使用Python语言完成SVM实现分类
SVM(support vector machine)支持向量机:
注意:本文不准备提到数学证明的过程,一是因为有一篇非常好的文章解释的非常好:http://blog.csdn.net/v_july_v/article/details/7624837,另一方面是因为我只是个程序员,不是搞数学的(主要是因为数学不好。),主要目的是将SVM以最通俗易懂,简单粗暴的方式解释清楚。
线性分类:
先从线性可分的数据讲起,如果需要分类的数据都是线性可分的,那么只需要一根直线f(x)=wx+b就可以分开了,类似这样:

这种方法被称为:线性分类器,一个线性分类器的学习目标便是要在
n
维的数据空间中找到一个超平面(hyper plane)。也就是说,数据不总是二维的,比如,三维的超平面是面。
但是有个问题:
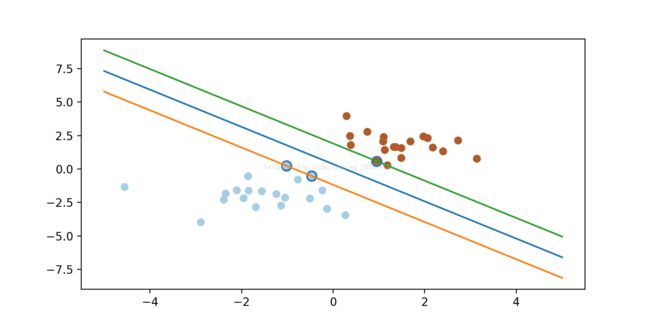
上述两种超平面,都可以将数据进行分类,由此可推出,其实能有无数个超平面能将数据划分,但是哪条最优呢?
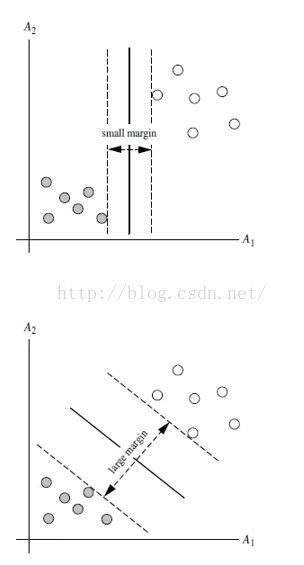
最大间隔分类器Maximum Margin Classifier:
简称MMH, 对一个数据点进行分类,当超平面离数据点的“间隔”越大,分类的确信度(confidence)也越大。所以,为了使得分类的确信度尽量高,需要让所选择的超平面能够最大化这个“间隔”值。这个间隔就是下图中的Gap的一半。

用以生成支持向量的点,如上图XO,被称为支持向量点,因此SVM有一个优点,就是即使有大量的数据,但是支持向量点是固定的,因此即使再次训练大量数据,这个超平面也可能不会变化。
非线性分类:
数据大多数情况都不可能是线性的,那如何分割非线性数据呢?

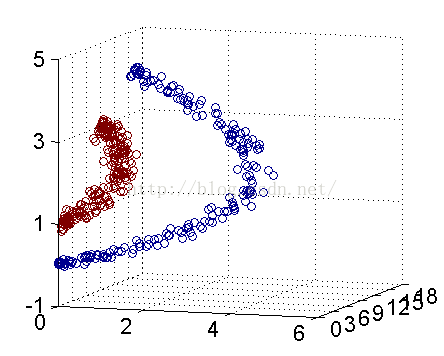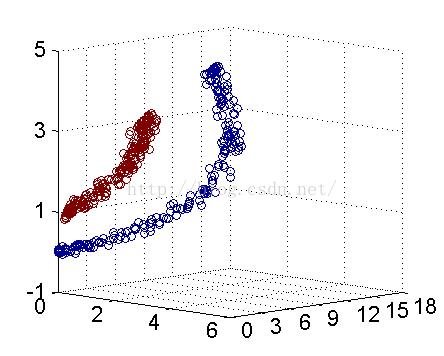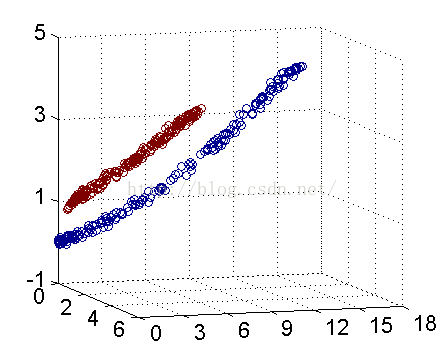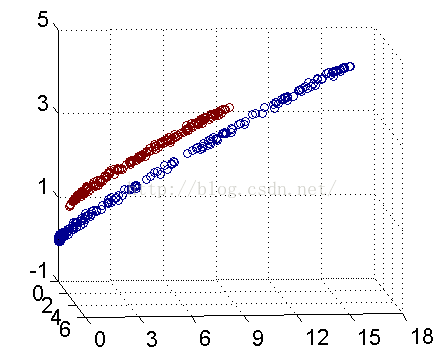
解决方法是将数据放到高维度上再进行分割,如下图:
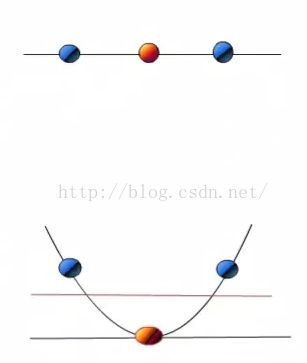
当f(x)=x时,这组数据是个直线,如上半部分,但是当我把这组数据变为f(x)=x^2时,这组数据就变成了下半部分的样子,也就可以被红线所分割。
比如说,我这里有一组三维的数据X=(x1,x2,x3),线性不可分割,因此我需要将他转换到六维空间去。
因此我们可以假设六个维度分别是:x1,x2,x3,x1^2,x1*x2,x1*x3,当然还能继续展开,但是六维的话这样就足够了。
新的决策超平面:d(Z)=WZ+b,解出W和b后带入方程,因此这组数据的超平面应该是:
d(Z)=w1x1+w2x2+w3x3+w4*x1^2+w5x1x2+w6x1x3+b
但是又有个新问题,转换高纬度一般是以内积(dot product)的方式进行的,但是内积的算法复杂度非常大。
核函数Kernel:
我们会经常遇到线性不可分的样例,此时,我们的常用做法是把样例特征映射到高维空间中去。但进一步,如果凡是遇到线性不可分的样例,一律映射到高维空间,那么这个维度大小是会高到可怕的,而且内积方式复杂度太大。此时,核函数就隆重登场了,核函数的价值在于它虽然也是讲特征进行从低维到高维的转换,但核函数绝就绝在它事先在低维上进行计算,而将实质上的分类效果表现在了高维上,也就如上文所说的避免了直接在高维空间中的复杂计算。
几种常用核函数:
h度多项式核函数(Polynomial Kernel of Degree h)
高斯径向基和函数(Gaussian radial basis function Kernel)
S型核函数(Sigmoid function Kernel)
图像分类,通常使用高斯径向基和函数,因为分类较为平滑,文字不适用高斯径向基和函数。
没有标准的答案,可以尝试各种核函数,根据精确度判定。
松弛变量:
数据本身可能有噪点,会使得原本线性可分的数据需要映射到高维度去。对于这种偏离正常位置很远的数据点,我们称之为 outlier ,在我们原来的 SVM 模型里,outlier 的存在有可能造成很大的影响,因为超平面本身就是只有少数几个 support vector 组成的,如果这些 support vector 里又存在 outlier 的话,其影响就很大了。

解决多分类问题:
经典的SVM只给出了二类分类的算法,现实中数据可能需要解决多类的分类问题。因此可以多次运行SVM,产生多个超平面,如需要分类1-10种产品,首先找到1和2-10的超平面,再寻找2和1,3-10的超平面,以此类推,最后需要测试数据时,按照相应的距离或者分布判定。
SVM与其他机器学习算法对比(图):

Python实现方式:
线性,基础:
- from sklearn import svm
- x = [[2,0,1],[1,1,2],[2,3,3]]
- y = [0,0,1] #分类标记
- clf = svm.SVC(kernel = 'linear') #SVM模块,svc,线性核函数
- clf.fit(x,y)
- print(clf)
- print(clf.support_vectors_) #支持向量点
- print(clf.support_) #支持向量点的索引
- print(clf.n_support_) #每个class有几个支持向量点
- print(clf.predict([2,0,3])) #预测
- from sklearn import svm
- import numpy as np
- import matplotlib.pyplot as plt
- np.random.seed(0)
- x = np.r_[np.random.randn(20,2)-[2,2],np.random.randn(20,2)+[2,2]] #正态分布来产生数字,20行2列*2
- y = [0]*20+[1]*20 #20个class0,20个class1
- clf = svm.SVC(kernel='linear')
- clf.fit(x,y)
- w = clf.coef_[0] #获取w
- a = -w[0]/w[1] #斜率
- #画图划线
- xx = np.linspace(-5,5) #(-5,5)之间x的值
- yy = a*xx-(clf.intercept_[0])/w[1] #xx带入y,截距
- #画出与点相切的线
- b = clf.support_vectors_[0]
- yy_down = a*xx+(b[1]-a*b[0])
- b = clf.support_vectors_[-1]
- yy_up = a*xx+(b[1]-a*b[0])
- print("W:",w)
- print("a:",a)
- print("support_vectors_:",clf.support_vectors_)
- print("clf.coef_:",clf.coef_)
- plt.figure(figsize=(8,4))
- plt.plot(xx,yy)
- plt.plot(xx,yy_down)
- plt.plot(xx,yy_up)
- plt.scatter(clf.support_vectors_[:,0],clf.support_vectors_[:,1],s=80)
- plt.scatter(x[:,0],x[:,1],c=y,cmap=plt.cm.Paired) #[:,0]列切片,第0列
- plt.axis('tight')
- plt.show()