基于BiLSTM的对话文本情感分析
个人博客:http://www.chenjianqu.com/
原文链接:http://www.chenjianqu.com/show-38.html
文本情感分析
文本情感分析:又称意见挖掘、倾向性分析等。简单而言,是对带有情感色彩的主观性文本进行分析、处理、归纳和推理的过程。互联网(如博客和论坛以及社会服务网络如大众点评)上产生了大量的用户参与的、对于诸如人物、事件、产品等有价值的评论信息。这些评论信息表达了人们的各种情感色彩和情感倾向性,如喜、怒、哀、乐和批评、赞扬等。基于此,潜在的用户就可以通过浏览这些主观色彩的评论来了解大众舆论对于某一事件或产品的看法。
本文是针对的是对话文本的情感分析。
BiLSTM
BiLSTM是Bi-directional Long Short-Term Memory的缩写,是由前向LSTM与后向LSTM组合而成。LSTM的全称是Long Short-Term Memory,它是RNN(Recurrent Neural Network)的一种。LSTM由于其设计的特点,非常适合用于对时序数据的建模,如文本数据。关于LSTM详细请看文章《RNN、LSTM、GRU的原理和实现》。
前向的LSTM与后向的LSTM结合成BiLSTM。比如,我们对“我爱中国”这句话进行编码,模型如下图所示。
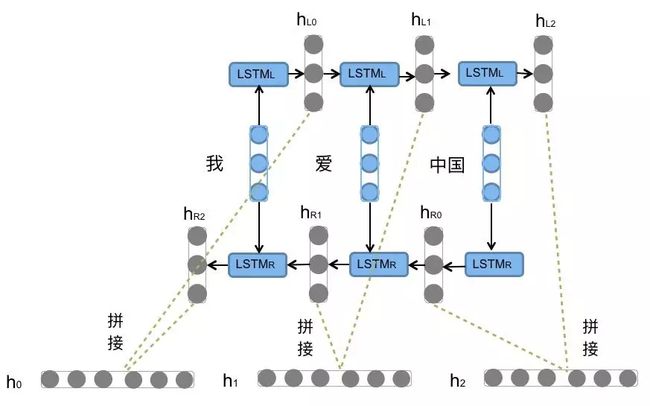
前向的LSTML依次输入“我”,“爱”,“中国”得到三个向量{hL0, hL1, hL2}。后向的LSTMR依次输入“中国”,“爱”,“我”得到三个向量{hR0, hR1, hR2}。最后将前向和后向的隐向量进行拼接得到{[hL1, hL2], [hL1, hR1], [hL2, hR2]},即{h0, h1, h2}。
对于情感分类任务来说,我们采用的句子的表示往往是[hL2, hR2]。因为其包含了前向与后向的所有信息,如图所示。
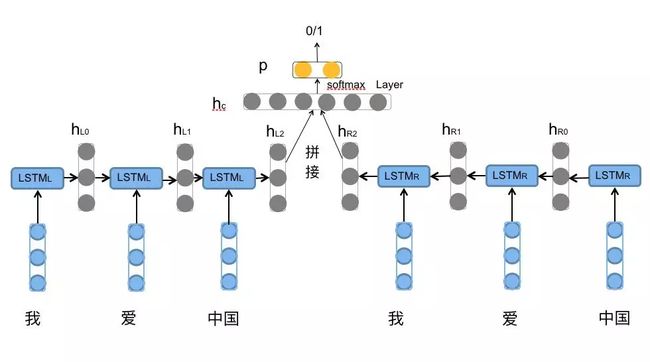
模型架构

训练的模型架构:
数据集
数据集来自github:https://github.com/z17176/Chinese_conversation_sentiment和CSDN。
模型训练
-
读取数据集1
import os
DATASET_PATH_POS=r'D:\AI\NLP\Corpus\polarity\C_01positive'
DATASET_PATH_NEU=r'D:\AI\NLP\Corpus\polarity\C_03neutral'
DATASET_PATH_NEG=r'D:\AI\NLP\Corpus\polarity\C_02negative'
texts=[]
labels=[]
#积极
for fname in os.listdir(DATASET_PATH_POS):
if(fname[-4:]=='.txt'):
f=open(os.path.join(DATASET_PATH_POS,fname),encoding='gbk')
t=f.read()
ts=t.split('\n')
for s in ts:
if(len(s)<2):
continue
s=s.replace(':',':')
n=s.split(':')
n=n[1:]
texts.append(''.join(n))
labels.append(1)
f.close()
DATA_PATH=''
#消极
for fname in os.listdir(DATASET_PATH_NEG):
if(fname[-4:]=='.txt'):
f=open(os.path.join(DATASET_PATH_NEG,fname),encoding='gbk')
t=f.read()
ts=t.split('\n')
for s in ts:
if(len(s)<2):
continue
s=s.replace(':',':')
n=s.split(':')
n=n[1:]
texts.append(''.join(n))
labels.append(0)
f.close()
#中性
for fname in os.listdir(DATASET_PATH_NEU):
if(fname[-4:]=='.txt'):
f=open(os.path.join(DATASET_PATH_NEU,fname))
t=f.read()
ts=t.split('\n')
for s in ts:
if(len(s.strip())<2):
continue
s=s.replace(':',':')
n=s.split(':')
n=n[1:]
texts.append(''.join(n))
labels.append(0.5)
f.close()
print(len(texts))2.读取数据集2
本数据集已经分好词了。
import os
DATASET_PATH=r'D:\AI\NLP\Corpus\Chinese_conversation_sentiment-master\Chinese_conversation_sentiment-master'
texts_splited=[]
labels_splited=[]
for fname in os.listdir(DATASET_PATH):
if(fname[-4:]=='.txt'):
f=open(os.path.join(DATASET_PATH,fname),encoding='utf-8')
lines=f.readlines()
for line in lines:
sa=line.split(',')
if(sa[0]=='negative'):
texts_splited.append(sa[1].replace('\n',''))
labels_splited.append(0)
elif(sa[0]=='positive'):
texts_splited.append(sa[1].replace('\n',''))
labels_splited.append(1)
f.close()
print(len(texts_splited))
print(len(labels_splited))3.读取停用词
对于对话文本来说,单个文本本身的词数很少,因此停用词选择尤为重要。
with open('stopwords.txt', encoding='utf-8') as file:
words = file.readlines()
stop_words = [word.strip().replace('\n', '') for word in words]
print(len(stop_words))4.文本预处理
import jieba
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
import numpy as np
MAX_WORDS=100000 #使用100000个词语
MAX_LEN=100 #每条评论的长度
#将句子分词并用空格隔开
textList=[' '.join([w for w in jieba.cut(text) if w not in stop_words]) for text in texts]
textList=textList+texts_splited
labels=labels+labels_splited
tokenizer=Tokenizer(num_words=MAX_WORDS)
tokenizer.fit_on_texts(texts=textList)
sequences=tokenizer.texts_to_sequences(texts=textList)
word_index=tokenizer.word_index
data=pad_sequences(sequences=sequences,maxlen=MAX_LEN)
labels=np.asarray(labels)5.保存字典
保存分词器的词和序号映射词典。
f = open('word_index.txt','w',encoding='utf-8')
f.write(str(word_index))
f.close()6.划分训练集、验证集、测试集
#各数据集数量
ALL_SAMPLES=len(data)
TRAIN_SAMPLES=int(0.8*ALL_SAMPLES)
VALIDATION_SAMPLES=int(0.1*ALL_SAMPLES)
TEST_SAMPLES=int(0.1*ALL_SAMPLES)
#打乱数据集
indices=np.arange(data.shape[0])
np.random.shuffle(indices)
data=data[indices]
labels=labels[indices]
x_train=data[:TRAIN_SAMPLES]
y_train=labels[:TRAIN_SAMPLES]
x_val=data[TRAIN_SAMPLES:TRAIN_SAMPLES+VALIDATION_SAMPLES]
y_val=labels[TRAIN_SAMPLES:TRAIN_SAMPLES+VALIDATION_SAMPLES]
x_test=data[TRAIN_SAMPLES+VALIDATION_SAMPLES:]
y_test=labels[TRAIN_SAMPLES+VALIDATION_SAMPLES:]7.解析词向量文件
本次使用的词向量和上次的文章(http://www.chenjianqu.com/show-36.html)里面使用的词向量是同一个。
embeddings_index={}
f=open('sgns.zhihu.word',encoding='utf-8')
for line in f:
values=line.split()
word=values[0]#第一个是单词
coefs=np.asarray(values[1:],dtype='float32')#后面都是系数
embeddings_index[word]=coefs
f.close()
print(len(embeddings_index))
print(len(embeddings_index['的']))
#准备词向量矩阵
EMBEDDING_DIM=300#词向量的长度
embedding_matrix=np.zeros((MAX_WORDS,EMBEDDING_DIM))
for word,i in word_index.items():
word_vector=embeddings_index.get(word)
if(word_vector is not None):#若是未登录词,则词向量为初始值0
embedding_matrix[i]=word_vector
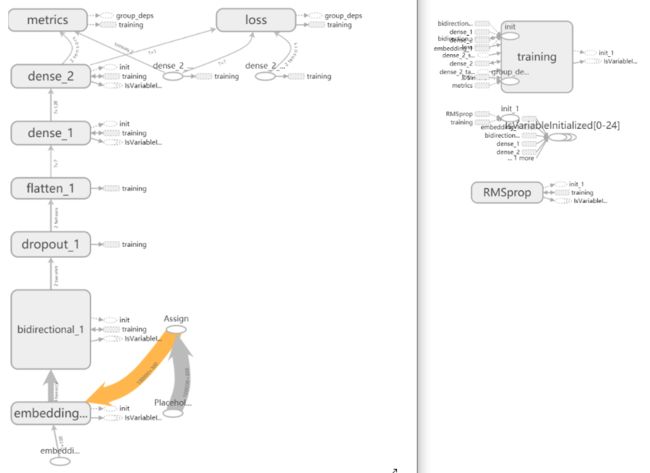
print(embedding_matrix.shape)8.定义模型
代码如下:
#定义模型
from keras.models import Sequential
from keras.layers import *
from keras.utils import plot_model
model=Sequential()
model.add(Embedding(MAX_WORDS,EMBEDDING_DIM,input_length=MAX_LEN))#词嵌入层
#model.add(Conv1D(32,3,activation='relu'))
#model.add(Dropout(rate=0.5))
#model.add(MaxPooling1D(3,padding='valid'))
model.add(Bidirectional(LSTM(128,return_sequences=True),merge_mode='concat'))
model.add(Dropout(0.5))
model.add(Flatten())
model.add(Dense(128,activation='relu'))
model.add(Dense(1,activation='sigmoid'))
model.summary()
plot_model(model,to_file='txtemotion_model.png',show_shapes=True)
#把词嵌入矩阵载入到词嵌入层中
model.layers[0].set_weights([embedding_matrix])
model.layers[0].trainable=False#冻结9.编译并训练模型
import keras
callbacks_list=[
keras.callbacks.EarlyStopping(
monitor='acc',
patience=10,
),
keras.callbacks.ModelCheckpoint(
filepath='txtemotion_model_checkpoint.h5',
monitor='val_loss',#如果val_loss不改善,则不需要覆盖模型文件
save_best_only=True
),
keras.callbacks.TensorBoard(
log_dir='mylog',
histogram_freq=1#每一轮之后记录直方图
)
]
model.compile(optimizer='rmsprop',loss='mse',metrics=['acc','mae'])
history=model.fit(x_train,y_train,
epochs=50,
batch_size=128,
validation_data=(x_val,y_val),
callbacks=callbacks_list
)
model.save_weights('text_emotion_classify.h5')训练结果:
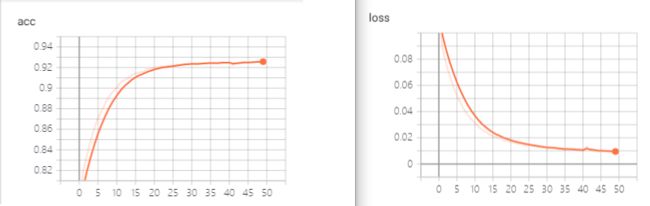

从上图可以看到,训练集在10轮以后就出现了过拟合。
10.测试模型
model.evaluate(x_test,y_test)测试集运行结果:
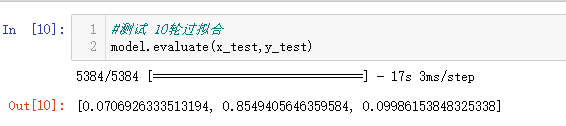
测试精度有0.85左右,并不是很高。总结一下测试精度不高的原因:1.数据集质量一般;2.停用词不够好;3.模型参数没有调好。
模型预测
11.载入模型并预测
#加载模型
model.load_weights('text_emotion_classify.h5')
#读取字典
f = open('word_index.txt','r',encoding='utf-8')
dictStr = f.read()
f.close()
tk = eval(dictStr)
#预测
s='今天表扬了我'
sList=[w for w in jieba.cut(s) if w not in stop_words]
print(sList)
input_text=[]
for w in sList:
input_text.append(tk.get(w,1))#1是找不到时的默认值
print(input_text)
input_text=[input_text]
x=pad_sequences(sequences=input_text,maxlen=MAX_LEN)
x=np.array(x)
preds = model.predict(x)
print(preds)预测结果:

再测试一条:

再来一条:

还是能勉强用用哈。
参考文献
[1]百科百科.文本情感分析.https://baike.baidu.com/item/%E6%96%87%E6%9C%AC%E6%83%85%E6%84%9F%E5%88%86%E6%9E%90/19431243?fr=aladdin
[2]哈工大HCIR.BiLSTM介绍及代码实现.https://www.jiqizhixin.com/articles/2018-10-24-13. 2018-10-24