java实现敏感词过滤算法DFA
参考文章:https://blog.csdn.net/chenssy/article/details/26961957
补充说明:
1.具体的DFA介绍参考原文章,此处只是补充了文章中没有介绍的点以及根据实际需求进行了改造
2.最大/小匹配规则:比如说存在两个敏感词[abc,ab],最大规则匹配中abc,最小匹配规则匹配中ab
3.添加自动忽略特殊字符的功能
/**
* 判断是否是要忽略的字符(忽略所有特殊字符以及空格)
* @param specificChar 指定字符
* @return 特殊字符或空格true否则false
*/
private boolean isIgnore(char specificChar){
String regex = "[`~!@#$%^&*()+=|{}':;',\\\\[\\\\].<>/?~!@#¥%……&*()——+|{}【】‘;:”“’。,、?]|\\s*";
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(String.valueOf(specificChar));
return matcher.matches();
}实际业务需求:
一堆敏感词文件,一个词一行,把目录下的所有敏感词文件在启动项目的时候加载进去,并且提供匹配敏感词的方法
优化点:
做到不重启应用更新敏感词库,这个需要进行对敏感词文件的动态监控,然后发生变化后更新DFA树,有时间再研究
实现代码(采用springboot方式实现,其实就是java,但是用的springboot的@PostConstruct注解在启动前加载敏感词库):
package com.holidaylee.util;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.stereotype.Component;
import javax.annotation.PostConstruct;
import java.io.*;
import java.util.HashSet;
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
import java.util.concurrent.ConcurrentHashMap;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* @author : HolidayLee
* @description : 敏感词过滤工具
*/
@Component
public class SensitiveWordCheckUtils {
private final Logger logger = LoggerFactory.getLogger(SensitiveWordCheckUtils.class);
/**
* 最小匹配规则
*/
private final Integer MIN_MATCH_TYPE = 0;
/**
* 最大匹配规则
*/
private final Integer MAX_MATCH_TYPE = -1;
/**
* 敏感词DFA树关系标记key
*/
private final String IS_END = "isEnd";
/**
* 不是敏感词的最后一个字符
*/
private final String END_FALSE = "0";
/**
* 是敏感词的最后一个字符
*/
private final String END_TRUE = "1";
/**
* 所有敏感词DFA树的列表
*/
private Map sensitiveWordMap = null;
/**
* 敏感词文件存放路径
*/
private final String SENSITIVE_WORD_FILE_PATH = "sensitiveWord" + File.separator;
/**
* 敏感词文件默认编码格式
*/
private final String DEFAULT_ENCODING = "utf-8";
/**
* 忽略特殊字符的正则表达式
*/
private final String IGNORE_SPECIAL_CHAR_REGEX = "[`~!@#$%^&*()+=|{}':;',\\\\[\\\\].<>/?~!@#¥%……&*()——+|{}【】‘;:”“’。,、?]|\\s*";
/**
* 启动前将敏感词文件中的敏感词构建成DFA树
*/
@PostConstruct
private void initSensitiveWords() {
sensitiveWordMap = new ConcurrentHashMap();
File dir = new File(SENSITIVE_WORD_FILE_PATH);
if (dir.isDirectory() && dir.exists()) {
for (File file : dir.listFiles()) {
createDFATree(readSensitiveWordFileToSet(file));
logger.info(String.format("将敏感词文件加载到DFA树列表成功{%s}", file));
}
logger.info(String.format("总共构建%s棵DFA敏感词树", sensitiveWordMap.size()));
}else {
throw new RuntimeException(String.format("敏感词文件目录不存在{%s}",dir));
}
}
/**
* 读取文件中的敏感词
*
* @param file 敏感词文件
* @return 敏感词set集合
*/
private Set readSensitiveWordFileToSet(File file) {
Set words = new HashSet<>();
if (file.exists()) {
BufferedReader reader = null;
try {
reader = new BufferedReader(new InputStreamReader(new FileInputStream(file), DEFAULT_ENCODING));
String line = "";
while ((line = reader.readLine()) != null) {
words.add(line.trim());
}
} catch (Exception e) {
e.printStackTrace();
} finally {
if (reader != null) {
try {
reader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
logger.info(String.format("从文件{%s}读取到{%s}个敏感词", file, words.size()));
return words;
}
/**
* 将敏感词构建成DFA树
*{
* 出={
* isEnd=0,
* 售={
* isEnd=0,
* 手={
* isEnd=0,
* 刀={
* isEnd=1
* }
* },
* 军={
* isEnd=0,
* 刀={
* isEnd=1
* }
* }
* }
* }
*}
* @param sensitiveWords 敏感词列表
*/
private void createDFATree(Set sensitiveWords) {
Iterator it = sensitiveWords.iterator();
while (it.hasNext()) {
String word = it.next();
Map currentMap = sensitiveWordMap;
for (int i = 0; i < word.length(); i++) {
char key = word.charAt(i);
if (isIgnore(key)){
continue;
}
Object oldValueMap = currentMap.get(key);
if (oldValueMap == null) {
// 不存在以key字符的DFA树则需要创建一个
Map newValueMap = new ConcurrentHashMap();
newValueMap.put(IS_END, END_FALSE);
currentMap.put(key, newValueMap);
currentMap = newValueMap;
} else {
currentMap = (Map) oldValueMap;
}
if (i == word.length() - 1) {
// 给最后一个字符添加结束标识
currentMap.put(IS_END, END_TRUE);
}
}
}
}
/**
* 按照最小规则获取文本中的敏感词(例如敏感词有[出售,出售军刀],则在此规则下,获取到的敏感词为[出售])
*
* @param content 文本内容
* @return 文本中所包含的敏感词set列表
*/
public Set getSensitiveWordMinMatch(String content) {
return getSensitiveWord(content, MIN_MATCH_TYPE);
}
/**
* 按照最大规则获取文本中的敏感词(例如敏感词有[出售,出售军刀],则在此规则下,获取到的敏感词为[出售军刀])
*
* @param content 文本内容
* @return 文本中所包含的敏感词set列表
*/
public Set getSensitiveWordMaxMatch(String content) {
return getSensitiveWord(content, MAX_MATCH_TYPE);
}
/**
* 按照指定规则获取文本中的敏感词
*
* @param content 文本内容
* @return 文本中所包含的敏感词set列表
*/
private Set getSensitiveWord(String content, int matchType) {
Set sensitiveWordList = new HashSet<>();
for (int i = 0; i < content.length(); i++) {
// 检查敏感词,长度为0则表示文本中不包含敏感词
int length = checkSensitiveWord(content, i, matchType);
if (length > 0) {
sensitiveWordList.add(content.substring(i, i + length));
i = i + length - 1;
}
}
return sensitiveWordList;
}
/**
* 从指定索引处检查文本中的敏感词
*
* @param content 文本内容
* @param beginIndex 起始索引
* @return 检索到的敏感词的长度
*/
private int checkSensitiveWord(String content, int beginIndex, int matchType) {
// 敏感词结束标识位:用于敏感词只有一个字符的情况
boolean flag = false;
// 匹配到的敏感词的长度
int matchedLength = 0;
// 当前词的DFA树
Map currentWordMap = sensitiveWordMap;
for (int i = beginIndex; i < content.length(); i++) {
char key = content.charAt(i);
// 解决空格等特殊字符造成的漏匹配,比如 [军, 刀]
if (isIgnore(key)) {
matchedLength++;
continue;
}
// 获取当前字符的DFA树,树为空则表示不存在包含该字符的敏感词
currentWordMap = (Map) currentWordMap.get(key);
if (currentWordMap == null) {
//不存在直接返回
break;
} else {
// 存在则匹配长度+1
matchedLength++;
// 判断是否是匹配中的敏感词的最后一位
if (END_TRUE.equals(currentWordMap.get(IS_END))) {
flag = true;
// 如果是最小匹配规则则直接返回(例如敏感词中有[出售,出售军刀],当匹配到"售"字符时,如果是最小规则则不继续向下匹配)
if (matchType == MIN_MATCH_TYPE) {
break;
}
}
}
}
// 长度小于1则表示不是单词
if (matchedLength < 1 || !flag) {
matchedLength = 0;
}
return matchedLength;
}
/**
* 判断是否是要忽略的字符(忽略所有特殊字符以及空格)
* @param specificChar 指定字符
* @return 特殊字符或空格true否则false
*/
private boolean isIgnore(char specificChar){
Pattern pattern = Pattern.compile(IGNORE_SPECIAL_CHAR_REGEX);
Matcher matcher = pattern.matcher(String.valueOf(specificChar));
return matcher.matches();
}
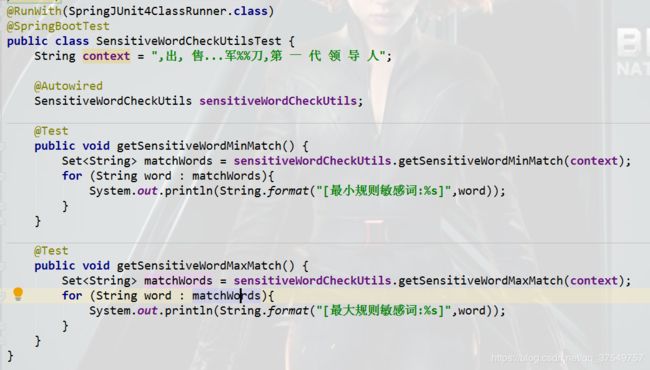
} 测试:
启动:
单元测试:


注明:
本文为学习记录笔记,不喜勿喷。