Scrapy爬取饿了么周围商家信息
大学生吃土指南
一、实验目的及原理
作为一个被花呗和各种电商节支配的当代大学生,每个月难免有三十几天会陷入吃土的困境。但就算吃土也要吃的优雅,吃的舒心。饿了么上有时会有商家活动,可以以很实惠(baipiao)的价格解决一餐。下面我将使用scrapy框架进行第一步——获取周围商家信息。
二、实验准备
在确定了目标后,我们首先要对目标网站进行分析,例如确定它是动态网页还是动态网页,需不需要登陆等。这样有助于我们选择合适的方式去爬取想要的数据,事半功倍。
-
登陆饿了么官网,分析network
登陆饿了么网页版,将商家列表往下拉,能发现页面在不刷新的情况下新增了商家列表,那么确定是动态页面。
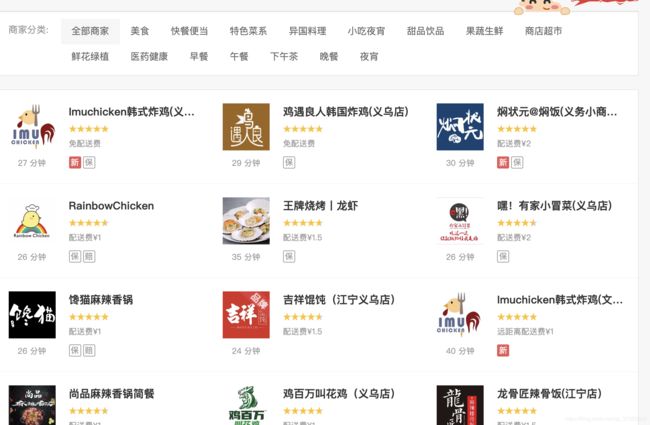
所以接下来打开开发者工具,切到network,点上XHR,刷新页面,下拉页面。

可以看到商家的信息是由一个API提供的。
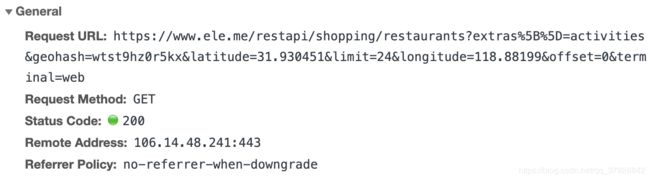
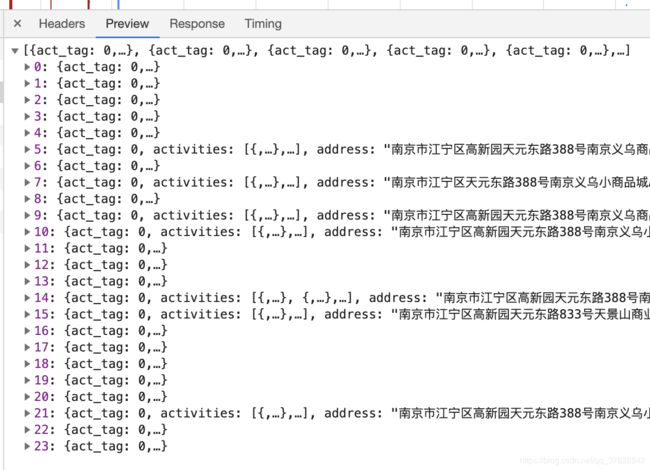
这个API返回了24个商家信息,返回商家数量和API参数limit有关,而且只要改变参数offset就能获取下24个商家信息。但商家信息里没有具体商品的信息,所以我们要找一下有没有去商家页面的入口。

找到商家的url,可以发现每个店都是有自己的id的。接下来故技重施,找一下这个页面有没有接口可以用。

找到API后分析下数据发现商品有优惠和无优惠两种状态
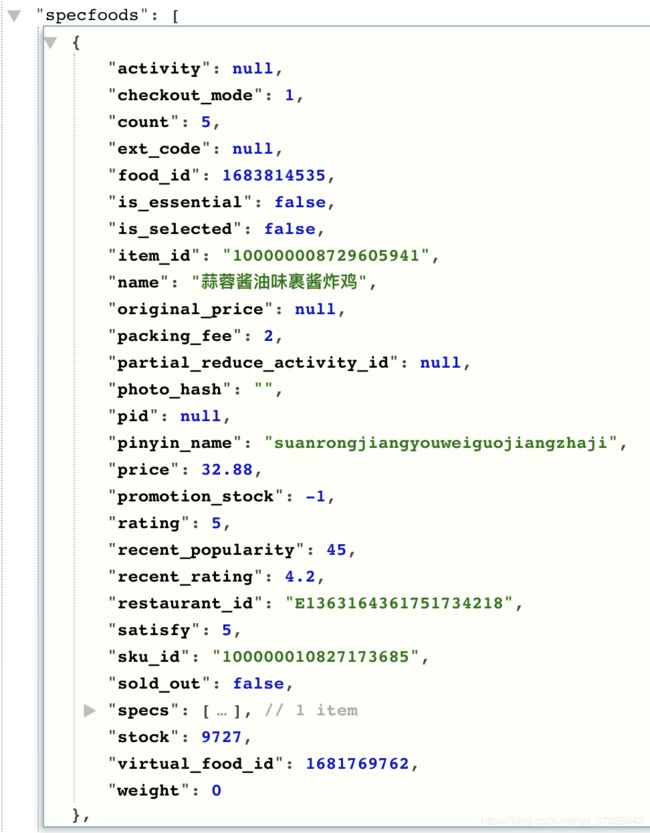
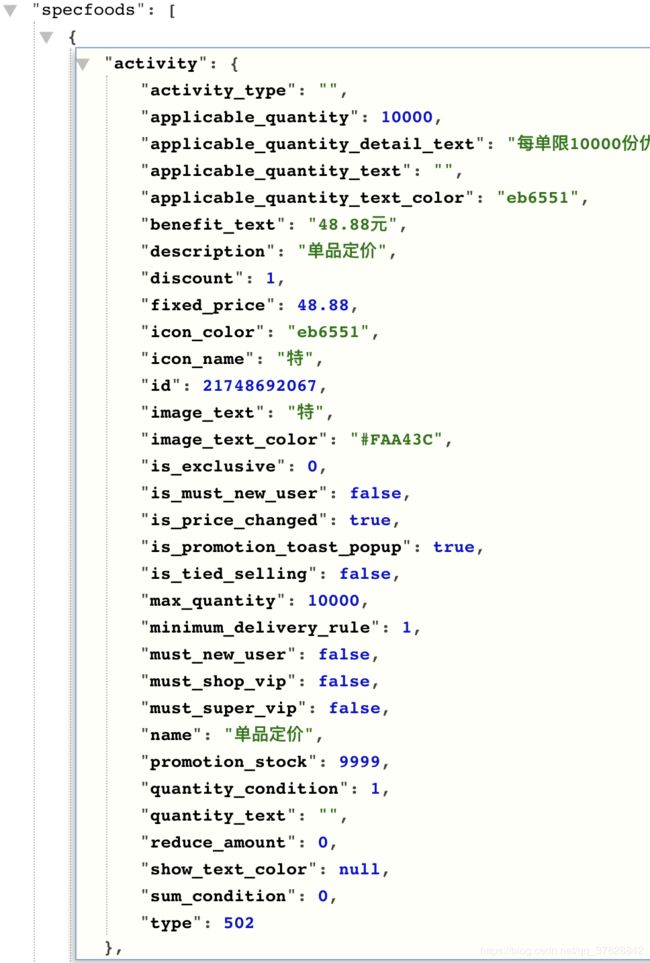
所有信息都已找到,接下来就开始进行下一步——测试API。 -
使用postman测试API
直接调用
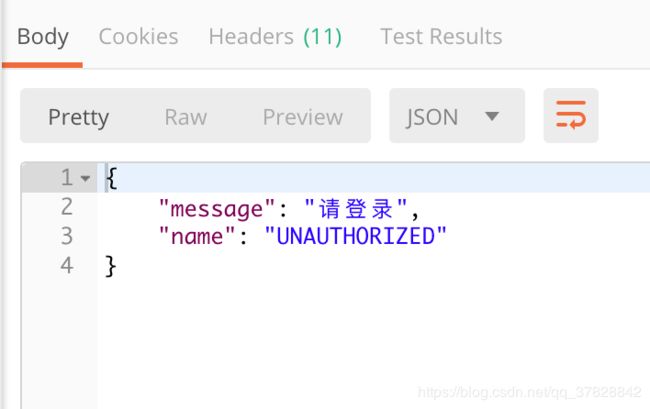
发现需要权限,所以下面带上cookie试试
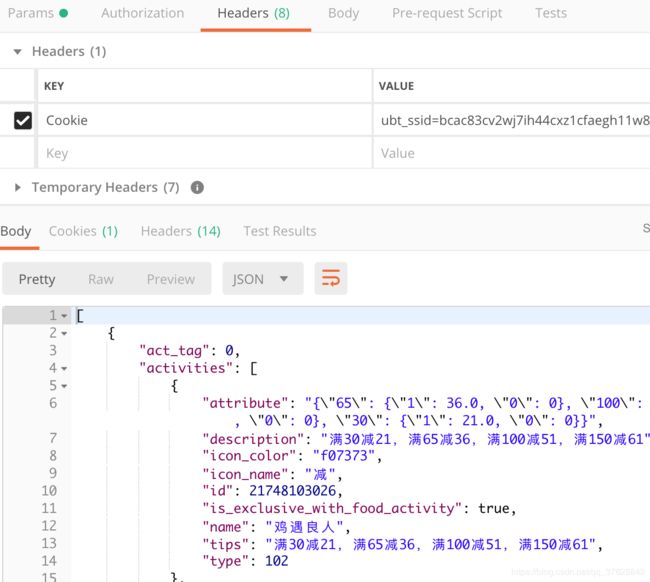
成功,那接下来就可以开始创建scrapy工程了。
三、实验步骤及代码
1.新建scrapy工程
这部分就不多做介绍了,不会的同学可以看下网上的教程。
2.自定义settings
关闭查找robot协议功能
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
设置请求头
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36'
# Override the default request headers:
DEFAULT_REQUEST_HEADERS = {
'Accept': 'application/json, text/plain, */*',
'Accept-Language': 'zh-CN,zh;q=0.9',
}
设置cookie,我使用的方法是获取浏览器中的cookie,需要修改中间件,使用方法是Request请求中加上 meta={‘cookiejar’: ‘chrome’}
# middlewares.py
import browsercookie
from scrapy.downloadermiddlewares.cookies import CookiesMiddleware
class BrowserCookiesMiddleware(CookiesMiddleware):
def __init__(self, debug=False):
super().__init__(debug)
self.load_browser_cookies()
def load_browser_cookies(self):
jar = self.jars['chrome']
chrome_cookiejar = browsercookie.chrome() # 获取chrome浏览器中的cookie
for cookie in chrome_cookiejar:
jar.set_cookie(cookie)
# settings.py
# Disable cookies (enabled by default)
COOKIES_ENABLED = True
DOWNLOADER_MIDDLEWARES = {
'scrapy.downloadmiddlewares.cookies.CookiesMiddleware': None,
'eleme.middlewares.BrowserCookiesMiddleware': 701,
}
3.完善spider
先做个简单的测试,输出每个店的店名和满减
restaurants = json.loads(response.text) # 将response的内容转化为json格式
for item in restaurants:
# 店名
name = item['name']
print(name)
# 满减(因为吃土少年很穷所以只用得起第一个满减)
discount = item['activities'][0]['description']
cheapest = re.match('(满\d+?减\d+?)', discount) # 用正则表达式提取满减信息
print(cheapest.group() if cheapest else '这家店很扣')

完整代码
spider
# spider/food_price.py
# -*- coding: utf-8 -*-
import scrapy
import json
import re
from pprint import pprint
from ..items import ShopItem
class FoodPrice(scrapy.Spider):
name = "food" # spider名字
latitude = 31.930451 # 纬度(根据位置修改)
longtitude = 118.88199 # 经度
offset = 0 # 页数
geohash = "wtst9hz0r5kx" # 未知作用,不知道是不是固定的
allowed_domains = ["ele.me"] # 允许访问域名
start_urls = [
"https://www.ele.me/restapi/shopping/restaurants?"
"extras%5B%5D=activities&geohash={3}&latitude={0}"
"&limit=30&longitude={1}&offset={2}&terminal=web".format(
latitude, longtitude, offset, geohash
)
]
def start_requests(self):
yield scrapy.Request(
url=self.start_urls[0], meta={"cookiejar": "chrome"}, dont_filter=True
)
def parse(self, response):
restaurants = json.loads(response.text) # 将response的内容转化为json格式
# 对每个店铺信息进行分析提取
for item in restaurants:
try:
# 店名
name = item["name"]
# 满减(因为吃土少年很穷所以只用得起第一个满减)
if item["activities"]:
discount = item["activities"][0]["description"]
cheapest = re.match("(满\d+?减\d+?)", discount) # 用正则表达式提取满减信息
reduction = cheapest.group() if cheapest else "这家店很扣"
else:
reduction = "这家店很扣"
# 月售
recent_order_num = item['recent_order_num']
# 配送费
deliver_fee = item["piecewise_agent_fee"]["rules"][0]["fee"]
# 起送费
start_fee = item["piecewise_agent_fee"]["rules"][0]["price"]
# 店铺id
id = item["id"]
shop_url = (
"https://www.ele.me/restapi/shopping/v2/menu?restaurant_id=" + id + "&terminal=web"
)
# 调用店铺商品信息API
yield scrapy.Request(
shop_url,
meta={
"cookiejar": "chrome",
"name": name,
"reduction": reduction,
"deliver_fee": deliver_fee,
"start_fee": start_fee,
"recent_order_num": recent_order_num,
},
callback=self.shop_parse,
)
except IndexError as e:
self.logger.debug(e, item)
if self.offset < 90:
self.offset += 30 # 页数加30
next_url = (
"https://www.ele.me/restapi/shopping/restaurants?"
"extras%5B%5D=activities&geohash={3}&latitude={0}"
"&limit=30&longitude={1}&offset={2}&terminal=web".format(
self.latitude, self.longtitude, self.offset, self.geohash
)
)
# 查看下30个店铺
yield scrapy.Request(
next_url, meta={"cookiejar": "chrome"}, callback=self.parse
)
def shop_parse(self, response):
shop = ShopItem()
items = json.loads(response.text)
meta = response.meta
shop['shop_name'] = meta['name']
shop['recent_order_num'] = meta['recent_order_num']
shop['reduction'] = meta['reduction']
shop['deliver_fee'] = meta['deliver_fee']
shop['start_fee'] = meta['start_fee']
# 优惠商品列表
activity_foods = []
# 普通商品列表
normal_foods = []
# 菜单中每个菜品
for menu in items:
# 菜品中每个菜
for food in menu['foods']:
food_name = food['name']
lowest_price = food['lowest_price']
if lowest_price != 0:
for index in range(len(food['specfoods'])):
if food['specfoods'][index]['price'] == lowest_price:
# 打包费
packing_fee = food['specfoods'][index]['packing_fee']
# 是否是打折商品
if food['activity']:
original_price = food['specfoods'][index]['original_price']
# 折扣 = 折后价/原价(保留两位小数)
discount = round(lowest_price/original_price, 2)
# 价格 = 折后价+打包费
activity_foods.append({
'name': food_name,
'price': lowest_price+packing_fee,
'discount': discount
})
else:
# 价格 = 折后价+打包费
normal_foods.append({
'name': food_name,
'price': lowest_price + packing_fee,
})
shop['activity_foods'] = activity_foods
shop['normal_foods'] = normal_foods
yield shop
items
# items.py
from scrapy import Item, Field
class ShopItem(Item):
shop_name = Field()
recent_order_num = Field()
reduction = Field()
deliver_fee = Field()
start_fee = Field()
activity_foods = Field()
normal_foods = Field()
4. 把内容存在csv文件中
控制台
scrapy crawl food -o'eleme%(time)s.json' -s FEED_EXPORT_ENCODING=UTF-8
"-s FEED_EXPORT_ENCODING=UTF-8"加上这个参数可以存储中文
其中一个店铺的信息,包括运费,起送费,月销量,优惠商品,不优惠商品,满减等信息。
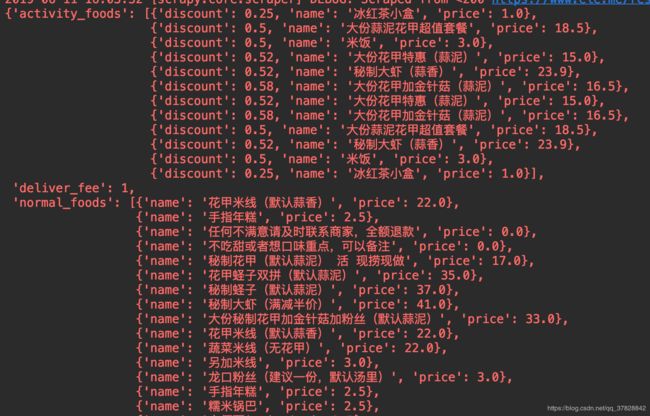
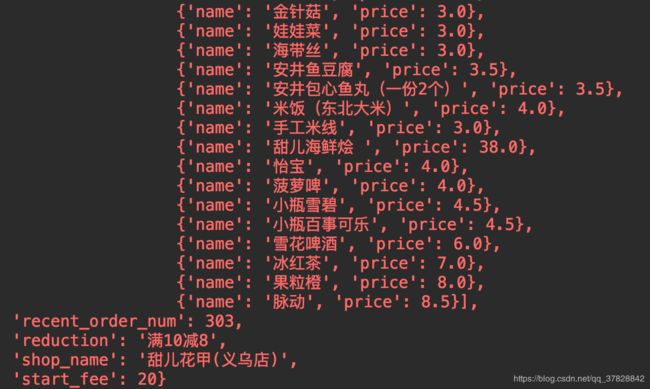
5.最终生成的文件
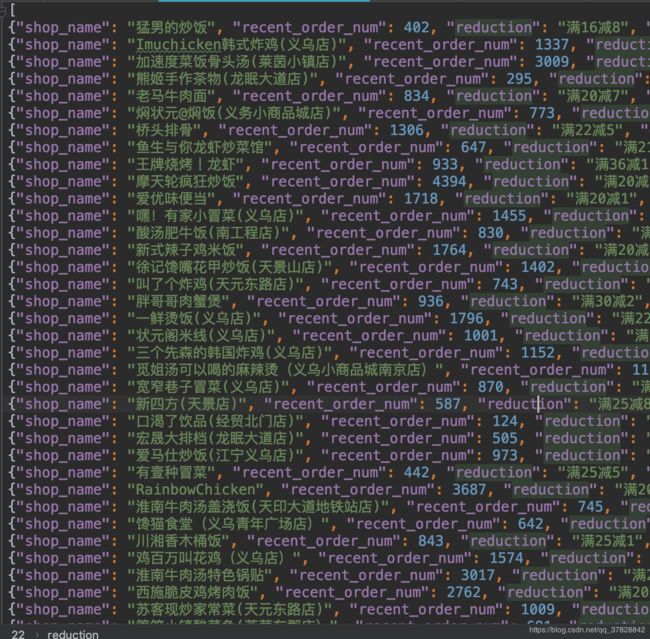
四、实验总结
在获取到这些数据后就可以去设计一个算法来计算出最便宜的点餐方式了,但这不在这次的讨论范围中。同时我也发现有些数据是不必要的,例如:
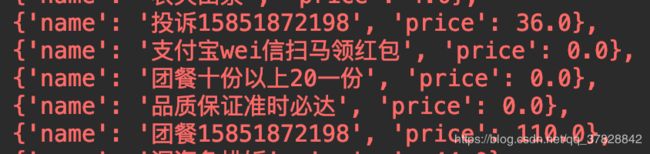
可以通过Item Pipeline去处理这些无效的数据。
最后以一句知乎上发现的句子结尾吧:
有人说技术有罪,有人说技术无罪。我不知道技术是否有罪,我只知道,这些盘踞在我们广袤版图上数以十亿计的爬虫,无时无刻不在提醒着我们:抱怨不会让这个世界变得更好,你想生活在一个怎样的世界,就要用自己的双手去创造它。
项目github:https://github.com/yyyykl/python.git