python爬取百度图片
现在python很是火爆,我也忍不住去学习了一下,发现这门语言非常简单,可以用很简单的代码写出很流弊的东西,当然每门语言都有很多坑。我学习了一些基础知识便尝试写了一个爬虫,爬取百度图片,在这里分享一下我的代码。
想要爬取网络上的东西首先要了解网页结构,我们使用百度图片搜索“美女”,我们会发现网页是这样子的:
直接查看网页源代码,发现图片的网址都是这样的:
"objURL":"http://a.hiphotos.baidu.com/baike/c0=baike60,5,5,60,20;t=gif/sign=e8c6820dad4bd11310c0bf603bc6cf6a/d1a20cf431adcbef565a1878acaf2edda3cc9f65.jpg"这还不简单?直接上代码:
from urllib import request
import re
def getHtml(url):
page = request.urlopen(url)
html = page.read()
return html
def getImg(html):
reg = '"objURL":"(.*?)",'
imgre = re.compile(reg)
html = html.decode('utf-8')
print(html)
imglist = re.findall(imgre, html)
print("发现%s个匹配对象"%imglist.__len__())
x = 0
for imgurl in imglist:
request.urlretrieve(imgurl, '%s.jpg' % x)
x+=1
return x
html = getHtml("https://image.baidu.com/search/index?tn=baiduimage&ct=201326592&lm=-1&cl=2&ie=gb18030&word=美女&fr=ala&ala=1&alatpl=adress&pos=0&hs=2&xthttps=111111")
getImg(html)咦?我们发现爬虫爬了一些就不爬了,我们再看一下网页,我们发现它是动态加载的,每下滑一段距离就加载一些图片,没有换页的按钮,那怎么爬呢?我们看一下他的网址:
https://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=index&fr=&hs=0&xthttps=111111&sf=1&fmq=&pv=&ic=0&nc=1&z=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&word=%E7%BE%8E%E5%A5%B3&f=3&oq=meinv&rsp=0
很长,后边跟了一堆不知道什么参数,尝试着把它删掉也不会出什么问题,还是加载原来的界面,我们发现关键的地方只有两个,一个是问好前面的请求网址,另一个就是参数word,有一个办法很简单,你只要把前面的网址换成“https://image.baidu.com/search/flip”,参数和以前一样就能得到下面的网页:
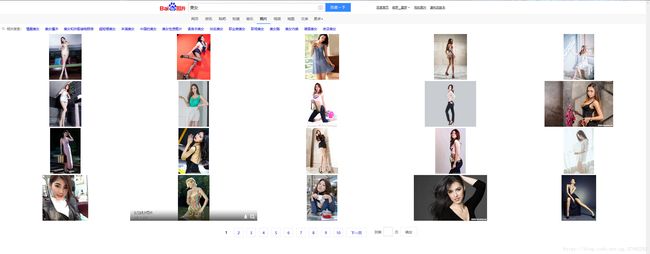
这下子不就是有换页了吗,我们查看网页的代码
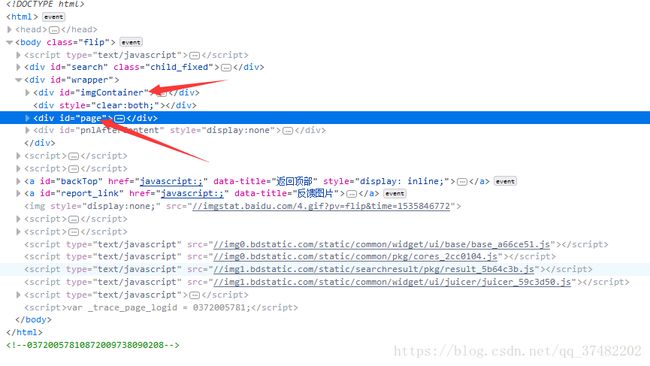
id=imgContainer的是图片容器,id=page的是换页的容器,在里面可以很容易找到下一页所在的位置:

图片位置:
总体流程是这样的:
1.先循环得到所有图片的url
2.循环下载图片
先写一个方法得到一页中所有的图片url并返回下一页图片的url的方法:
def get_onepage_urls(onepageurl):
"""获取单个翻页的所有图片的urls+当前翻页的下一翻页的url"""
if not onepageurl:
print('已到最后一页, 结束')
return [], ''
try:
html = requests.get(onepageurl).text
except Exception as e:
print(e)
pic_urls = []
fanye_url = ''
return pic_urls, fanye_url
#用正则得到所有图片的url和下一页的url
pic_urls = re.findall('"objURL":"(.*?)",', html, re.S)
fanye_urls = re.findall(re.compile(r'下一页'), html, flags=0)
fanye_url = 'http://image.baidu.com' + fanye_urls[0] if fanye_urls else ''
return pic_urls, fanye_url循环下载图片的方法:
def down_pic(pic_urls):
"""给出图片链接列表, 下载所有图片"""
for i, pic_url in enumerate(pic_urls):
try:
pic = requests.get(pic_url, timeout=15)
string = str(i)+ '.jpg'
#写入文件
with open(string, 'wb') as f:
f.write(pic.content)
print('成功下载第%s张图片: %s' % (str(i + 1), str(pic_url)))
except Exception as e:
print('下载第%s张图片时失败: %s' % (str(i + 1), str(pic_url)))
print(e)
continue很简单吧,用request很简单就可以发起请求并得到结果
最后把它们串到一起就好了:
if __name__ == '__main__':
keyword = '美女'
url_init_first = r'http://image.baidu.com/search/flip?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=result&fr=&sf=1&fmq=1497491098685_R&pv=&ic=0&nc=1&z=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&ctd=1497491098685%5E00_1519X735&word='
url_init = url_init_first + request.quote(keyword, safe='/')
#声明一个list用来装图片url
all_pic_urls = []
onepage_urls, fanye_url = get_onepage_urls(url_init)
all_pic_urls.extend(onepage_urls)
fanye_count = 0 # 累计翻页数
#循环添加图片url
while 1:
onepage_urls, fanye_url = get_onepage_urls(fanye_url)
fanye_count += 1
print('第%s页' % fanye_count)
if fanye_url == '' and onepage_urls == []:
break
all_pic_urls.extend(onepage_urls)
#下载图片
down_pic(list(set(all_pic_urls)))就这样就完事了,我也不贴完整代码了,把它们合到一块就是完整的。
回到开头说的地方,对于动态加载的网页我们就没有办法了吗?当然不是,动态加载的网页也是不断请求数据的,我们只要模拟它请求数据的方式就好了,打开网络监视器分析:
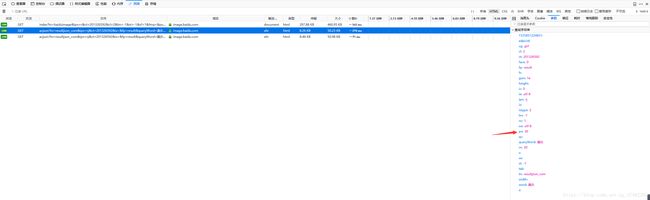

请求带了一堆参数,网页滑来滑去就变动其中几个,最上面是个时间,下面有个gsm不知道啥玩意儿,有规律变化的是pn,每次加30,正好和rn对应,猜测是pageNumber和requestNumber的缩写,改变pn再次请求发现有动静,嗯,就是他了,我们复制网址循环请求就好了,可以得到它的json,解析,就完事了

可以看到这里面数据很全啊,图片url,宽高属性,图片类型,原网址,标签,和上面一样解析一下,下载方法不用变,完事。
不一部分一部分的讲了,直接上代码
import requests
import os
import json
def getManyPages(keyword,pages):
params=[]
for i in range(30,30*pages+30,30):
params.append({
'tn': 'resultjson_com',
'ipn': 'rj',
'ct': 201326592,
'is': '',
'fp': 'result',
'queryWord': keyword,
'cl': 2,
'lm': -1,
'ie': 'utf-8',
'oe': 'utf-8',
'adpicid': '',
'st': -1,
'z': '',
'ic': 0,
'word': keyword,
's': '',
'se': '',
'tab': '',
'width': '',
'height': '',
'face': 0,
'istype': 2,
'qc': '',
'nc': 1,
'fr': '',
'pn': i,
'rn': 30,
'gsm': '1e',
'1488942260214': ''
})
url = 'https://image.baidu.com/search/acjson'
urls = []
for i in params:
try:
urls.append(requests.get(url,params=i).json().get('data'))
except json.decoder.JSONDecodeError:
print("解析出错")
return urls
def getImg(dataList, localPath):
if not os.path.exists(localPath): # 新建文件夹
os.mkdir(localPath)
x = 0
for list in dataList:
for i in list:
if i.get('thumbURL') != None:
print('正在下载:%s' % i.get('thumbURL'))
ir = requests.get(i.get('thumbURL'))
open(localPath + '%d.jpg' % x, 'wb').write(ir.content)
x += 1
else:
print('图片链接不存在')
if __name__ == '__main__':
dataList = getManyPages('美女',10) # 参数1:关键字,参数2:要下载的页数
getImg(dataList,'D:/reptilian/') # 参数2:指定保存的路径