行人重识别(Person Re-ID)【三】:论文笔记——Joint Detection and Identification Feature Learning for Person Search
论文:Joint Detection and Identification Feature Learning for Person Search
链接:https://arxiv.org/abs/1604.01850
前言:
这篇是CVPR2017关于行人重识别(Person Re-ID)的文章,由港中文、中山大学和商汤联合提出。本文主要提出了一种行人搜索的新框架,把传统的两门独立的研究任务——行人检测和行人重识别结合起来研究,且只需要使用单个CNN来进行训练,真正意义上实现了end-to-end训练;同时本文还提出了一种OIM损失(Online Instance Matching)来训练网络,它比一般的Softmax损失函数的效果更快更好。
现有主流的行人重识别方法中所使用的数据和方法主要集中在经过裁剪的行人照片,也就是人为或者通过算法把行人完美地裁切出来了,如下图(a)所示,这对单独研究如何提升行人重识别准确率等方面肯定是有利的,毕竟减少了很多背景的干扰;

但是经裁切的行人图片明显与现实场景中的图片如摄像头抓拍的行人全景图片(如下图(b))差异较大,如果直接把全景图送进神经网络去提取特征,效果肯定是比经裁切的行人图片要差很多的,因为行人重识别本身就存在诸多难点需要克服,如人物的姿态时常是变化的,因为人本身不是刚体(不像汽车那样固定形态),摄像机的角度,光照强弱,像素,遮挡,背景干扰等等,所以如果用的是全景图片进行训练而不加入其他的手段辅助训练,只会让这些难点放大化,达不到很好的效果。

为了使得ReID领域可以尽快达到商用的价值,需要逐步缩小这种差距,怎么做?
与传统方法中将行人检测和再识别分成两个问题单独研究不同,本文利用单个CNN将两者结合来同时解决这些问题,该CNN分为两部分:第一部分是pedestrian proposal net,给定一张行人全景图,pedestrian proposal net可以产生候选行人的 bounding boxes,在后续CNN会将这些bounding boxes输入给identification net进行特征的提取,从而匹配目标人物;另一部分是刚刚提到的identification net,主要是用来提取行人的特征和检索目标进行比较。两者在joint optimization联合优化的过程中具有相互适应的特点,从而消除自身外另一网络带来的问题。对这点的解释是:pedestrian proposal net因为是用来产生候选行人的 bounding boxes,所以更注重的是召回率recall,希望能把行人给找齐,而那些错误的目标或者是框没有匹配对都可以通过后续的identification net来修正,所以说它们各司其职,分工明确,合作提高网络识别的准确程度。同时通过部分共享卷积层,可以有效的加速网络的学习。
本文的另一个亮点就是提出了OIM损失(Online Instance Matching)。传统的行人重识别的特征学习主要使用pair-wise或者triplet distance loss functions,但是这两种方法都不是很有效的,因为它们一次都只能用少量的数据做比较,对于N个输入数据,会存在N^2组合的可能性,这会导致计算量很大,特别是当N很大的时候,网络会学习得很慢,而目前有研究提出采用不同的采样数据的方法可以在一定程度上提高速度和效果,比如triplet loss就有很多种变种形式,但是当N不断增加时,采样难度也在提升;另一种常用的方法就是使用Softmax loss function去区分行人的身份identities,就把行人重识别问题当成是多分类问题去做,这样就解决了pair-wise或者triplet distance loss functions不能一次比较所有样本的缺陷,但是Softmax loss function也存在它的缺点,就是随着行人类型(不同身份的人)数量的增多,训练一个如此庞大的Softmax 分类器会变得及其的慢,甚至更糟糕的时候网络会无法收敛。
所以为了解决上面pair-wise、triplet distance loss functions以及Softmax loss function带来的问题,本文提出 Online Instance Matching(OIM)损失函数。OIM的原理是:利用来自所有 labeled identities 特征组成一个 lookup table(查询表) ,与mini-batch样本之间进行距离比较;另外还有全景图中出现的许多 unlabeled identities 都可以被视为是天然的negatives(负样本),因此也可以将它们的特征存储在circular queue(循环队列)中并进行比较。这也是行人重识别加上行人搜索后带来的一个天然优势,因为传统的行人重识别都是采用裁切好的行人图像,自然就不会存在那些没有label的人参与训练了。而且OIM损失函数是无参数的,在后面的实验结果可以看出,它是比 Softmax loss 收敛得更快和更好的。
因为这里涉及到很多新的概念如 labeled identities 、unlabeled identities、lookup table 和 circular queue,如果不解释一下,后面可能读者会看不太明白:
labeled identity:与目标行人相吻合的proposal。
unlabeled identities:包含行人但不是目标行人的proposal。
background clutter:包含非行人物体或者背景的proposal。
在OIM损失函数中只考虑前两者,即 labeled identity 和 unlabeled identities。
lookup table(LUT):把所有 labeled identities 的特征组成一个查询表lookup table,那么之后我只需要将需要查询的mini-batch的每个样本去跟这个查询表的已知标签的样本进行距离比较,就可以知道当前的这个人是什么身份了。
circular queue:跟LUT同理,我们把 unlabeled identities 当作是负样本,也可以存在一个循环队列circular queue中,为什么这边不也一样叫LUT,这是因为这里的circular queue在每一轮迭代过后,会将新的特征向量压入队列中,并剔除那些过时的,呈现一个循环的过程。
本文还有第三个贡献,就是收集和标注了一个大规模的行人搜索数据集,覆盖了城市街道的场景以及电影中包含有行人的截图,加入电影的图片是为了增加场景的多样性,如下表Table 1 所示,该数据集包括18184张图片,8432个身份(人),96143个行人bounding boxes。

具体方法:
下面文章详细介绍了如何实现本文提出的方法,主要过程参考Figure 2:

先大概介绍一下流程:
1)给定一张行人全景图,首先利用一个stem CNN 将原始图像像素转换成 feature maps,然后之前提到过的 pedestrian proposal net 就建立在这些feature maps上,来预测生成候选行人的 bounding boxes;
2)将上述生成的 bounding boxes 送入能够进行 RoI-Pooling 的 identification net 来提取经L2正则化后的每个box的256维特征;
3)在推测阶段,利用 gallery person (库里的行人,已知标签)和目标行人之间的 features distances 来进行排序;
4)在训练阶段,根据feature vectors,使用OIM loss function以及一些其他的loss functions作为辅助来同时监督 identification net的学习,以多任务的方式来训练网络。
接下来文章先介绍了CNN网络的结构:
1)文中采用了ResNet-50作为CNN模型的网络结构,在网络的前端有一个7 × 7的卷积层(conv1),之后是4个blocks块(conv2_x到conv5_x,分别有3、4、6、3个残差模块),利用其中的conv1到 conv4_3之间的部分作为stem CNN的部分。给定一张输入图片,stem CNN会产生1024个通道的 features maps,它们的分辨率只有原图像的十六分之一;
2)根据生成的这些features maps,利用512 × 3 × 3的卷积层来对行人特征进行转换,接着在feature map的每个位置利用9个anchors(源于Faster RCNN)和1个Softmax分类器来预测每个anchor是否包含行人在内,同时还包括了1个线性回归器来调整anchors的位置。在NMS过后仅保留128个调整后的bounding boxes作为最终的proposals;
3)为了在这些proposals(128个)里找到目标行人,建立 identification net 来提取每个proposal的特征,并将其与目标行人进行比较。首先利用 RoI Pooling 层从stem feature map中得到1024 × 14 × 14的区域(对应于每个proposal),接着将它们送入ResNet-50的剩下的conv4_4至conv5_3层(因为之前只用了其中的conv1到 conv4_3之间的部分作为stem CNN),后面再接一个 global average pooling 层将其整合为2048维的特征向量;
4)另一方面,pedestrian proposal net 生成的 pedestrian proposals 中会不可避免地会包含一些 false alarms(也就是proposal里包含的不是行人)和 misalignments(也就是框没有对齐行人),因此再次利用Softmax分类器和线性回归器来拒绝非行人的区域并精修proposal的位置。另一方面,我们将特征投影到经过L2正则化后的256维向量子空间中,并在推测阶段计算它们和目标行人的余弦相似度。
下面介绍一下OIM,也就是Online Instance Matching 损失函数:
前面我们已经介绍过了多种不同情况的 proposals ,如labeled identity、unlabeled identities 和 background clutter。不记得的小伙伴可以往前面翻阅查看。
如下Figure 3所示:
假设训练集中有L个不同身份的人,当一个 proposal 匹配上了目标行人,就称这个 proposal 为 labeled identity,如下图蓝色框框的 proposals ,即与目标行人相吻合的proposal ,然后相应的给这个 proposal 分配一个1到L之间的类别id(L个类的其中一个);同样,也有很多 proposals 成功检测到了行人,但不是目标行人的proposals,称这些proposals 为unlabeled identities ,如下图橙色框框的 proposals ;最后,有一些 proposals 错误地包含了非行人物体或者背景区域,这些 proposals 称为background clutter。
在OIM损失函数中只考虑前两者,即 labeled identity 和 unlabeled identities。

因为目标是为了区分开不同id的人,一个很自然很常用的方法就是缩小相同id人的特征距离,同时增大不同id的人的特征距离,为了实现这个目的,我们需要存储所有人的特征。对所有训练集图像同时进行网络的前向传递就可以实现,但这对于SGD优化器来说是不实际的,因为随机梯度下降每次只取一个mini-batch,不可能把所有训练集图像一次包含进去训练,所以本文并未选择SGD进行优化,而是采用了 online approximation。
mini-batch中一个labeled identity的特征被记为记为x(x是D维特征向量),之后生成一个 lookup table V(LUT,查询表,前面有介绍过,Figure 3中右上角的蓝色格子),V用来记录所有labeled identity的特征(D×L 维矩阵,D是上面的x的维度,也就是一个labeled identity的特征维度;L是不同id的人,就是L个类;所以D×L 维矩阵就是整个LUT的维度)。
在前向传播中,计算mini-batch中每个样本与所有labeled identities之间的的余弦相似度(![]() );在反向传播过程中,如果目标行人的分类标签id是t,那么就可以利用下面的公式来更新LUT中的第t行,具体某一个id的 labeled identitie的特征值
);在反向传播过程中,如果目标行人的分类标签id是t,那么就可以利用下面的公式来更新LUT中的第t行,具体某一个id的 labeled identitie的特征值 ![]() :
:

(其中,![]() ,并需要对
,并需要对![]() 进行L2正则化)
进行L2正则化)
除了 用到 labeled identities 之外,那些 unlabeled identities .也就是全景图中出现的许多 unlabeled identities 对于学习特征的表达也是很有价值的, 可以被视为是天然的negatives(负样本),使用 circular queue 来保存那些出现在当前 mini-batch 中的那些 unlabeled identities 的特征,用U来表示(![]() ,D×Q维矩阵,Q是queue队列的大小,在实验中设置为5000),同样也可以计算U与mini-batch样本之间的余弦相似度。每一轮迭代过后,将新的特征向量压入队列中,并剔除那些过时的,从而保持queue大小不变,这也是circular queue和LUT的区别。
,D×Q维矩阵,Q是queue队列的大小,在实验中设置为5000),同样也可以计算U与mini-batch样本之间的余弦相似度。每一轮迭代过后,将新的特征向量压入队列中,并剔除那些过时的,从而保持queue大小不变,这也是circular queue和LUT的区别。
基于上面提到的 LUT 和 circular queue 这两种特殊的数据结构类型,通过softmax函数定义某个 labeled identity 的特征x被视为第i类行人的概率为:

(其中![]() 控制了概率分布的平缓程度,在实验中公式(1)、(2)的
控制了概率分布的平缓程度,在实验中公式(1)、(2)的![]() 均设置为0.1)
均设置为0.1)
同样,在 circular queue 中,x被视为第i类 unlabeled identity 的概率为:

OIM损失函数最终优化的目标是使得期望似然函数最大化:

![]() 对x的梯度可以表示为:
对x的梯度可以表示为:
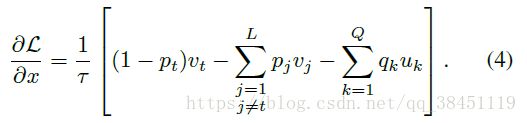
所以,从公式(1)、(2)可以看出,OIM损失函数有效地将mini-batch里的样本和 labeled identity 和 unlabeled identity 进行了对比,即实现了缩小相同id人的特征距离,同时增大不同id的人的特征距离的目的。
为什么这里不用softmax损失函数,而是提出新的OIM损失函数,本文也给出了详细的解释:
主要有两点原因,首先,大规模行人搜索数据集里的行人类别太多(通常大于5000个id),并且每个id对应的实例较少,每张图片包含的id数目也很少,同时需要学习超过5000个的判别函数,而在那么多类中,每次SGD只有很少量的positive samples,因此分类矩阵的梯度变化很大,不能被很好地学习;
其次第二个原因就是,Softmax loss无法利用unlabeled identities的有用信息,因为在Softmax loss中它们没有明确的类别标识,因此没办法参与训练。
OIM与Softmax loss其实很像,主要的区别在于OIM损失是非参数化的,LUT和circular queue被认为是外部记忆单元,而非网络的参数。但这种无参数的损失函数有一个潜在的缺点就是容易过拟合,所以文中将特征映射到经过L2正则化之后的低维子空间中可以帮助解决过拟合的问题。
当行人种类id逐渐增加时,前面的公式(1)和(2)计算起来会比较费时,为了克服这个问题,采用了对labeled和unlabeled identities进行二次采样的方法来近似分母:
数据集:
接下来,文章就介绍了用到的数据集:
本文收集和标注了一个大规模的行人搜索数据集来评估上面提出的方法,收集了两类不同的数据集,一类是在城市里用照相机拍下来的照片,另一类是电影中包含有行人的截图,目的是为了增加视角、光照和背景的多样性。
该数据集一共包含18184张图片,总共标注了 96143 个行人的bounding boxes以及8432个 labeled identity,具体数据的数量和内容在下面的Table 1中可以看到:

那些只有半个身子的人以及不正常的姿势(不是站立直行,而是坐下或蹲着的)的人没有被标注,跟传统的ReID一样,那些换了衣服和装饰的同id的人也不会被标注,因为仅靠人脸是很难识别出这个人的身份的,所以换了衣服和装饰对ReID的识别准确率影响很大。同时忽略那些高度低于50个像素点的背景行人,因为即使是人的肉眼去识别,也很难看出他们的身份,更别说机器了。
不同像素的labeled和unlabeled identities的高度分布如下图Figure 4所示,可以看出本文的数据集在行人的尺寸上有丰富的变化性:

数据集被分为训练集和测试集,训练集和测试集之间不会有相同id人的图片的重复出现,保证了检验的可靠性。其中测试集中的行人又被分为queries(待查询输入)和galleries(候选行人库),不懂的同学可以查看我的另一篇博文,有详细介绍行人重识别中的常用评测指标:
行人重识别(Person Re-ID)【一】:常用评测指标
总共大约有2900个test identities,并随机抽取其中之一作为query,而对应的gallery包含2部分:所有包含其他实例的图片和随机抽取的不包含query的图片。
为了更好地探究gallery(候选行人库)的size(数目)如何影响行人搜索的效果,将gallery size设置成从50到4000,拿gallery size=100为例,每一张图片大约包含了6个行人,那么一共就有100*6=600个行人,我们的任务就是从这600个人中找到目标行人。这样的设置和已有的ReID数据集(如CUHK-03和VIPeR)的gallery数量差不多,甚至更具有挑战性,因为这里包含了很多无关的背景bounding boxes混淆注意力。
采用了两种评价机制:CMC top-K和mAP,在我的另一篇博文 行人重识别(Person Re-ID)【一】:常用评测指标 也有介绍。
CMC是行人重识别中常用的评价机制,需要满足:top-K个预测bounding boxes中至少有一个box与ground truths有重合,且IoU要大于等于0.5,则说明产生了匹配。mAP则是目标检测任务中常用的评价机制,沿用了ILSVRC目标检测标准。
实验:
下面就文章的实验部分了,文章对各种影响因素做了相当多的实验工作,值得我们学习:
文章是基于caffe框架和faster rcnn算法为基础的,用了基于ImageNet 的ResNet50的预训练模型
所有用到的loss都有一样的损失权重,每一个mini-batch有2张全景图,学习率初始化为0.001,在4万次迭代后下降到0.0001,然后保持不变直到模型在大约5万次迭代的时候达到收敛。
文中将3种行人检测和5种行人再识别方法进行组合(所有共有15个组合)。行人检测方法包括CCF、ACF和基于Resnet50的Faster R-CNN。ground truth (GT)也作为其中一种detector.加入实验中进行比较。
recall-precision curve的结果如下图Figure 5所示:

对于行人重识别部分,使用了主流的 DSIFT、BoW 和 LOMO,并将它们与 Euclidean、 Cosine similarity、KISSME 以及 XQDA这些特殊的距离度量方法进行结合。
文中为了进行对比实验,把不使用 pedestrian proposal net 网络,并使用softmax loss作为损失函数,使用裁切后的图像,且只训练剩余部分,得到的基础模型称为IDNet。实验发现,训练IDNet时,加入 background clutter 作为其中的一个类,可以有效提高识别结果,而加入 unlabeled identity 就不行了。
后面gallery size都默认是100。
下面,文章比较了本文提出的行人搜索框架(加或不加unlabeled identity)和其他15种将行人检测和重识别任务划分为二的基础组合模型,结果如下表Table 2所示:
可以看出不管是CMC或者mAP两项评价指标,本文提出的方法均遥遥领先于其他方法。与IDNet方法相同,提升的原因,主要是:检测和重识别两项任务的有效结合,互相提升,以及在OIM loss中有效地使用了unlabeled identity 来监督学习。

从Table2中我们也可以看出,行人检测中 detectors 检测器的选择对行人重识别任务的效果提升尤为关键,我们可以看到CCF、ACF、CNN和GT之间的差别都是巨大的,直接使用现有的 detector 对现实生活中的行人检测任务来说并不是最优的,否则 detector 很可能就会成为限制行人重识别任务效果的一个瓶颈。
OIM与Softmax的对比,training identification accuracy 和 test personsearch mAP curves 如下图Figure 6所示:
可以看出,使用softmax不加预训练的在整个过程中都是保持一个很低的accuracy,之前提过,当id数量很大时,训练1个softmax是很困难的,即使加了预训练,softmax提升得还是很慢,最终的test mAP维持在60%左右。
相反,OIM一开始的training identification accuracy很低,但是收敛得很快,并持续地在test mAP有提升,因为无参数化的OIM loss不需要像softmax一样直接去学习一个庞大的分类矩阵

随后,文章用Inception和Resnet50基于softmax loss 和 OIM loss训练模型,然后分别在CUHK03、Market1501和Duke这3个大规模的ReID数据集上进行评估,以CMC top-1 accuracy作为评价指标。
如下表Table 3所示,不管是用Inception还是Resnet50作为base CNN,不管在哪个数据集上进行评估,OIM loss总是完胜softmax loss。

前面提到过,当行人种类id逐渐增加时,OIM的公式(1)和(2)计算起来会比较费时,为了克服这个问题,文章采用了对labeled和unlabeled identities进行二次采样的方法来近似分母。
使用二次采样后的mAP曲线如下图,二次采样的大小分别用了10,100和1000,评价指标为mAP:

OIM这种无参数的损失函数有一个潜在的缺点就是容易过拟合,所以文中将特征映射到经过L2正则化之后的低维子空间中可以帮助解决过拟合的问题。所以文章又通过实验探究L2正则化之后的低维子空间维度大小如何影响行人搜索任务的表现。
结果如下表Table 4所示:

表中的N/A表示直接使用L2正则化后的2048维的特征向量,即不映射到低维子空间,可以看到效果是最差的。这就说明了将特征映射到经过L2正则化之后的低维子空间的重要性,实验中,256到1024维有差不多的测试效果,最后文章选择了256维作为映射的低维子空间的维度,从而加速特征距离的计算,防止过拟合。
接下来文章固定使用了LOMO+XQDA方法,然后探究detection recalls 如何影响行人搜索任务的表现,通过设置不同的阈值也就是检测到行人的阈值宽松。
低的阈值可以提高召回率,但是错检会很多;因此实验从30%的detection recall rate开始做。
下图是detection recall rates对mAP的影响:
可以看出高的detection recall rate不一定就会导致最优的mAP,所以我们不能单一地用裁切好的行人图像去训练,而是要结合行人搜索中的方法,以及unlabeled identities和background clutter。

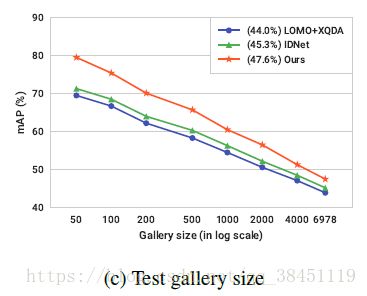
最后就是探究 gallery size 对mAP的影响了,也是本文的最后一个实验。
当 gallery size 数量提升,行人搜索会变得越来越难。文章用不同的方法(3种),然后gallery size设置从50到最大数目6978,进行了实验,测试结果如下图所示:
及时用很小的gallery size,所有的test 图像都能收敛,而不同方法之间的差距,随着gallery size的增大逐渐变小,因为所有方法到最后都会遇到这些hard samples(难例)的影响,影响程度很大,所以后续的工作可以考虑如何基于hard example minings(难例采样)的方法去提升模型的效果。
总结:
本文提出了解决行人搜索问题的一种新框架,将行人检测和行人重识别这两个过去常常分开研究的问题结合起来研究,利用单个CNN联合训练。在网络的训练过程中使用了提出的OIM损失函数,效果十分明显,无参数化也使得更快和更好的表现结果,从而可以应用到更大规模的数据集中。