12-样例类和模式匹配
前言
该节简单介绍样例类(case class)和模式匹配(pattern matching),以及各种模式、密封类(sealed class)、Option类型。
所有代码:
GitHub:https://github.com/GYT0313/Scala-Learning
1. 一个简单的例子
这里先用一个简单的例子来切入对样例类和模式匹配的学习。
文件 15.1.scala
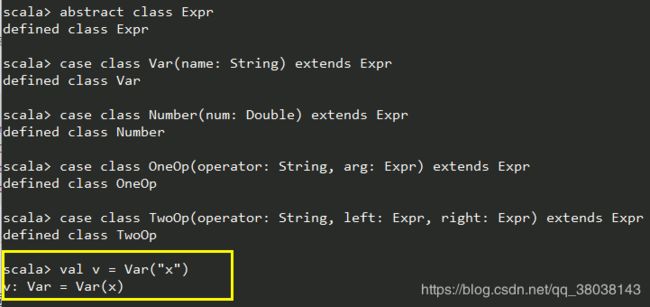
abstract class Expr
case class Var(name: String) extends Expr
case class Number(num: Double) extends Expr
case class OneOp(operator: String, arg: Expr) extends Expr
case class TwoOp(operator: String, left: Expr, right: Expr) extends Expr
例子中包括一个抽象基类Expr 和 四个子类。Scala 运行空的定义体可以省去{ }。
- 样例类
15.1中样例类的关键词就是 case class。用上这个修饰符Scala编译器会给类添加一些语法上的便利。
有四点:
- 添加一个和类同名的工厂方法。意味着可以使用类名直接构造一个对象,即可以省略new 关键词。如:
当你嵌套定义时,不用看到过多的new 关键词:

- 参数列表中的每个参数都隐式地获得了一个val 前缀,即他们会被当做字段处理,好处就是可以这样调用参数:

- 编译器会以“自然”的方式实现toString、hashCode和equals方法

- 编译器会添加一个copy方法,用于制作修改过的拷贝
不做修改即复制原对象的所有字段,如果需要修改:参数名=值。

带来的是大量的便利,代价却很小。需要多写一个case修饰符,并且类和对象占用内存会变大一点。原因是:生成了额外的方法,并且对于构造方法的每个参数都隐式地添加了字段。
不过最大的好处是它支持模式匹配。
- 模式匹配
15.1.scala
def simplifyTop(expr: Expr): Expr = expr match {
case OneOp("-", OneOp("-", e)) => e // 双重取负
case TwoOp("+", e, Number(0)) => e // 加 0
case TwoOp("*", e, Number(1)) => e // 乘 1
case _ => expr
}
函数simplifyTop 的右边由一个match表达式组成。规则是:
选择器 match { 可选分支 }
可选分支由case 关键字开头,每个可选分支由 一个模式 => 多个表达式组成。
如,"+",1称为常量模式,e 称为变量模式(后面会详细介绍)。
构造方法模式如:One("-", e),入参本身也是模式,如下面例子有三层模式:
OneOp("-", OneOp("-", e)),OneOp两层,入参一层(后面还会有提到)。
运行示例:
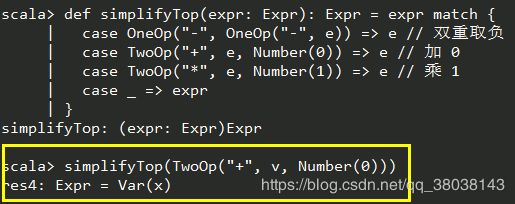
注意:上面的参数v,是这样来的:Val v = Var(“x”),这里忘记写出来了。
Scala中的模式匹配和其他语言中的switch 很相似,但也有三点重要区别:
- Scala的match是一个表达式,也就是说最后总能得到一个值
- Scala的可选分支不会贯穿到下一个case
- 如果没有一个模式匹配上,会抛出名为MatchError的异常(意味着通常,最后需要加上一个通配模式,即上例的 case _ )
2. 模式的种类
- 通配模式
通配模式(_) 可以匹配任何对象,用于缺省、捕获所有的可选路径,比如:
15.2.scala
v match {
case Var("y") => println("get y")
case _ => // 不做任何处理
}
v match {
case Var("x") => println("get x")
case _ => // 不做任何处理
}
运行示例:

通配模式还可以用来忽略某个对象你并不关心的局部。例如,下面这个例子只关心这个表达式是否是二元操作,如:
15.2.scala
val expr = TwoOp("-", v, Number(0))
expr match {
case TwoOp(_,_,_) => println(TwoOp + "is binary operation")
case _ => println("something else")
}

2. 常量模式
常量模式仅匹配自己,任何字面量(数值、字符串…)都可以作为常量模式使用。例如:
15.2.scala
// constant pattern
def describe(x: Any) = x match {
case 5 => "five"
case true => "truth"
case "hello" => "hi"
case Nil => "empty list"
case _ => "something else"
}

3. 变量模式
变量模式匹配任何对象,和通配模式相同。不同之处在于,Scala将对应的变量绑定成匹配上的对象。在绑定之后,可以用这个变量做进一步的处理,比如:
15.2.scala
v match {
case Var("0") => "zero"
case somethingElse => "not zero: " + somethingElse
}

如何区分变量还是常量?
常量模式也可以有符号形式的名称。当把Nil 当作一个模式的时候,实际上就是用一个符号来引用常量。一个关于常量E(2.71828)和Pi(3.14159)的例子:
15.2.scala
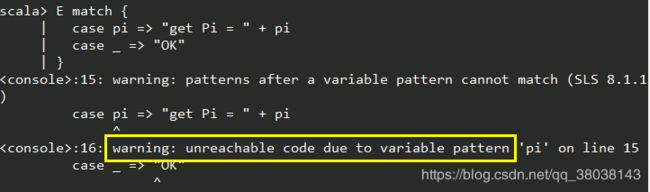
import math.{E, Pi}
E match {
case Pi => "get Pi = " + Pi
case _ => "OK"
}

编译器如何识别Pi 是常量呢?
Scala采用一个简单的词法规则来区分:一个以小写字母打头的简单名称会被当做模式变量处理,所有其他引用都是常量。
比如,这里给Pi 取一个别名:

由于这里 case pi 已经相当于通配了,如果在添加一个 case _,不可能执行的语句,会报错,如:
如果需要,仍然可以使用小写的名称作为模式常量。有两个技巧:1. 如果常量是某个对象的字段,可以在字段前加上限定词,如this.pi 或 obj.pi 。尽管是小写,仍会被当作常量。2. 使用反引号将名称括起来,如:

就像用反引号括起来的关键字也可以使用:

4. 构造方法模式
构造方法模式是真正体现出模式匹配威力的地方。一个构造方法模式看上去就像这样:“TwoOp("+", e, Number(0))”。它由一个名称(TwoOp)和一组圆括号中的模式:"+"、e和Number(0)组成。
假定这里的名称指定的是一个样例类,这样的一个模式将首先检查被匹配的对象是否是以这个名称命名的样例类的实例,然后再检查这个对象的构造方法参数是否匹配这些额外给出的模式。
这些额外的模式意味着Scala的模式支持深度匹配。这样的模式不仅检查给出的对象的顶层,还会进一步检查对象内部时可以到任意的深度。
如下例中:“TwoOp("+", e, Number(0))”,模式将检查顶层对象是TwoOp,第三个构造方法参数是Number,且这个Number的字段值为0.这是一个长度只有一行但深度有三层的模式。
expr match {
case TwoOp("+", e, Number(0)) => println("a deep")
case _ =>
}
- 序列模式
序列模式与样例类匹配一样,也可以跟序列类型做匹配。如List、Array。同时可以给出任意数量的元素,如:
15.2.scala
固定数量:
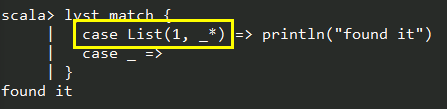
val lyst = List(1,2,3)
lyst match {
case List(1, _, _) => println("found it")
case _ =>
}

任意数量:
6. 元组模式
15.2.scala
def tuplePattern(expr: Any) = expr match {
case (a, b, c) => println("matched: " + a + b + c)
case _ =>
}
tuplePattern(("a", 3, Nil))

7. 带类型的模式
15.2.scala
def generalSize(x: Any) = x match {
case s: String => s.length
case m: Map[_, _] => m.size
case l: List[_] => l.length
case _ => -1
}
generalSize("hello")
generalSize(Map(1->"a", 2->"b"))
generalSize(List(1,2,3))
generalSize(5)

类型擦除
获取,你可能会写一个关于键值都是Int 的模式匹配,如:

可以发现,无论键值是Int 或 String,匹配结果都是true。因为,Scala采用了擦除式的泛型,跟Java一样。意味着在运行时并不会保留类型参数的信息。所以运行时无法判断某个给定的Map对象是不是用两个Int 类型参数创建的。系统只能判断某个值是不是Map。
这个擦除规则唯一的例外是数组。因为,Java和Scala都对它们进行了特殊处理。数组的元素类型是跟数组一起保存的,因此可以对它进行模式匹配,如:

变量绑定
除了独立存在的变量模式外(case something=> println(something)),还可以对任何其他模式添加变量。只需要写下变量名、一个@符号和模式本身,就可以得到一个变量绑定模式。
这个模式将跟平常一样执行模式匹配,如果匹配成功,就将匹配的对象赋值给这个变量,就像简单的变量模式一样。
示例,如连续应用两次绝对值的结果与一次绝对值的结果相同,所以下面这个模式可以简化成只执行一次绝对值操作:
15.2.scala
OneOp("abs", OneOp("abs", v)) match {
case OneOp("abs", e @ OneOp("abs", _)) => e
case _ =>
}

这个模式,会判断是否满足顶层为 OneOp,然后是第一个参数是否是"abs“,再然后是第二个参数是否是OneOp(“abs”, _),如果满足则将e @ xxx,的xxx赋值给e。
3. 模式守卫
有时候语法级的模式匹配不够精确。举例来说,假定要公式化一个简化规则,即用 (e * 2) 来替换 (e + e)。如,表达式TwoOp("+", Var(“x”), Var(“x”)),简化后应该为:TwoOp("*", Var(“x”), Number(2))。
所以,你的定义规则可能使这样:

这样会失败,因为Scala要求模式都是线性的:同一模式变量在模式中只能出现一次。(线性这一词还在特征中出现过:混入特质和传统的多继承有什么区别?答案是线性化。当你用new 实例化一个类的时候,Scala会将类及它所继承的类和特质都拿出来,将它们线性地排列在一起。)
不过,我们可以用一个模式守卫来重新定义这个匹配逻辑,如:
15.3.scala
def simplifyAdd(e: Expr) = e match {
case TwoOp("+", x, y) if x == y => TwoOp("*", x, Number(2))
case _ => e
}
simplifyAdd(TwoOp("+", v, v))

模式守卫出现在模式之后,以if 打头。模式守卫可以是任意的布尔表达式,通常会用到模式中的变量。
再比如其他的模式守卫:
// 仅匹配正整数
case n: Int if n > 0 => xxx
// 近匹配scala开头的字符串
case s: String if s.startWith("scala") => xxx
4. 模式重叠
模式会按照代码中的顺序逐个被尝试。下面示例展示了模式中case 出现顺序的重要性:
15.4.scala
def simplifyAll(e: Expr): Expr = e match {
case OneOp("-", OneOp("-", e)) => simplifyAll(e) // -是对自己的取反
case TwoOp("+", e, Number(0)) => simplifyAll(e) // 0是+的中性元素
case TwoOp("*", e, Number(1)) => simplifyAll(e) // 1是*的中性元素
case OneOp(op, e) => OneOp(op, simplifyAll(e))
case TwoOp(op, l, r) => TwoOp(op, simplifyAll(l), simplifyAll(r))
case _ => e
}
simplifyAll(OneOp("-", OneOp("-", OneOp("-", OneOp("-", v)))))

函数simplifyAll 会对每个表达式的各处都执行简化。
可以看到表达式几乎都调用了函数本身,这里也称为递归。
5. 密封类
每当我们编写一个模式匹配时,都需要确保完整的覆盖了所有可能的case。有时候可以通过在末尾添加通配模式来做到,但这是一个比较局限的情况。
我们可以寻求Scala编译器的帮助,帮我们检测出match 表达式中缺失的模式组合。但这在当前第1 点钟的Expr 示例是不可能出现的,因为你随时可能在第二个文件中添加第5个样例类。
解决这个问题需要将这些样例类标记为密封的。密封类除了在同一个文件中定义的子类之外,不能添加新的子类。所以,我们只需要关心已知的样例类,如果对此作模式匹配,编译器会自动用警告消息标示出缺失的模式组合。
密封类只需要在类名前面添加一个sealed 关键字,如将第1点中的示例修改为样例类:
15.5.scala
sealed abstract class Expr
case class Var(name: String) extends Expr
case class Number(num: Double) extends Expr
case class OneOp(operator: String, arg: Expr) extends Expr
case class TwoOp(operator: String, left: Expr, right: Expr) extends Expr
写一个模式匹配:
def describe(e: Expr): String = e match {
case Number(_) => "a number"
case Var(_) => "a variable"
}
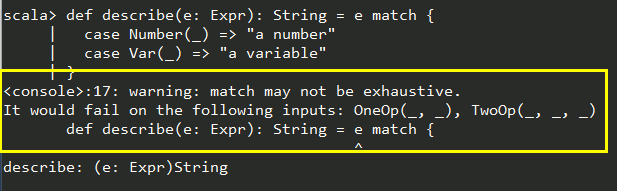
不过,如果你只想写一个关于Number 和Var 的模式匹配,可能就需要添加一个捕获所有的case,如:
15.5.scala

这样可行,但不理想。因为添加了永远不会被执行的代码。
一个更好的做法是添加注解:@unchecked
如:

加上该注解,编译器对后续模式分子的覆盖完整性检查就会被压制。
6. Option 类型
Scala由一个名为Option 的标准类型来表示可选值。这样的值可以有两种形式:1. Some(x),x就是实际的值。2. None对象,代表没有值。
Scala集合类的某些标准操作会返回可选值。比如,Map有一个get 方法,当传入的键有对应的值时,返回Some(value);当传入的键没有定义时,返回None,如:
15.6.scala

用一个模式匹配来解值:
15.6.scala

7. 到处都是模式
Scala中很多地方都允许使用模式。
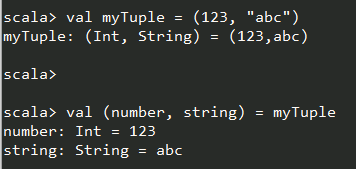
变量定义中的模式
15.7.scala
解元组
作为偏函数的case 序列
15.7.scala
书上这个例子讲解后,讲了Akka 的actor类库,博主这里也看不懂,就跳过这里。
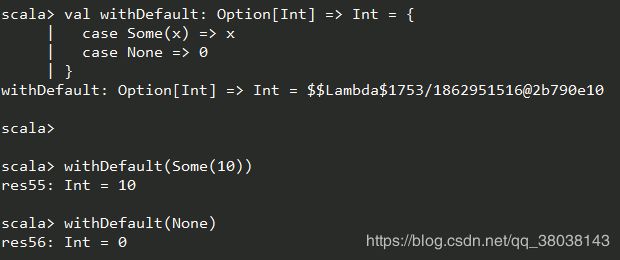
像 withDefault: Option[Int] => Int = 这样的模式匹配,通过case 序列得到的是一个偏函数。将函数应用到一个不支持的值会产生运行时异常,如,下例是返回整数列表的第二个元素的偏函数:
15.7.scala

可以看出,编译时会抛出一个匹配不全面的警告。
传入一个空列表Nil,就会抛出异常。
如果要将模式匹配修改为仅涵盖整数列表到整数的函数,需要将上例改为偏函数的定义为PartialFunction[List[Int], Int],修改后:
15.7.scala
val second: PartialFunction[List[Int], Int] = {
case x::y::_ => y
}

你会发现,不再抱错。因为,偏函数定义了一个isDefinedAt方法。可以用来检查该函数是否对某个特定的值有意义。如:

事实上,这样的表达式会被Scala编译器翻译成偏函数,这样的翻译发生了两次:一次是实现真正的函数,另一次是测试这个函数是否对指定的值有定义。(后面还有一点内容博主没能理解,这里就先到这里)。
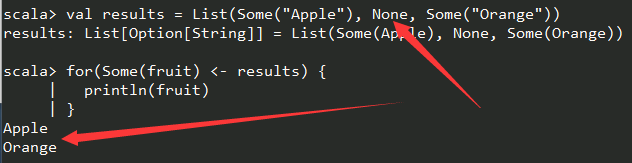
for 表达式中的模式
例如:
15.7.scala

如果有None值,无法匹配Some(fruit),将被丢弃:
8. 一个复杂的例子
学习样例类和模式匹配后,这里用一个较复杂的例子进一步掌握。
例子的效果是把:“x / (x + 1)”纵向打印,如:

要定义的类叫做ExprFormatter,需要做大量的布局安排。布局类使用以前章节写过的布局类库,这里直接使用代码,有兴趣可以看看具体是如何实现的(链接)。
第一步,横向布局:
15.8.scala
TwoOp("+",
TwoOp("*",
TwoOp("+", Var("x"), Var("y")),
Var("z")),
Number(1))
上述代码应该打印出:(x + y) * z + 1,里层(x + y) 的括号是必须的,((x + y) * z) 的括号不是必须的。为了保证清晰可读,应该尽量去掉冗余的括号,同时确保所有必要的括号保留。
为了知道哪里应该放置圆括号,需要知晓操作符的优先级,可以用映射字面量来直接表示优先级:
// 简单的描述
Map(
"|" -> 0, "||" -> 0,
"&" -> 1, "&&" -> 1,
...
)
下面定义precedence是操作符到优先级的映射,优先级从0开始。
precedence使用了嵌套表达式,这样一来,数组中操作符的相对位置就被当作它的优先级。
已经搞定了所有除 / 之外的二元操作符的优先级,下面让它包含一元操作符。一元操作符的优先级高于所有的二元操作符。因此可以将unaryPrecedence的优先级设置为=opGroups.length,也就是比* 和 %多1。分数采用纵向布局,将除法的优先级fractionPrecedence= -1 会很方便。
// 算术表达式定义
sealed abstract class Expr
case class Var(name: String) extends Expr
case class Number(num: Double) extends Expr
case class OneOp(operator: String, arg: Expr) extends Expr
case class TwoOp(operator: String, left: Expr, right: Expr) extends Expr
class ExprFormatter {
// 优先级递增的操作符分组
private val opGroups =
Array(
Set("|", "||"),
Set("&", "&&"),
Set("^"),
Set("==", "!="),
Set("<", "<=", ">", ">="),
Set("+", "-"),
Set("*", "%")
)
// 操作符到对应优先级的映射关系
private val precedence = {
val assocs =
for {
i <- 0 until opGroups.length
op <- opGroups(i) // 嵌套生成器(双重for)
} yield op -> i
assocs.toMap
}
// 一元操作符优先级=opGroups.length
// 分数优先级=-1
private val unaryPrecedence = opGroups.length
private val fractionPrecedence = -1
// ......
}
然后是ExprFormatter的剩下部分:
第一个方法:stripDot是一个助手方法;第二个私有的format方法完成了格式化表达式的主要工作;最后一个同名的format方法是类库中唯一的公开方法,接收一个要格式化的表达式作为入参。私有的format方法通过对表达式的种类执行模式匹配来完成工作。
这里有5个模式匹配,依次为:
第一个case:

如果表达式是一个变量,结果就是该变量构成的元素。
第二个case:

如果表达式是一个数值,结果就是该数值构成的元素。stripDot函数去掉浮点数的".0"。
第三个case:

如果表达式是一个一元操作One(op, arg),结果就是由操作op 和当前环境中最高优先级格式化(当前是unaryPrecedence)入参arg后的结果构成。意味着如果arg是二元操作符(不是分数),它将总显示在圆括号中。
第四个case:

上面case 是为了处理 / 的二元操作,分数由三部分组成:上、线和下。
最后的if 判断解决了分数可能的歧义,如:
第一个可能被解读为(a/b)/c 或 a/(b/c),第二个则是(a/b)/c

第5个case:

首先将left 和 right格式化。格式化left的优先级是op的opPrec,而格式化right的优先级是opPrec+1,确保了圆括号能够正确反映结性。比如,如果TwoOp("-", Var(“a”), TwoOp("-", Var(“b”), Var(“c”))),采用right优先级不加1,会出现 a-b-c。如果+1,会出现a-(b-c)。
得到目前的代码:
15.8.scala
// 算术表达式定义
sealed abstract class Expr
case class Var(name: String) extends Expr
case class Number(num: Double) extends Expr
case class OneOp(operator: String, arg: Expr) extends Expr
case class TwoOp(operator: String, left: Expr, right: Expr) extends Expr
class ExprFormatter {
// 优先级递增的操作符分组
private val opGroups =
Array(
Set("|", "||"),
Set("&", "&&"),
Set("^"),
Set("==", "!="),
Set("<", "<=", ">", ">="),
Set("+", "-"),
Set("*", "%")
)
// 操作符到对应优先级的映射关系
private val precedence = {
val assocs =
for {
i <- 0 until opGroups.length
op <- opGroups(i) // 嵌套生成器(双重for)
} yield op -> i
assocs.toMap
}
// 一元操作符优先级=opGroups.length
// 分数优先级=-1
private val unaryPrecedence = opGroups.length
private val fractionPrecedence = -1
private def format(e: Expr, enclPrec: Int): Element =
e match {
case Var(name) =>
elem(name)
case Number(num) =>
def stripDot(s: String) =
if (s.endsWith(".0")) s.substring(0, s.length-2)
else s
elem(stripDot(num.toString))
case OneOp(op, arg) =>
elem(op) beside format(arg, unaryPrecedence)
case TwoOp("/", left, right) =>
val top = format(left, fractionPrecedence)
val bot = format(right, fractionPrecedence)
val line = elem('-', top.width max bot.width, 1)
val frac = top above line above bot // 结果由上、线、下构成
if (enclPrec != fractionPrecedence) frac // 不是分数直接返回
else elem(" ") beside frac beside elem(" ") // 是分数, 结果两边各加一个空格
case TwoOp(op, left, right) =>
val opPrec = precedence(op)
val l = format(left, opPrec)
val r = format(right, opPrec+1) // 优先级+1
val oper = l beside elem(" " + op + " ") beside r
if (enclPrec <= opPrec) oper
else elem("(") beside oper beside elem(")")
}
// 公共的format
def format(e: Expr): Element = format(e, 0)
}
最终代码:
ComplcatedExample.scala
// 布局类库
object Element {
private class ArrayElement(
val contents: Array[String]
) extends Element
private class UniformElement(
ch: Char,
override val width: Int,
override val height: Int
) extends Element {
private val line = ch.toString * width
def contents = Array.fill(height)(line)
}
private class LineElement(s: String) extends Element {
val contents = Array(s)
override def width = s.length
override def height = 1
}
def elem(contents: Array[String]): Element =
new ArrayElement(contents)
def elem(chr: Char, width: Int, height: Int): Element =
new UniformElement(chr, width, height)
def elem(line: String): Element =
new LineElement(line)
}
import Element.elem
abstract class Element {
def contents: Array[String]
def width: Int =
if (height == 0) 0 else contents(0).length
def height: Int = contents.length
def above(that: Element): Element = {
// above 只需要控制左右居中
val this1 = this widen that.width
val that1 = that widen this.width
elem(this1.contents ++ that1.contents)
}
def beside(that: Element): Element = {
// beside 只需要控制上下居中
val this1 = this heighten that.height
val that1 = that heighten this.height
elem(
for (
(line1, line2) <- this1.contents zip that1.contents
) yield line1 + line2
)
}
def widen(w: Int): Element =
// 如果w <= width, 直接返回
if (w <= width) this
else {
// left 和 right 保证短的元素左右居中
val left = elem(' ', (w - width) / 2, height)
val right = elem(' ', w - width - left.width, height)
left beside this beside right
}
def heighten(h: Int): Element =
if (h < height) this
else {
// top 和 bot 保证短的元素上下居中
val top = elem(' ', width, (h - height) / 2)
val bot = elem(' ', width, h - height - top.height)
top above this above bot
}
override def toString = contents mkString "\n"
}
// 算术表达式定义
sealed abstract class Expr
case class Var(name: String) extends Expr
case class Number(num: Double) extends Expr
case class OneOp(operator: String, arg: Expr) extends Expr
case class TwoOp(operator: String, left: Expr, right: Expr) extends Expr
class ExprFormatter {
// 优先级递增的操作符分组
private val opGroups =
Array(
Set("|", "||"),
Set("&", "&&"),
Set("^"),
Set("==", "!="),
Set("<", "<=", ">", ">="),
Set("+", "-"),
Set("*", "%")
)
// 操作符到对应优先级的映射关系
private val precedence = {
val assocs =
for {
i <- 0 until opGroups.length
op <- opGroups(i) // 嵌套生成器(双重for)
} yield op -> i
assocs.toMap
}
// 一元操作符优先级=opGroups.length
// 分数优先级=-1
private val unaryPrecedence = opGroups.length
private val fractionPrecedence = -1
private def format(e: Expr, enclPrec: Int): Element =
e match {
case Var(name) =>
elem(name)
case Number(num) =>
def stripDot(s: String) =
if (s.endsWith(".0")) s.substring(0, s.length-2)
else s
elem(stripDot(num.toString))
case OneOp(op, arg) =>
elem(op) beside format(arg, unaryPrecedence)
case TwoOp("/", left, right) =>
val top = format(left, fractionPrecedence)
val bot = format(right, fractionPrecedence)
val line = elem('-', top.width max bot.width, 1)
val frac = top above line above bot // 结果由上、线、下构成
if (enclPrec != fractionPrecedence) frac // 不是分数直接返回
else elem(" ") beside frac beside elem(" ") // 是分数, 结果两边各加一个空格
case TwoOp(op, left, right) =>
val opPrec = precedence(op)
val l = format(left, opPrec)
val r = format(right, opPrec+1) // 优先级+1
val oper = l beside elem(" " + op + " ") beside r
if (enclPrec <= opPrec) oper
else elem("(") beside oper beside elem(")")
}
// 公共的format
def format(e: Expr): Element = format(e, 0)
}
object ComplcatedExample {
def main(args: Array[String]): Unit = {
val f = new ExprFormatter
val e1 = TwoOp("*", TwoOp("/", Number(1), Number(2)),
TwoOp("+", Var("x"), Number(1)))
val e2 = TwoOp("+", TwoOp("/", Var("x"), Number(2)),
TwoOp("/", Number(1.5), Var("x")))
val e3 = TwoOp("/", e1, e2)
def show(e: Expr) = println(f.format(e) + "\n\n")
for (e <- Array(e1, e2, e3)) show(e)
}
}
结果:
