Spark的深入浅出
Spark的简介
维基百科:
Apache Spark是一个开源的集群运算框架,最初是由加州大学柏克莱分校AMPLab所开发.相对于Hadoop的MapReduce会在运行完工作后将中介数据存放到磁盘中,Spark使用了内存运算技术,能在数据尚未写入硬盘时在内存分析运算.Spark在内存内运算速度能做到比Hadoop MapReduce的运算速度快100倍,即便是运行程序于硬盘时,Spark也能快上10倍速度。[1]Spark允许用户将数据加载至集群内存,并多次对其进行查询,非常适合用于机器学习算法。
使用Spark需要搭配集群管理员和分布式存储系统。Spark支持独立模式(本地Spark集群)、Hadoop YARN或Apache Mesos的集群管理。[3] 在分布式存储方面,Spark可以和HDFS[4]、 Cassandra[5] 、OpenStack Swift和Amazon S3等接口搭载。 Spark也支持伪分布式(pseudo-distributed)本地模式,不过通常只用于开发或测试时以本机文件系统取代分布式存储系统。在这样的情况下,Spark仅在一台机器上使用每个CPU核心运行程序。
为什么使用Spark?
Hadoop的MapReduce计算模型存在问题:
Hadoop的MapReduce的核心是Shuffle(洗牌).在整个Shuffle的过程中,至少产生6次I/O流.基于MapReduce计算引擎通常会将结果输出到次盘上,进行存储和容错.另外,当一些查询(如:hive)翻译到MapReduce任务是,往往会产生多个Stage,而这些Stage有依赖底层文件系统来存储每一个Stage的输出结果,而I/O的效率往往较低,从而影响MapReduce的运行速度.
Spark的特点: 快, 易用, 通用,兼容性
(1) 快:
与Hadoop的MapReduce相比,Spark基于内存的运算速度要快100倍上,即使基于硬盘的运算速度也快10倍.Spark实现了搞笑的DAG的执行引擎,从而可以通过内存来高效处理流数据.
(2)易用:
Spark 支持 Java、Python 和 Scala 的 API,还支持超过 80 种高级算法,使用户可以
快速构建不同的应用。而且 Spark 支持交互式的 Python 和 Scala 的 shell,可以非常方
便地在这些 shell 中使用 Spark 集群来验证解决问题的方法
(3)通用:
Spark提供了统一的解决方案.Spark可以用于批处理,交互式查询(Spark SQL).实时流处理(Spark Streaming),机器学习和图计算(GraphX),这些不同类型的处理都可以在同一应用中无缝使用.Spark统一的解决方案非常具有吸引力,毕竟任何公司都想用统一的平台去处理遇到的问题,减少开发和维护的人力成本和部署平台的物力成本。
另外Spark还可以很好的融入Hadoop的体系结构中可以直接操作HDFS,提供Hive on Spark , Pig on Sparkde 框架集群成Hadoop.
(4)兼容性:
Spark 可以非常方便地与其他的开源产品进行融合。比如,Spark 可以使用Hadoop 的 YARN 和 Apache Mesos 作为它的资源管理和调度器.并且可以处理所有 Hadoop 支持的数据,包括 HDFS、HBase 和 Cassandra 等。这对于已经部署Hadoop 集群的用户特别重要,因为不需要做任何数据迁移就可以使用 Spark 的强大处理能力。Spark 也可以不依赖于第三方的资源管理和调度器,它实现了Standalone 作为其内置的资源管理和调度框架,这样进一步降低了 Spark 的使用门槛,使得所有人都可以非常容易地部署和使用 Spark。此外,Spark 还提供了在EC2 上部Standalone 的 Spark 集群的工具。
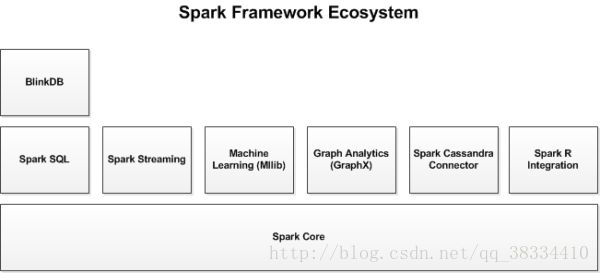
Spark的生态系统
1.Spark Streaming:
Spark Streaming基于微批量方式的计算和处理,可以用于处理实时的流数据.它使用DStream,简单来说是一个弹性分布式数据集(RDD)系列,处理实时数据.数据可以从Kafka,Flume,Kinesis或TCP套接字等众多来源获取,并且可以使用由高级函数(如 map,reduce,join 和 window)开发的复杂算法进行流数据处理。最后,处理后的数据可以被推送到文件系统,数据库和实时仪表板。
Spark SQL
SPark SQL可以通过JDBC API将Spark数据集暴露出去,而且还可以用传统的BI和可视化工具在Spark数据上执行类似SQL的查询,用户哈可以用Spark SQL对不同格式的数据(如Json, Parque以及数据库等)执行ETl,将其转化,然后暴露特定的查询.
Spark MLlib
MLlib是一个可扩展的Spark机器学习库,由通用的学习算法和工具组成,包括二元分类、线性回归、聚类、协同过滤、梯度下降以及底层优化原语。
Spark Graphx:
GraphX是用于图计算和并行图计算的新的(alpha)Spark API。通过引入弹性分布式属性图(Resilient Distributed Property Graph),一种顶点和边都带有属性的有向多重图,扩展了Spark RDD。为了支持图计算,GraphX暴露了一个基础操作符集合(如subgraph,joinVertices和aggregateMessages)和一个经过优化的Pregel API变体。此外,GraphX还包括一个持续增长的用于简化图分析任务的图算法和构建器集合。
除了这些库意外,还有一些其他的库,如Blink和Tachyon.
BlinkDB是一个近似查询 引擎,用于海量数据执行交互式SQL查询.BlinkDB可以通过牺牲数据精度来提升查询响应时间.通过在数据样本上执行查询并展示包含有意义的错误线注解的结果,操作大数据集合.
Tachyon是一个以内存为中心的分布式文件系统,能够提供内存级别速度的跨集群框架(如Spark和mapReduce)的可信文件共享.它将工作集文件缓存在内存中,从而避免到磁盘中加载需要经常读取的数据集,通过这一机制,不同的作业/查询和框架可以内存级的速度访问缓存文件.
此外,还有一些用于与其他产品集成的适配器,如Cassandra(Spark Cassandra 连接器)和R(SparkR)。Cassandra Connector可用于访问存储在Cassandra数据库中的数据并在这些数据上执行数据分析。
下图为Spark的生态系统,各库的相互关联:
Spark的体系架构
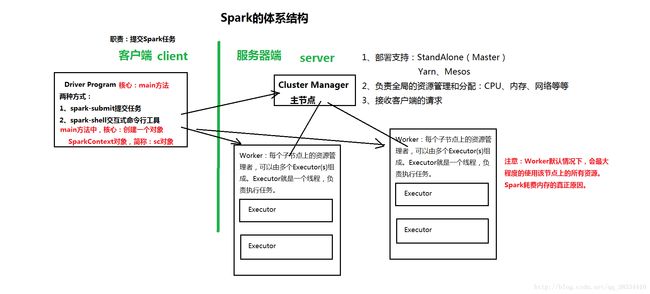
Spark架构采用了分布式计算中的Master-Slave模型。Master是对应集群中的含有Master进程的节点,Slave是集群中含有Worker进程的节点。Master作为整个集群的控制器,负责整个集群的正常运行;Worker相当于是计算节点,接收主节点命令与进行状态汇报;Executor负责任务的执行;Client作为用户的客户端负责提交应用,Driver负责控制一个应用的执行.
Spark集群部署后,需要在主节点和从节点分别启动master进程和Worker进程,对整个集群进行控制.在一个Spark应用的执行程序中.Driver和Worker是两个重要的角色.Driver程序是应用逻辑执行的起点,负责作业的调度,即Task任务的发布,而多个Worker用来管理计算节点和创建Executor并行处理任务.在执行阶段,Driver会将Task和Task所依赖的file和jar序列化后传递给对应的Worker机器.同时Executor对相应数据分区的任务进行处理.
Sparkde架构中的基本组件:
- ClusterManager:在standlone模式中即为Master(主节点),控制整个集群.监控Worker.在Yarn模式中为资源管理器.
- Worker:从节点,负责控制计算节点,启动Ex而粗投入或Driver
- NodeManager:负责计算节点的控制。
- Driver:运行Application的main() 函数并创建SparkContext
- Executor: 执行器,在worker node上执行任务组件,用于启动线程执行任务.每个Application拥有独立的一组Executors
- SparkContext: 整个应用的上下文,监控应用的生命周期
- RDD:弹性分布式集合,spark的基本计算单元,一组RDD可形成执行的有向无环图RDD Graph
- DAG Scheduler: 根据作业(Job)构建基于Stage的DAG,并交给Stage给TaskScheduler
- TaskScheduler:将任务(Task)分发给Executor执行
- SparkEnv:线程级别的上下文,存储运行时的重要组件的引用。SparkEnv内创建并包含如下一些重要组件的引用。
- MapOutPutTracker:负责Shuffle元信息的存储。
- BroadcastManager:负责广播变量的控制与元信息的存储。
- BlockManager:负责存储管理、创建和查找块。
- MetricsSystem:监控运行时性能指标信息。
- SparkConf:负责存储配置信息。
Spark的整体流程:client提交应用,Master找到一个Worker启动Driver,Driver向Master或者向资源管理器申请资源,之后将应用转化为RDD Graph,再由DAGScheduler将RDD Graph转化为Stage的有向无环图提交给TaskScheduler,由TaskScheduler提交任务给Executor执行。在任务执行的过程中,其他组件协同工作,确保整个应用顺利执行。
spark的基本工作原理
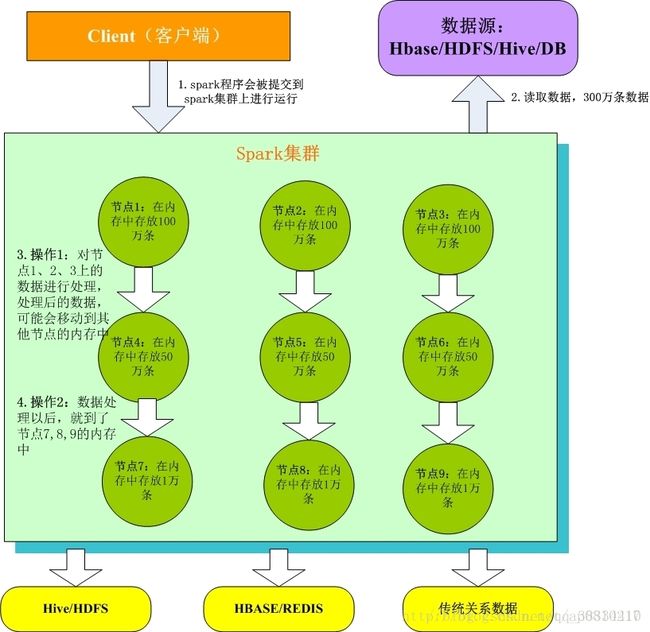
1.Client客户端:我们在本地编写了spark程序,打成jar包,或python脚本,通过spark submit命令提交到Spark集群;
2.只有Spark程序在Spark集群上运行才能拿到Spark资源,来读取数据源的数据进入到内存里;
3.客户端就在Spark分布式内存中并行迭代地处理数据,注意每个处理过程都是在内存中并行迭代完成;注意:每一批节点上的每一批数据,实际上就是一个RDD!!!一个RDD是分布式的,所以数据都散落在一批节点上了,每个节点都存储了RDD的部分partition。
4.Spark与MapReduce最大的不同在于,迭代式计算模型:MapReduce,分为两个阶段,map和reduce,两个阶段完了,就结束了,所以我们在一个job里能做的处理很有限; Spark,计算模型,可以分为n个阶段,因为它是内存迭代式的。我们在处理完一个阶段以后,可以继续往下处理很多个阶段,而不只是两个阶段。所以,Spark相较于MapReduce来说,计算模型可以提供更强大的功能。
RDD以及一些特性
1. RDD是Spark提供的核心抽象,全称为Resillient Distributed Dataset,即弹性分布式数据集;
2. RDD在抽象上来说是一种元素结合,包含看数据.它是被分区的,分为多个分区,每个分区分布在集群中的不同节点上,从而让RDD中的数据可以被并行操作。(分布式数据集)
3. RDD通常通过Hadoop上的文件,即HDFS文件或者Hive表,来进行创建;有时也可以通过应用程序中的集合来创建;
4. RDD最重要的特性就是,提供了容错性,可以自动从节点失败中恢复过来。即如果某个节点上的RDD partition,因为节点故障,导致数据丢了,那么RDD会自动通过自己的数据来源重新计算该partition。这一切对使用者是透明的;
5. RDD的数据默认情况下存放在内存中的,但是在内存资源不足时,Spark会自动将RDD数据写入磁盘
问题:RDD分布式是什么意思?
一个RDD,在逻辑上,抽象地代表了一个HDFS文件;但是,它实际上是被分为多个分区;多个分区散落在Spark集群中,不同的节点上。比如说,RDD有900万数据。分为9个partition,9个分区。
问题:RDD弹性是什么意思,体现在哪一方面?
RDD的每个partition,在spark节点上存储时,默认都是放在内存中的。但是如果说内存放不下这么多数据时,比如每个节点最多放50万数据,结果你每个partition是100万数据。那么就会把partition中的部分数据写入磁盘上,进行保存。
而上述这一切,对于用户来说,都是完全透明的。也就是说,你不用去管RDD的数据存储在哪里,内存,还是磁盘。只要关注,你针对RDD来进行计算,和处理,等等操作即可。所以说,RDD的这种自动进行内存和磁盘之间权衡和切换的机制,就是RDD的弹性的特点所在。
问题:RDD容错性体现在哪方面?
比如:节点9出了些故障,导致partition9的数据丢失了。那么此时Spark会脆弱到直接报错,直接挂掉吗?不可能!!
RDD是有很强的容错性的,当它发现自己的数据丢失了以后,会自动从自己来源的数据进行重计算,重新获取自己这份数据,这一切对用户,都是完全透明的。