica:0/task:0/device:CPU:0"](shuffle_batch/random_shuffle_queue, shuffle_batch/n)]]检查是否是缺少以下代码引起的:
tf.local_variables_initializer().run()