深度学习:YOLO v3(darknet)——训练自己的VOC数据
论文:YOLOv3: An Incremental Improvement
论文地址:https://pjreddie.com/media/files/papers/YOLOv3.pdf
darknet代码:https://github.com/AlexeyAB/darknet#how-to-compile-on-linux
本文配置的方法也主要是参考 https://github.com/AlexeyAB/darknet#how-to-compile-on-linux 下面的介绍。
配置及训练主要是下面5个步骤,每个步骤里面有细分:
一、编译darknet
github上有关于linux和windows的darknet的配置方法,因为我是在Ubuntu下,所以本文只介绍linux下的配置
1.下载源码
终端输入:
https://github.com/AlexeyAB/darknet.gitgitclone代码下来或者自己手动下载从github上下下来,然后解压。
2.修改Makefile文件
其他文件都不用动,只需要修改Makefile文件
未修改前的Makefile文件如下:
GPU=0
CUDNN=0
OPENCV=0
DEBUG=0
OPENMP=0
LIBSO=0
ARCH= -gencode arch=compute_20,code=[sm_20,sm_21] \
-gencode arch=compute_30,code=sm_30 \
-gencode arch=compute_35,code=sm_35 \
-gencode arch=compute_50,code=[sm_50,compute_50] \
-gencode arch=compute_52,code=[sm_52,compute_52] \
-gencode arch=compute_61,code=[sm_61,compute_61]
# This is what I use, uncomment if you know your arch and want to specify
# ARCH= -gencode arch=compute_52,code=compute_52
VPATH=./src/
EXEC=darknet
OBJDIR=./obj/
ifeq ($(LIBSO), 1)
LIBNAMESO=darknet.so
APPNAMESO=uselib
endif
CC=gcc
CPP=g++
NVCC=nvcc
OPTS=-Ofast
LDFLAGS= -lm -pthread
COMMON=
CFLAGS=-Wall -Wfatal-errors
ifeq ($(DEBUG), 1)
OPTS=-O0 -g
endif
CFLAGS+=$(OPTS)
ifeq ($(OPENCV), 1)
COMMON+= -DOPENCV
CFLAGS+= -DOPENCV
LDFLAGS+= `pkg-config --libs opencv`
COMMON+= `pkg-config --cflags opencv`
endif
ifeq ($(OPENMP), 1)
CFLAGS+= -fopenmp
LDFLAGS+= -lgomp
endif
ifeq ($(GPU), 1)
COMMON+= -DGPU -I/usr/local/cuda/include/
CFLAGS+= -DGPU
LDFLAGS+= -L/usr/local/cuda/lib64 -lcuda -lcudart -lcublas -lcurand
endif
ifeq ($(CUDNN), 1)
COMMON+= -DCUDNN
CFLAGS+= -DCUDNN
LDFLAGS+= -lcudnn
endif
OBJ=gemm.o utils.o cuda.o convolutional_layer.o list.o image.o activations.o im2col.o col2im.o blas.o crop_layer.o dropout_layer.o maxpool_layer.o softmax_layer.o data.o matrix.o network.o connected_layer.o cost_layer.o parser.o option_list.o darknet.o detection_layer.o captcha.o route_layer.o writing.o box.o nightmare.o normalization_layer.o avgpool_layer.o coco.o dice.o yolo.o detector.o layer.o compare.o classifier.o local_layer.o swag.o shortcut_layer.o activation_layer.o rnn_layer.o gru_layer.o rnn.o rnn_vid.o crnn_layer.o demo.o tag.o cifar.o go.o batchnorm_layer.o art.o region_layer.o reorg_layer.o super.o voxel.o tree.o
ifeq ($(GPU), 1)
LDFLAGS+= -lstdc++
OBJ+=convolutional_kernels.o activation_kernels.o im2col_kernels.o col2im_kernels.o blas_kernels.o crop_layer_kernels.o dropout_layer_kernels.o maxpool_layer_kernels.o network_kernels.o avgpool_layer_kernels.o
endif
OBJS = $(addprefix $(OBJDIR), $(OBJ))
DEPS = $(wildcard src/*.h) Makefile
all: obj backup results $(EXEC) $(LIBNAMESO) $(APPNAMESO)
ifeq ($(LIBSO), 1)
CFLAGS+= -fPIC
$(LIBNAMESO): $(OBJS)
$(CPP) -shared -std=c++11 -fvisibility=hidden -DYOLODLL_EXPORTS $(COMMON) $(CFLAGS) $^ -o $@ src/yolo_v2_class.cpp $(LDFLAGS)
$(APPNAMESO): $(OBJS)
$(CPP) -std=c++11 $(COMMON) $(CFLAGS) -o $@ src/yolo_console_dll.cpp $(LDFLAGS) -L ./ -l:$(LIBNAMESO)
endif
$(EXEC): $(OBJS)
$(CC) $(COMMON) $(CFLAGS) $^ -o $@ $(LDFLAGS)
$(OBJDIR)%.o: %.c $(DEPS)
$(CC) $(COMMON) $(CFLAGS) -c $< -o $@
$(OBJDIR)%.o: %.cu $(DEPS)
$(NVCC) $(ARCH) $(COMMON) --compiler-options "$(CFLAGS)" -c $< -o $@
obj:
mkdir -p obj
backup:
mkdir -p backup
results:
mkdir -p results
.PHONY: clean
clean:
rm -rf $(OBJS) $(EXEC) $(LIBNAMESO) $(APPNAMESO)
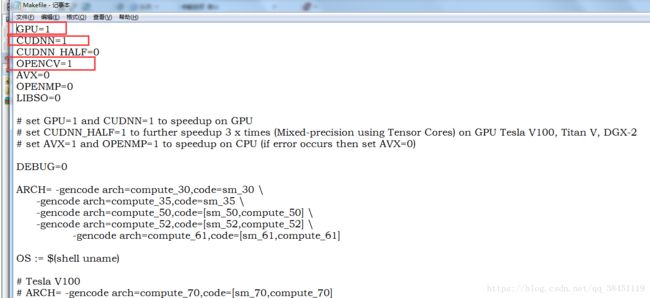
主要只是改前面几个即可,修改的参数介绍如下:
GPU=1to build with CUDA to accelerate by using GPU (CUDA should be in/usr/local/cuda)CUDNN=1to build with cuDNN v5-v7 to accelerate training by using GPU (cuDNN should be in/usr/local/cudnn)CUDNN_HALF=1to build for Tensor Cores (on Titan V / Tesla V100 / DGX-2 and later) speedup Detection 3x, Training 2xOPENCV=1to build with OpenCV 3.x/2.4.x - allows to detect on video files and video streams from network cameras or web-camsDEBUG=1to bould debug version of YoloOPENMP=1to build with OpenMP support to accelerate Yolo by using multi-core CPULIBSO=1to build a librarydarknet.soand binary runable fileuselibthat uses this library. Or you can try to run soLD_LIBRARY_PATH=./:$LD_LIBRARY_PATH ./uselib test.mp4How to use this SO-library from your own code - you can look at C++ example: https://github.com/AlexeyAB/darknet/blob/master/src/yolo_console_dll.cpp or use in such a way:LD_LIBRARY_PATH=./:$LD_LIBRARY_PATH ./uselib data/coco.names cfg/yolov3.cfg yolov3.weights test.mp4
如果你用到了GPU,那么改GPU=1,且确保你的CUDA 在 /usr/local/cuda 这个目录下;
如果你用到了Cudnn,那么改CUDNN=1,cuDNN 要在v5-v7 之间的版本,且确保你的cuDNN 在 /usr/local/cudnn这个目录下;
如果你的显卡是Titan V / Tesla V100 / DGX-2 或者后面更新的型号,那么改CUDNN_HALF=1;
如果你用到了OpenCV 3.x/2.4.x,那么改OPENCV=1;
主要改的就是上面说的这4个,其他几个可以不用管,
我改好的Makefile如下:
3.编译darknet
回到你的yolo v3的根目录
我的是/data2/lincanran/yolo3/darknet-master
然后终端输入:
make即可,完成编译!
二、下载权重
1.下载权重
从 http://pjreddie.com/media/files/darknet53.conv.74 下载卷积层的预训练权重 darknet53.conv.74文件(约154 MB)
2.放入文件夹中
官网介绍是放入 build\darknet\x64 目录中
其实也可以自己随便找个文件夹放,后面训练的时候告知路径即可
我是在yolo v3的根目录下创建了一个 names-data 的文件夹,把下载好的权重文件放进去,后续还有其他需要用到的文件也一并放在此文件夹中。
三、准备自己的数据集(VOC格式)
1.创建类似VOC数据集格式的文件夹
我们知道常规的VOC数据集,例如VOC2007的格式如下:

首先我们进入到 yolo3/darknet-master/scripts 目录里,然后创建一个VOCdevkit文件夹:

然后进入 yolo3/darknet-master/scripts/VOCdevkit 目录里,创建一个VOC2007文件夹:
然后进入 yolo3/darknet-master/scripts/VOCdevkit/VOC2007 目录里,创建类似VOC数据集下的这5个文件夹:
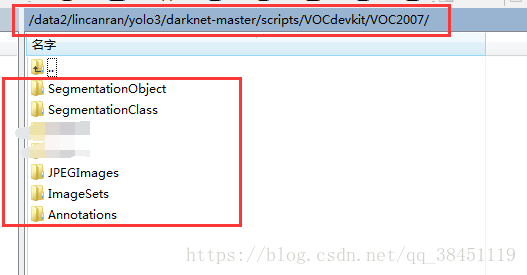
我们这里创建的文件夹格式如下所示:
VOCdevkit
|--VOC2007
|--Annotations
|--ImageSets
|--Segmentation
|--Main
|--Layout
|--JPEGImages
|--SegmentationClass
|--SegmentationObject
其实主要用到的也就 Annotations、ImageSets里的Main 和 JPEGImages 这三个文件夹
Annotations文件夹里存放xml标签文件:
ImageSets里的Main文件夹里存放训练集和验证集(这里跟我一样用test.txt就好,不要写val.txt,不然下面的文件要修改)的txt文件:

只需要图片的名称即可,而且不需要后缀名,比如我的图片是:tu1.jpg,那么我只要写tu1即可
test.txt格式如下:(train.txt一样的格式)
怎么分训练集和测试集我就不介绍啦

JPEGImages文件夹里存放训练集和验证集的图片文件(全部图片放在一起即可,到时程序会根据你的train.txt和test.txt去找你的图片和对应的标签文件,所以要保证同一张图片对应的标签文件的名称一样,仅仅是后缀名不一样而已!!!):
2.修改文件voc_label-auto.py
在 yolo3/darknet-master/scripts 目录下新建一个 voc_label-auto.py文件,即 voc_label-auto.py和刚刚第一步建立的VOCdevkit文件夹是并列关系,如下图:

voc_label-auto.py文件里主要修改的地方是:
classes = ['defect0', 'defect1', 'defect2', 'defect3', 'defect4', 'defect5', 'defect6', 'defect7', 'defect8', 'defect9']classes列表里的内容改成你自己数据的类的名称!(注意,不需要加上背景类)
sets因为刚刚我们创的文件夹就是VOC2007,而且里面的txt文件就是命名为train.txt和test.txt,所以不需要修改啦!!(这就是为什么我上面第一步叫你们不要改名字的原因,跟着我的步骤即可哈!)
下面附上我的voc_label-auto.py文件的代码:
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
from multiprocessing import Pool
sets=[('2007', 'train'), ('2007', 'test')]
classes = ['defect0', 'defect1', 'defect2', 'defect3', 'defect4', 'defect5', 'defect6', 'defect7', 'defect8', 'defect9']
def convert(size, box):
dw = 1./size[0]
dh = 1./size[1]
x = (box[0] + box[1])/2.0
y = (box[2] + box[3])/2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(year, image_id):
in_file = open('VOCdevkit/VOC%s/Annotations/%s.xml'%(year, image_id))
out_file = open('VOCdevkit/VOC%s/labels/%s.txt'%(year, image_id), 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for year, image_set in sets:
if not os.path.exists('VOCdevkit/VOC%s/labels/'%(year)):
os.makedirs('VOCdevkit/VOC%s/labels/'%(year))
image_ids = open('VOCdevkit/VOC%s/ImageSets/Main/%s.txt'%(year, image_set)).read().strip().split()
list_file = open('%s_%s.txt'%(year, image_set), 'w')
for image_id in image_ids:
list_file.write('%s/VOCdevkit/VOC%s/JPEGImages/%s.jpg\n'%(wd, year, image_id))
convert_annotation(year, image_id)
list_file.close()
3.执行voc_label-auto.py
终端输入:
python voc_label-auto.py会得到2个东西,这两个东西后面要用到的
第一个,在 yolo3/darknet-master/scripts/VOCdevkit/VOC2007 目录下得到labels文件夹:
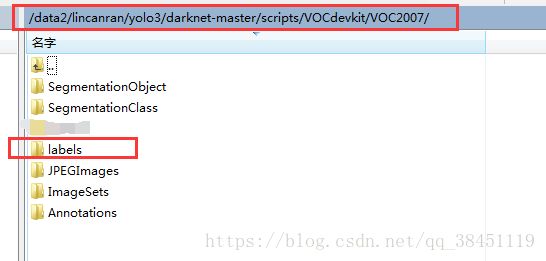
打开labels,里面就是训练集和验证集里的各个数据的的标签文件,这里是txt类型的,不再是之前的xml了:

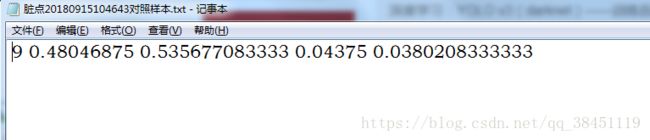
9代表的就是前面我们在classes列表里定义的第十个标签类—defect9(因为第一个是0)
后面的4个数字就是之前在xml文件里的ground truth框框的xmin xmax ymin ymax的坐标啦,这里自动将坐标除以图像的宽和高进行归一化了
第一个,在 yolo3/darknet-master/scripts 目录下,会得到 2007_train.txt 和 2007_test.txt 这两个文件:
里面是训练集和测试集图片的具体路径位置:
四、修改网络文件(cfg)
在 yolo3/darknet-master/cfg 目录下有很多版本的cfg网络文件
我们这里对yolov3-voc.cfg文件进行修改:
- 将行批次更改为batch=64
-
将行细分更改为subdivisions=8
- 将里面的每一个classes=20改为自己的类别数(不加上背景类,我这里classes=10),一共有3处需要修改

- 在每一个yolo层下均有一个filters=255,更改为filters =(classes + 5)x3,写实数,一共有3处需要修改。我这里filters =(10 + 5)x3=45

五、训练参数优化
在第二步里我在yolo v3的根目录下创建了一个 names-data 的文件夹,里面放了darknet53.conv.74预训练权重
这里我们需要新建几个东西:
1.创建voc.names文件
在 yolo3/darknet-master/names-data 目录下创建文件 voc.names ,将每一个类别单独一行写上去

2.创建voc.data文件
在 yolo3/darknet-master/names-data 目录下创建文件 voc.data
里面包含以下信息:
classes= 10(你的类的数目,不包含背景类)
train = /data2/lincanran/yolo3/darknet-master/scripts/2007_train.txt(第三步生成的文件之一,2007_train.txt的路径)
valid = /data2/lincanran/yolo3/darknet-master/scripts/2007_test.txt(第三步生成的文件之一,2007_test.txt的路径)
names = /data2/lincanran/yolo3/darknet-master/names-data/voc.names(上一小步自己创建的voc.names文件的路径)
backup = /data2/lincanran/yolo3/darknet-master/names-data/backup_big(自己新建一个backup_big文件,里面到时是放训练好的模型权重)

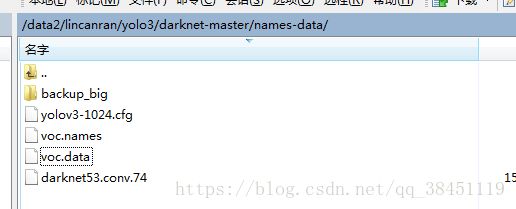
(我这里用的是1024的yolo v3,其实我这里的 yolov3-1024.cfg 就是你们刚刚第四步修改的 yolov3-voc.cfg文件)
3.开始训练
进入yolo v3的根目录下
终端输入:
./darknet detector train /data2/lincanran/yolo3/darknet-master/names-data/voc.data /data2/lincanran/yolo3/darknet-master/names-data/yolov3-obj.cfg /data2/lincanran/yolo3/darknet-master/names-data/darknet53.conv.74具体的路径改成你自己文件的路径啦!
4.断点重新训练
如果从某次断了重新开始训练,只需要把 darknet53.conv.74 换成你的某一次的weights即可
即把命令行中的参数 darknet53.conv.74 改成 yolov3-1024_2560.weights 即可
成功跑起来啦!!
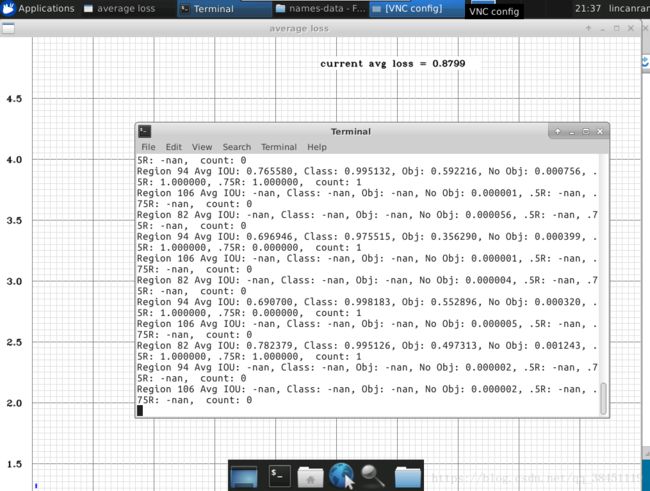
其他需要注意的:
若出现显存不足,可修改batch的大小和取消random多尺度,默认情况下random=1,取消将random=0,一共在3处地方。