python爬虫与数据可视化(一)—— 爬取猫眼电影(涉及爬虫反破解)
又是新的一年,让我们一起来看一下刚刚过去的2018留下了哪些经典影片吧!
一、获取电影详情页链接
- 进入猫眼官网,按图中的顺序点击,得到2018年按评分排序的影片进入猫眼官网,按图中的顺序点击,得到2018年按评分排序的影片页面
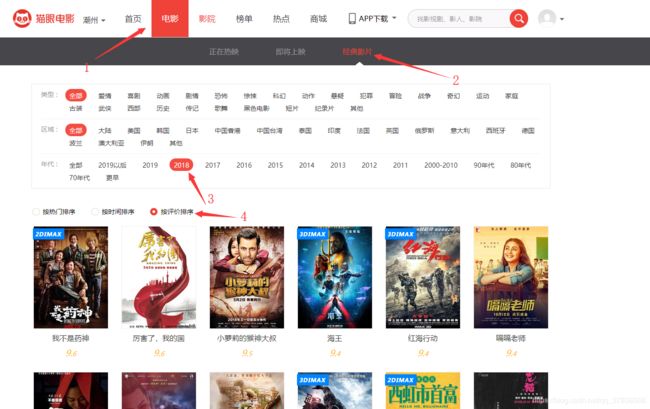
这样我们就得到了第一个爬虫链接:https://maoyan.com/films?showType=3&sortId=3&yearId=13
这样的一页有30部电影,我们需要的肯定不止30部啦!
点击第二页,可以看到链接变化为:https://maoyan.com/films?showType=3&sortId=3&yearId=13&offset=30
多了一个参数,尝试把offset改为0就跳转到第一页,改为60就跳转到第3页,以此类推。 - 在这个页面的数据可满足不了我的需求,点击电影进入该电影的详情页,可以看到电影名称、电影产地、电影时长、电影评分、评分人数、票房等,我把这些都一并保存下来,放入MongoDB。

这个页面的链接是:https://maoyan.com/films/1200486
后面的数字是该电影对应的id,显然我们就需要拿到这个id了,在第一个页面按下F12,定位元素,就可以看到对应的超链接,我们使用BeautifulSoup解析出来即可。
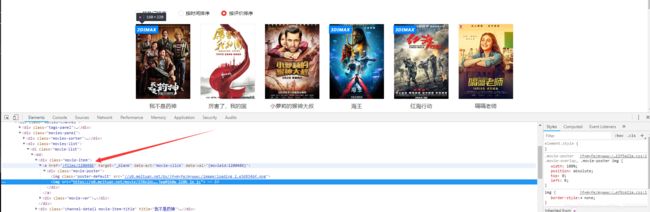
上代码:
# 访问页面
def get_page(url, headers):
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
# 获得每个电源详细页链接
def get_film_url(html):
soup = BeautifulSoup(html, 'html.parser')
film_href = soup.find_all(class_='channel-detail movie-item-title')
film_url = []
for href in film_href:
film_url.append('https://maoyan.com' + href.select('a')[0]['href'])
return film_url
二、解析电影详情页
在开发者工具中可以看到数字并没有像网页上正常显示出来,这是猫眼做了反爬虫处理
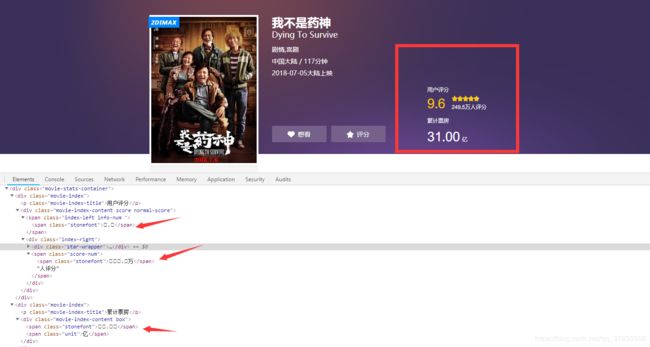
通过ctrl+f,输入font-face,可以看到一个字体文件,通过刷新发现,每次的字体文件都是不一样的
详细的反破解原理我就不多说了,网上其他文章已经解释很多了,思路基本都是保存一份文件,手动识别里面的数字,以后遇到其他文件时再进行比对,这里贴上我参考的几位大佬的链接:
破解代码用的就是这篇文章里面的:https://mp.weixin.qq.com/s/n7GG8sW3aadf8o2laC3KNg
知乎大佬的文章:https://zhuanlan.zhihu.com/p/33112359
讲一下具体步骤吧:
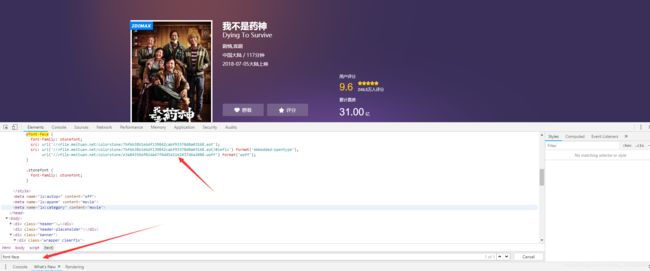
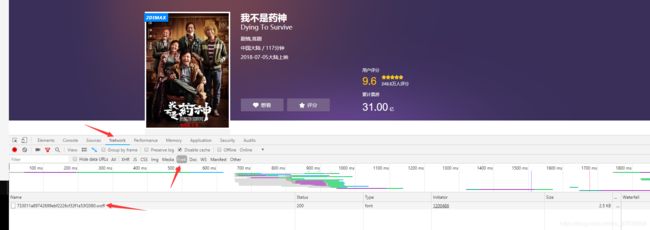
- 在开发者工具选Network,选font,F5刷新一下就出现了一个.woff文件了,双击就可以保存下来,这个文件就对应为你作为基准的字体文件,代码中用的是base.woff,可以顺便把它改成这个名字
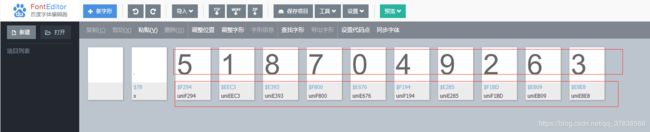
- 打开百度字体编辑器,把刚才woff文件拖进去,就可以看到你看到的编码对应的数字是什么了
- 看破解代码:
def get_numbers(html_response):
"""
对猫眼的文字反爬进行破解
"""
cmp = re.compile(",\n url\('(//.*.woff)'\) format\('woff'\)")
rst = cmp.findall(html_response)
ttf = requests.get("http:" + rst[0], stream=True)
with open("maoyan.woff", "wb") as pdf:
for chunk in ttf.iter_content(chunk_size=1024):
if chunk:
pdf.write(chunk)
base_font = TTFont('base.woff')
maoyan_font = TTFont('maoyan.woff')
maoyan_unicode_list = maoyan_font['cmap'].tables[0].ttFont.getGlyphOrder()
maoyan_num_list = []
base_num_list = ['.', '5', '1', '8', '7', '0', '4', '9', '2', '6', '3']
base_unicode_list = ['x', 'uniF294', 'uniEEC3', 'uniE393', 'uniF800', 'uniE676', 'uniF194', 'uniE285', 'uniF1BD',
'uniEB09', 'uniE8E8']
for i in range(1, 12):
maoyan_glyph = maoyan_font['glyf'][maoyan_unicode_list[i]]
for j in range(11):
base_glyph = base_font['glyf'][base_unicode_list[j]]
if maoyan_glyph == base_glyph:
maoyan_num_list.append(base_num_list[j])
break
maoyan_unicode_list[1] = 'uni0078'
utf8List = [eval(r"'\u" + uni[3:] + "'").encode("utf-8") for uni in maoyan_unicode_list[1:]]
utf8last = []
for i in range(len(utf8List)):
utf8List[i] = str(utf8List[i], encoding='utf-8')
utf8last.append(utf8List[i])
return maoyan_num_list, utf8last
因为每个字体文件数字顺序和编码都不同,实际使用中这段代码需要你把base_num_list ,base_unicode_list 改成你在百度字体编辑器打开你自己保存的base.woff文件的序列
maoyan.woff是爬虫遇到的字体文件,返回值是破解后的数字和编码序列,后面要用于替换
4. 贴代码(注意代码中的utf-8编码,不能漏掉!!):
# 解析电源详细页面,获得影片名称,票房等
def get_data(film_url, headers):
for url in film_url:
data = {}
response = get_page(url, headers)
soup = BeautifulSoup(response, 'html.parser')
data['_id'] = url[len('https://maoyan.com/films/'):]
data["name"] = soup.find_all('h3', class_='name')[0].get_text()
data["type"] = soup.find_all('li', class_='ellipsis')[0].get_text()
data["country"] = soup.find_all('li', class_='ellipsis')[1].get_text().split('/')[0].strip()
data['time'] = soup.find_all('li', class_='ellipsis')[1].get_text().split('/')[1].strip()
# 获取被编码的数字
score_code = soup.find_all('span', class_='stonefont')[0].get_text().strip().encode('utf-8')
data['score'] = str(score_code, encoding='utf-8')
score_num_code = soup.find_all('span', class_='stonefont')[1].get_text().strip().encode('utf-8')
data['score_num'] = str(score_num_code, encoding='utf-8')
booking_office_code = soup.find_all('span', class_='stonefont')[2].get_text().strip().encode('utf-8')
data['booking_office'] = str(booking_office_code, encoding='utf-8')
# 票房单位
unit = soup.find_all('span', class_='unit')[0].get_text().strip()
# 破解
maoyan_num_list, utf8last = get_numbers(response)
# print(maoyan_num_list, utf8last)
# 进行替换得到正确的结果
for i in range(len(utf8last)):
data['score'] = data['score'].replace(utf8last[i], maoyan_num_list[i])
data['score_num'] = data['score_num'].replace(utf8last[i], maoyan_num_list[i])
data['booking_office'] = data['booking_office'].replace(utf8last[i], maoyan_num_list[i])
# 对单位进行换算
if '万' in data['score_num']:
data['score_num'] = int(float(data['score_num'][:len(data['score_num'])-1]) * 10000)
if '万' == unit:
data['booking_office'] = int(float(data['booking_office']) * 10000)
elif '亿' == unit:
data['booking_office'] = int(float(data['booking_office']) * 100000000)
# print(data)
to_mongodb(data)
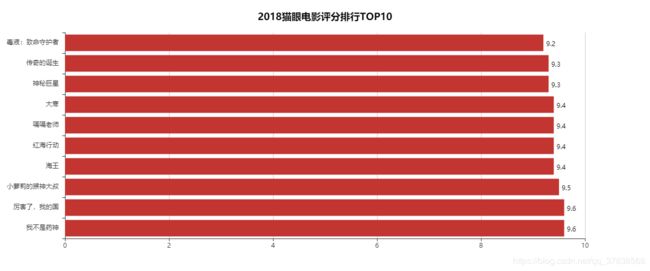
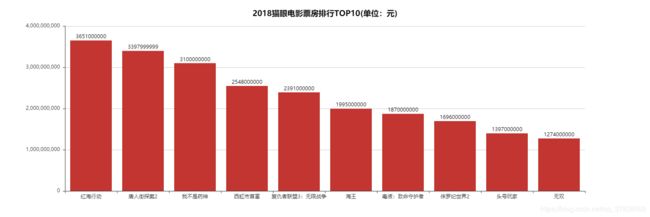
这样就拿到了电影名称,票房,评分之类的信息啦,放入数据库就好了。下面我们随便做一点数据可视化就好了,不能光放数据嘛,拿出来看看
三、数据可视化
用pyecharts随便做了三张图表看看,要直接生成图片好像还得安装node.js,这三张图片是生成html再下载下来的,代码在github