2019.09.15】基于TensorFlow2.0,使用Keras + mnist(手写数字) 数据集进行深度学习实战,数据归一化与不归一化结果对比
基于TensorFlow2.0,使用Keras + mnist 数据集进行深度学习实战
import pandas as pd
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Flatten, Dense, Conv2D, MaxPooling2D, Dropout
from tensorflow.keras import datasets
%matplotlib inline
# 1、加载数据
(train_images,train_labels),(test_images,test_labels) = datasets.mnist.load_data()
print(train_images.shape)
print(train_labels.shape)
print(test_images.shape)
print(test_labels.shape)
(60000, 28, 28)
(60000,)
(10000, 28, 28)
(10000,)
plt.imshow(train_images[1009]),
train_labels[1009]
8
可以看到训练数据集由60000张28*28的图片组成,Label就是每个图像对应的手写字体的数字
(train_images,train_labels),(test_images,test_labels) = datasets.mnist.load_data()
# 2、构建模型(顺序)
model = Sequential([Flatten(input_shape=(28,28)), # (60000, 28. 28)-----》(60000, 28*28)
Dense(64, activation='relu'),
Dense(10, activation='softmax')])
# 3、编译模型
model.compile(loss='sparse_categorical_crossentropy',
optimizer='adam',
metrics=['acc'])
# 4、拟合模型
history = model.fit(train_images, train_labels,
epochs=50, batch_size=512,
validation_data=(test_images, test_labels))
Train on 60000 samples, validate on 10000 samples
Epoch 1/50
60000/60000 [==============================] - 1s 11us/sample - loss: 12.8318 - acc: 0.7595 - val_loss: 3.0141 - val_acc: 0.8560
Epoch 2/50
60000/60000 [==============================] - 1s 9us/sample - loss: 1.9891 - acc: 0.8371 - val_loss: 1.2640 - val_acc: 0.8252
Epoch 3/50
60000/60000 [==============================] - 1s 8us/sample - loss: 0.9736 - acc: 0.8264 - val_loss: 0.9058 - val_acc: 0.8334
Epoch 4/50
60000/60000 [==============================] - 1s 8us/sample - loss: 0.7063 - acc: 0.8540 - val_loss: 0.7601 - val_acc: 0.8576
Epoch 5/50
60000/60000 [==============================] - 1s 8us/sample - loss: 0.5713 - acc: 0.8728 - val_loss: 0.6955 - val_acc: 0.8706
Epoch 6/50
60000/60000 [==============================] - 0s 8us/sample - loss: 0.4809 - acc: 0.8869 - val_loss: 0.6461 - val_acc: 0.8801
Epoch 7/50
60000/60000 [==============================] - 0s 8us/sample - loss: 0.4170 - acc: 0.9004 - val_loss: 0.6040 - val_acc: 0.8920
Epoch 8/50
60000/60000 [==============================] - 1s 8us/sample - loss: 0.3727 - acc: 0.9104 - val_loss: 0.5777 - val_acc: 0.8954
Epoch 9/50
60000/60000 [==============================] - 1s 8us/sample - loss: 0.3327 - acc: 0.9165 - val_loss: 0.5469 - val_acc: 0.9010
Epoch 10/50
60000/60000 [==============================] - 1s 8us/sample - loss: 0.2992 - acc: 0.9240 - val_loss: 0.5124 - val_acc: 0.9074
Epoch 11/50
60000/60000 [==============================] - 0s 8us/sample - loss: 0.2726 - acc: 0.9290 - val_loss: 0.5123 - val_acc: 0.9093
Epoch 12/50
60000/60000 [==============================] - 1s 8us/sample - loss: 0.2519 - acc: 0.9325 - val_loss: 0.4877 - val_acc: 0.9111
Epoch 13/50
60000/60000 [==============================] - 0s 8us/sample - loss: 0.2308 - acc: 0.9369 - val_loss: 0.4719 - val_acc: 0.9158
Epoch 14/50
60000/60000 [==============================] - 1s 8us/sample - loss: 0.2192 - acc: 0.9388 - val_loss: 0.4744 - val_acc: 0.9161
Epoch 15/50
60000/60000 [==============================] - 0s 8us/sample - loss: 0.2034 - acc: 0.9435 - val_loss: 0.4513 - val_acc: 0.9173
Epoch 16/50
60000/60000 [==============================] - 0s 8us/sample - loss: 0.1920 - acc: 0.9457 - val_loss: 0.4389 - val_acc: 0.9219
Epoch 17/50
60000/60000 [==============================] - 1s 9us/sample - loss: 0.1829 - acc: 0.9478 - val_loss: 0.4270 - val_acc: 0.9193
Epoch 18/50
60000/60000 [==============================] - 1s 9us/sample - loss: 0.1739 - acc: 0.9496 - val_loss: 0.4385 - val_acc: 0.9241
Epoch 19/50
60000/60000 [==============================] - 1s 8us/sample - loss: 0.1632 - acc: 0.9525 - val_loss: 0.4111 - val_acc: 0.9294
Epoch 20/50
60000/60000 [==============================] - 1s 9us/sample - loss: 0.1543 - acc: 0.9547 - val_loss: 0.4115 - val_acc: 0.9278
Epoch 21/50
60000/60000 [==============================] - 1s 8us/sample - loss: 0.1484 - acc: 0.9559 - val_loss: 0.4159 - val_acc: 0.9269
Epoch 22/50
60000/60000 [==============================] - 1s 8us/sample - loss: 0.1463 - acc: 0.9566 - val_loss: 0.4046 - val_acc: 0.9287
Epoch 23/50
60000/60000 [==============================] - 1s 9us/sample - loss: 0.1372 - acc: 0.9586 - val_loss: 0.3985 - val_acc: 0.9327
Epoch 24/50
60000/60000 [==============================] - 1s 8us/sample - loss: 0.1321 - acc: 0.9601 - val_loss: 0.4131 - val_acc: 0.9304
Epoch 25/50
60000/60000 [==============================] - 1s 8us/sample - loss: 0.1234 - acc: 0.9622 - val_loss: 0.3863 - val_acc: 0.9330
Epoch 26/50
60000/60000 [==============================] - 1s 8us/sample - loss: 0.1195 - acc: 0.9631 - val_loss: 0.3987 - val_acc: 0.9348
Epoch 27/50
60000/60000 [==============================] - 1s 9us/sample - loss: 0.1148 - acc: 0.9650 - val_loss: 0.4004 - val_acc: 0.9365
Epoch 28/50
60000/60000 [==============================] - 1s 9us/sample - loss: 0.1159 - acc: 0.9643 - val_loss: 0.3818 - val_acc: 0.9371
Epoch 29/50
60000/60000 [==============================] - 1s 9us/sample - loss: 0.1149 - acc: 0.9644 - val_loss: 0.3950 - val_acc: 0.9376
Epoch 30/50
60000/60000 [==============================] - 1s 9us/sample - loss: 0.1090 - acc: 0.9666 - val_loss: 0.3915 - val_acc: 0.9393
Epoch 31/50
60000/60000 [==============================] - 1s 9us/sample - loss: 0.1102 - acc: 0.9662 - val_loss: 0.3970 - val_acc: 0.9374
Epoch 32/50
60000/60000 [==============================] - 1s 8us/sample - loss: 0.1022 - acc: 0.9679 - val_loss: 0.3845 - val_acc: 0.9425
Epoch 33/50
60000/60000 [==============================] - 1s 9us/sample - loss: 0.0977 - acc: 0.9691 - val_loss: 0.3771 - val_acc: 0.9397
Epoch 34/50
60000/60000 [==============================] - 1s 9us/sample - loss: 0.0996 - acc: 0.9681 - val_loss: 0.3786 - val_acc: 0.9407
Epoch 35/50
60000/60000 [==============================] - 1s 9us/sample - loss: 0.1004 - acc: 0.9683 - val_loss: 0.3778 - val_acc: 0.9384
Epoch 36/50
60000/60000 [==============================] - 1s 9us/sample - loss: 0.0987 - acc: 0.9695 - val_loss: 0.3819 - val_acc: 0.9417
Epoch 37/50
60000/60000 [==============================] - 1s 9us/sample - loss: 0.0971 - acc: 0.9691 - val_loss: 0.3689 - val_acc: 0.9421
Epoch 38/50
60000/60000 [==============================] - 1s 9us/sample - loss: 0.0890 - acc: 0.9714 - val_loss: 0.3723 - val_acc: 0.9415
Epoch 39/50
60000/60000 [==============================] - 1s 9us/sample - loss: 0.0880 - acc: 0.9731 - val_loss: 0.3725 - val_acc: 0.9411
Epoch 40/50
60000/60000 [==============================] - 1s 9us/sample - loss: 0.0852 - acc: 0.9729 - val_loss: 0.3966 - val_acc: 0.9406
Epoch 41/50
60000/60000 [==============================] - 1s 8us/sample - loss: 0.0862 - acc: 0.9726 - val_loss: 0.3680 - val_acc: 0.9433
Epoch 42/50
60000/60000 [==============================] - 1s 8us/sample - loss: 0.0880 - acc: 0.9732 - val_loss: 0.3706 - val_acc: 0.9428
Epoch 43/50
60000/60000 [==============================] - 1s 8us/sample - loss: 0.0884 - acc: 0.9723 - val_loss: 0.3719 - val_acc: 0.9439
Epoch 44/50
60000/60000 [==============================] - 1s 8us/sample - loss: 0.0884 - acc: 0.9725 - val_loss: 0.3815 - val_acc: 0.9434
Epoch 45/50
60000/60000 [==============================] - 1s 8us/sample - loss: 0.0837 - acc: 0.9736 - val_loss: 0.3519 - val_acc: 0.9459
Epoch 46/50
60000/60000 [==============================] - 1s 9us/sample - loss: 0.0853 - acc: 0.9739 - val_loss: 0.3639 - val_acc: 0.9450
Epoch 47/50
60000/60000 [==============================] - 1s 8us/sample - loss: 0.0776 - acc: 0.9755 - val_loss: 0.3533 - val_acc: 0.9458
Epoch 48/50
60000/60000 [==============================] - 1s 8us/sample - loss: 0.0721 - acc: 0.9769 - val_loss: 0.3485 - val_acc: 0.9467
Epoch 49/50
60000/60000 [==============================] - 1s 8us/sample - loss: 0.0787 - acc: 0.9756 - val_loss: 0.3649 - val_acc: 0.9479
Epoch 50/50
60000/60000 [==============================] - 1s 8us/sample - loss: 0.0778 - acc: 0.9765 - val_loss: 0.3624 - val_acc: 0.9468
# 5、评估模型
model.evaluate(test_images, test_labels)
10000/10000 [==============================] - 1s 52us/sample - loss: 0.3624 - acc: 0.9468
[0.36239219328409233, 0.9468]
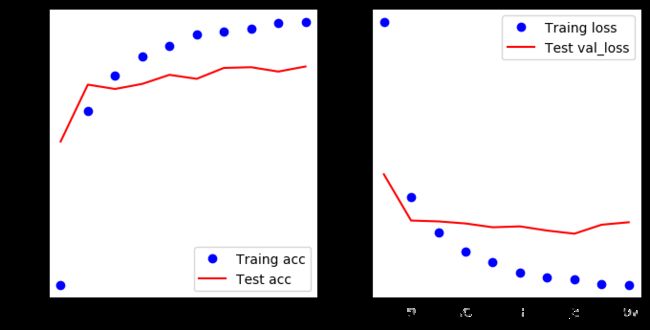
# 结果可视化
acc = history.history.get('acc')
val_acc = history.history.get('val_acc')
loss = history.history.get('loss')
val_loss = history.history.get('val_loss')
epochs = range(1, len(acc)+1)
plt.figure(figsize=(8,4),dpi=100)
plt.subplot(1, 2, 1)
plt.plot(epochs, acc, 'bo', label='Traing acc')
plt.plot(epochs, val_acc, 'r', label='Test acc')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(epochs, loss, 'bo', label='Traing loss')
plt.plot(epochs, val_loss, 'r', label='Test val_loss')
plt.legend()
测试准确率为 0.9468
增大网络容量,添加隐含层
(train_images,train_labels),(test_images,test_labels) = datasets.mnist.load_data()
# 2、构建模型(顺序)
model = Sequential([Flatten(input_shape=(28,28)), # (60000, 28. 28)-----》(60000, 28*28)
Dense(64, activation='relu'),
Dense(64, activation='relu'),
Dense(64, activation='relu'),
Dense(10, activation='softmax')])
# 3、编译模型
model.compile(loss='sparse_categorical_crossentropy',
optimizer='adam',
metrics=['acc'])
# 4、拟合模型
history = model.fit(train_images, train_labels,
epochs=50, batch_size=512,
validation_data=(test_images, test_labels))
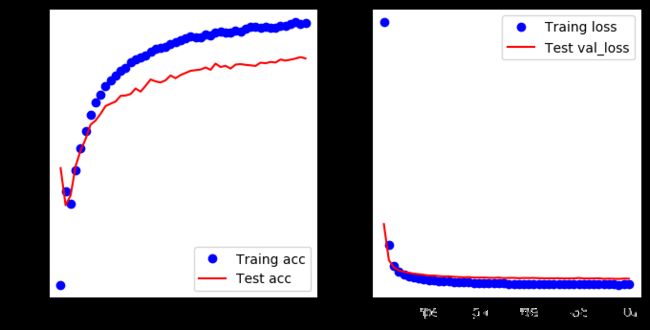
# 结果可视化
acc = history.history.get('acc')
val_acc = history.history.get('val_acc')
loss = history.history.get('loss')
val_loss = history.history.get('val_loss')
epochs = range(1, len(acc)+1)
plt.figure(figsize=(8,4),dpi=100)
plt.subplot(1, 2, 1)
plt.plot(epochs, acc, 'bo', label='Traing acc')
plt.plot(epochs, val_acc, 'r', label='Test acc')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(epochs, loss, 'bo', label='Traing loss')
plt.plot(epochs, val_loss, 'r', label='Test val_loss')
plt.legend()
Train on 60000 samples, validate on 10000 samples
Epoch 1/50
60000/60000 [==============================] - 1s 13us/sample - loss: 4.8376 - acc: 0.7013 - val_loss: 0.9137 - val_acc: 0.8342
Epoch 2/50
60000/60000 [==============================] - 1s 11us/sample - loss: 0.6739 - acc: 0.8600 - val_loss: 0.5719 - val_acc: 0.8735
Epoch 3/50
60000/60000 [==============================] - 1s 10us/sample - loss: 0.4421 - acc: 0.8936 - val_loss: 0.4463 - val_acc: 0.8954
Epoch 4/50
60000/60000 [==============================] - 1s 10us/sample - loss: 0.3424 - acc: 0.9126 - val_loss: 0.3728 - val_acc: 0.9125
Epoch 5/50
60000/60000 [==============================] - 1s 10us/sample - loss: 0.2755 - acc: 0.9263 - val_loss: 0.3248 - val_acc: 0.9195
Epoch 6/50
60000/60000 [==============================] - 1s 10us/sample - loss: 0.2321 - acc: 0.9356 - val_loss: 0.3045 - val_acc: 0.9226
Epoch 7/50
60000/60000 [==============================] - 1s 10us/sample - loss: 0.2043 - acc: 0.9421 - val_loss: 0.2869 - val_acc: 0.9265
Epoch 8/50
60000/60000 [==============================] - 1s 10us/sample - loss: 0.1824 - acc: 0.9476 - val_loss: 0.2783 - val_acc: 0.9297
Epoch 9/50
60000/60000 [==============================] - 1s 10us/sample - loss: 0.1636 - acc: 0.9525 - val_loss: 0.2641 - val_acc: 0.9351
Epoch 10/50
60000/60000 [==============================] - 1s 10us/sample - loss: 0.1486 - acc: 0.9558 - val_loss: 0.2649 - val_acc: 0.9328
Epoch 11/50
60000/60000 [==============================] - 1s 10us/sample - loss: 0.1401 - acc: 0.9578 - val_loss: 0.2570 - val_acc: 0.9372
Epoch 12/50
60000/60000 [==============================] - 1s 10us/sample - loss: 0.1275 - acc: 0.9622 - val_loss: 0.2429 - val_acc: 0.9396
Epoch 13/50
60000/60000 [==============================] - 1s 10us/sample - loss: 0.1212 - acc: 0.9638 - val_loss: 0.2492 - val_acc: 0.9401
Epoch 14/50
60000/60000 [==============================] - 1s 10us/sample - loss: 0.1134 - acc: 0.9658 - val_loss: 0.2414 - val_acc: 0.9428
Epoch 15/50
60000/60000 [==============================] - 1s 10us/sample - loss: 0.1035 - acc: 0.9679 - val_loss: 0.2363 - val_acc: 0.9447
Epoch 16/50
60000/60000 [==============================] - 1s 10us/sample - loss: 0.0968 - acc: 0.9702 - val_loss: 0.2293 - val_acc: 0.9472
Epoch 17/50
60000/60000 [==============================] - 1s 10us/sample - loss: 0.0907 - acc: 0.9724 - val_loss: 0.2332 - val_acc: 0.9476
Epoch 18/50
60000/60000 [==============================] - 1s 10us/sample - loss: 0.0881 - acc: 0.9725 - val_loss: 0.2350 - val_acc: 0.9468
Epoch 19/50
60000/60000 [==============================] - 1s 10us/sample - loss: 0.0812 - acc: 0.9740 - val_loss: 0.2354 - val_acc: 0.9461
Epoch 20/50
60000/60000 [==============================] - 1s 10us/sample - loss: 0.0784 - acc: 0.9758 - val_loss: 0.2341 - val_acc: 0.9471
Epoch 21/50
60000/60000 [==============================] - 1s 10us/sample - loss: 0.0711 - acc: 0.9777 - val_loss: 0.2248 - val_acc: 0.9489
Epoch 22/50
60000/60000 [==============================] - 1s 10us/sample - loss: 0.0634 - acc: 0.9797 - val_loss: 0.2339 - val_acc: 0.9511
Epoch 23/50
60000/60000 [==============================] - 1s 10us/sample - loss: 0.0631 - acc: 0.9804 - val_loss: 0.2341 - val_acc: 0.9487
Epoch 24/50
60000/60000 [==============================] - 1s 10us/sample - loss: 0.0642 - acc: 0.9793 - val_loss: 0.2302 - val_acc: 0.9516
Epoch 25/50
60000/60000 [==============================] - 1s 10us/sample - loss: 0.0579 - acc: 0.9813 - val_loss: 0.2313 - val_acc: 0.9528
Epoch 26/50
60000/60000 [==============================] - 1s 10us/sample - loss: 0.0584 - acc: 0.9807 - val_loss: 0.2342 - val_acc: 0.9513
Epoch 27/50
60000/60000 [==============================] - 1s 10us/sample - loss: 0.0565 - acc: 0.9813 - val_loss: 0.2348 - val_acc: 0.9490
Epoch 28/50
60000/60000 [==============================] - 1s 10us/sample - loss: 0.0578 - acc: 0.9807 - val_loss: 0.2454 - val_acc: 0.9529
Epoch 29/50
60000/60000 [==============================] - 1s 10us/sample - loss: 0.0517 - acc: 0.9822 - val_loss: 0.2413 - val_acc: 0.9511
Epoch 30/50
60000/60000 [==============================] - 1s 10us/sample - loss: 0.0500 - acc: 0.9830 - val_loss: 0.2522 - val_acc: 0.9506
Epoch 31/50
60000/60000 [==============================] - 1s 10us/sample - loss: 0.0551 - acc: 0.9824 - val_loss: 0.2253 - val_acc: 0.9555
Epoch 32/50
60000/60000 [==============================] - 1s 10us/sample - loss: 0.0414 - acc: 0.9864 - val_loss: 0.2535 - val_acc: 0.9532
Epoch 33/50
60000/60000 [==============================] - 1s 10us/sample - loss: 0.0426 - acc: 0.9858 - val_loss: 0.2353 - val_acc: 0.9539
Epoch 34/50
60000/60000 [==============================] - 1s 10us/sample - loss: 0.0392 - acc: 0.9870 - val_loss: 0.2474 - val_acc: 0.9516
Epoch 35/50
60000/60000 [==============================] - 1s 10us/sample - loss: 0.0417 - acc: 0.9861 - val_loss: 0.2578 - val_acc: 0.9546
Epoch 36/50
60000/60000 [==============================] - 1s 10us/sample - loss: 0.0360 - acc: 0.9879 - val_loss: 0.2543 - val_acc: 0.9532
Epoch 37/50
60000/60000 [==============================] - 1s 10us/sample - loss: 0.0389 - acc: 0.9869 - val_loss: 0.2431 - val_acc: 0.9578
Epoch 38/50
60000/60000 [==============================] - 1s 10us/sample - loss: 0.0471 - acc: 0.9842 - val_loss: 0.2825 - val_acc: 0.9533
Epoch 39/50
60000/60000 [==============================] - 1s 10us/sample - loss: 0.0535 - acc: 0.9834 - val_loss: 0.2601 - val_acc: 0.9545
Epoch 40/50
60000/60000 [==============================] - 1s 10us/sample - loss: 0.0438 - acc: 0.9851 - val_loss: 0.2737 - val_acc: 0.9545
Epoch 41/50
60000/60000 [==============================] - 1s 10us/sample - loss: 0.0431 - acc: 0.9857 - val_loss: 0.2576 - val_acc: 0.9553
Epoch 42/50
60000/60000 [==============================] - 1s 11us/sample - loss: 0.0365 - acc: 0.9875 - val_loss: 0.2803 - val_acc: 0.9543
Epoch 43/50
60000/60000 [==============================] - 1s 10us/sample - loss: 0.0368 - acc: 0.9882 - val_loss: 0.2766 - val_acc: 0.9553
Epoch 44/50
60000/60000 [==============================] - 1s 10us/sample - loss: 0.0526 - acc: 0.9838 - val_loss: 0.2644 - val_acc: 0.9582
Epoch 45/50
60000/60000 [==============================] - 1s 10us/sample - loss: 0.0351 - acc: 0.9886 - val_loss: 0.2738 - val_acc: 0.9558
Epoch 46/50
60000/60000 [==============================] - 1s 10us/sample - loss: 0.0321 - acc: 0.9893 - val_loss: 0.2816 - val_acc: 0.9571
Epoch 47/50
60000/60000 [==============================] - 1s 10us/sample - loss: 0.0304 - acc: 0.9900 - val_loss: 0.2606 - val_acc: 0.9603
Epoch 48/50
60000/60000 [==============================] - 1s 10us/sample - loss: 0.0286 - acc: 0.9906 - val_loss: 0.2603 - val_acc: 0.9602
Epoch 49/50
60000/60000 [==============================] - 1s 10us/sample - loss: 0.0236 - acc: 0.9918 - val_loss: 0.2772 - val_acc: 0.9595
Epoch 50/50
60000/60000 [==============================] - 1s 10us/sample - loss: 0.0271 - acc: 0.9909 - val_loss: 0.2683 - val_acc: 0.9610
测试准确率为 0.9610
#对数据进行编码后训练
(train_images,train_labels),(test_images,test_labels) = datasets.mnist.load_data()
# 训练图像保存在一个uint8 类型的数组中,其形状为(60000, 28, 28),取值区间为[0, 255]。我们需要将其变换为一个float32 数组,其形状为(60000, 28 * 28),取值范围为0~1。
train_images = train_images.reshape(60000, 28*28).astype('float32') / 255
test_images = test_images.reshape(10000, 28*28).astype('float32') / 255
# 对标签进行分类编码
train_labels = tf.keras.utils.to_categorical(train_labels)
test_labels = tf.keras.utils.to_categorical(test_labels)
# 2、构建模型()
model = Sequential([Dense(512, activation='relu', input_shape=(28*28,)),
Dense(64, activation='relu'),
Dense(10, activation='softmax')])
# 3、编译模型
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['acc'])
# 4、拟合模型
history = model.fit(train_images, train_labels,
epochs=50, batch_size=512,
validation_data=(test_images, test_labels))
Train on 60000 samples, validate on 10000 samples
Epoch 1/50
60000/60000 [==============================] - 1s 15us/sample - loss: 0.3874 - acc: 0.8941 - val_loss: 0.1747 - val_acc: 0.9483
Epoch 2/50
60000/60000 [==============================] - 1s 11us/sample - loss: 0.1482 - acc: 0.9561 - val_loss: 0.1190 - val_acc: 0.9656
Epoch 3/50
60000/60000 [==============================] - 1s 11us/sample - loss: 0.0980 - acc: 0.9714 - val_loss: 0.1008 - val_acc: 0.9671
Epoch 4/50
60000/60000 [==============================] - 1s 11us/sample - loss: 0.0736 - acc: 0.9777 - val_loss: 0.0878 - val_acc: 0.9725
Epoch 5/50
60000/60000 [==============================] - 1s 11us/sample - loss: 0.0549 - acc: 0.9841 - val_loss: 0.0724 - val_acc: 0.9778
Epoch 6/50
60000/60000 [==============================] - 1s 11us/sample - loss: 0.0408 - acc: 0.9886 - val_loss: 0.0810 - val_acc: 0.9753
Epoch 7/50
60000/60000 [==============================] - 1s 11us/sample - loss: 0.0324 - acc: 0.9909 - val_loss: 0.0646 - val_acc: 0.9799
Epoch 8/50
60000/60000 [==============================] - 1s 11us/sample - loss: 0.0261 - acc: 0.9927 - val_loss: 0.0705 - val_acc: 0.9780
Epoch 9/50
60000/60000 [==============================] - 1s 11us/sample - loss: 0.0212 - acc: 0.9946 - val_loss: 0.0610 - val_acc: 0.9812
Epoch 10/50
60000/60000 [==============================] - 1s 11us/sample - loss: 0.0161 - acc: 0.9962 - val_loss: 0.0635 - val_acc: 0.9816
Epoch 11/50
60000/60000 [==============================] - 1s 11us/sample - loss: 0.0107 - acc: 0.9981 - val_loss: 0.0654 - val_acc: 0.9804
Epoch 12/50
60000/60000 [==============================] - 1s 11us/sample - loss: 0.0094 - acc: 0.9984 - val_loss: 0.0646 - val_acc: 0.9820
Epoch 13/50
60000/60000 [==============================] - 1s 11us/sample - loss: 0.0079 - acc: 0.9985 - val_loss: 0.0643 - val_acc: 0.9824
Epoch 14/50
60000/60000 [==============================] - 1s 12us/sample - loss: 0.0049 - acc: 0.9995 - val_loss: 0.0682 - val_acc: 0.9815
Epoch 15/50
60000/60000 [==============================] - 1s 12us/sample - loss: 0.0045 - acc: 0.9993 - val_loss: 0.0691 - val_acc: 0.9817
Epoch 16/50
60000/60000 [==============================] - 1s 11us/sample - loss: 0.0038 - acc: 0.9996 - val_loss: 0.0681 - val_acc: 0.9830
Epoch 17/50
60000/60000 [==============================] - 1s 11us/sample - loss: 0.0029 - acc: 0.9998 - val_loss: 0.0647 - val_acc: 0.9825
Epoch 18/50
60000/60000 [==============================] - 1s 11us/sample - loss: 0.0017 - acc: 0.9999 - val_loss: 0.0668 - val_acc: 0.9828
Epoch 19/50
60000/60000 [==============================] - 1s 11us/sample - loss: 0.0013 - acc: 1.0000 - val_loss: 0.0672 - val_acc: 0.9827
Epoch 20/50
60000/60000 [==============================] - 1s 11us/sample - loss: 0.0011 - acc: 1.0000 - val_loss: 0.0655 - val_acc: 0.9837
Epoch 21/50
60000/60000 [==============================] - 1s 11us/sample - loss: 8.7679e-04 - acc: 1.0000 - val_loss: 0.0693 - val_acc: 0.9832
Epoch 22/50
60000/60000 [==============================] - 1s 11us/sample - loss: 7.6021e-04 - acc: 1.0000 - val_loss: 0.0679 - val_acc: 0.9839
Epoch 23/50
60000/60000 [==============================] - 1s 11us/sample - loss: 6.5421e-04 - acc: 1.0000 - val_loss: 0.0692 - val_acc: 0.9834
Epoch 24/50
60000/60000 [==============================] - 1s 11us/sample - loss: 5.7870e-04 - acc: 1.0000 - val_loss: 0.0712 - val_acc: 0.9832
Epoch 25/50
60000/60000 [==============================] - 1s 11us/sample - loss: 4.9977e-04 - acc: 1.0000 - val_loss: 0.0692 - val_acc: 0.9835
Epoch 26/50
60000/60000 [==============================] - 1s 11us/sample - loss: 4.4865e-04 - acc: 1.0000 - val_loss: 0.0719 - val_acc: 0.9830
Epoch 27/50
60000/60000 [==============================] - 1s 11us/sample - loss: 3.9904e-04 - acc: 1.0000 - val_loss: 0.0729 - val_acc: 0.9833
Epoch 28/50
60000/60000 [==============================] - 1s 11us/sample - loss: 3.6224e-04 - acc: 1.0000 - val_loss: 0.0726 - val_acc: 0.9832
Epoch 29/50
60000/60000 [==============================] - 1s 11us/sample - loss: 3.4489e-04 - acc: 1.0000 - val_loss: 0.0732 - val_acc: 0.9827
Epoch 30/50
60000/60000 [==============================] - 1s 11us/sample - loss: 2.9672e-04 - acc: 1.0000 - val_loss: 0.0731 - val_acc: 0.9829
Epoch 31/50
60000/60000 [==============================] - 1s 11us/sample - loss: 2.6151e-04 - acc: 1.0000 - val_loss: 0.0748 - val_acc: 0.9829
Epoch 32/50
60000/60000 [==============================] - 1s 11us/sample - loss: 2.3749e-04 - acc: 1.0000 - val_loss: 0.0746 - val_acc: 0.9830
Epoch 33/50
60000/60000 [==============================] - 1s 11us/sample - loss: 2.1668e-04 - acc: 1.0000 - val_loss: 0.0751 - val_acc: 0.9833
Epoch 34/50
60000/60000 [==============================] - 1s 11us/sample - loss: 1.9664e-04 - acc: 1.0000 - val_loss: 0.0762 - val_acc: 0.9835
Epoch 35/50
60000/60000 [==============================] - 1s 11us/sample - loss: 1.7997e-04 - acc: 1.0000 - val_loss: 0.0773 - val_acc: 0.9829
Epoch 36/50
60000/60000 [==============================] - 1s 11us/sample - loss: 1.6535e-04 - acc: 1.0000 - val_loss: 0.0772 - val_acc: 0.9829
Epoch 37/50
60000/60000 [==============================] - 1s 11us/sample - loss: 1.4918e-04 - acc: 1.0000 - val_loss: 0.0773 - val_acc: 0.9826
Epoch 38/50
60000/60000 [==============================] - 1s 11us/sample - loss: 1.3834e-04 - acc: 1.0000 - val_loss: 0.0788 - val_acc: 0.9826
Epoch 39/50
60000/60000 [==============================] - 1s 11us/sample - loss: 1.2273e-04 - acc: 1.0000 - val_loss: 0.0790 - val_acc: 0.9828
Epoch 40/50
60000/60000 [==============================] - 1s 11us/sample - loss: 1.1330e-04 - acc: 1.0000 - val_loss: 0.0794 - val_acc: 0.9830
Epoch 41/50
60000/60000 [==============================] - 1s 11us/sample - loss: 1.0385e-04 - acc: 1.0000 - val_loss: 0.0804 - val_acc: 0.9829
Epoch 42/50
60000/60000 [==============================] - 1s 11us/sample - loss: 9.3831e-05 - acc: 1.0000 - val_loss: 0.0803 - val_acc: 0.9825
Epoch 43/50
60000/60000 [==============================] - 1s 11us/sample - loss: 8.6219e-05 - acc: 1.0000 - val_loss: 0.0810 - val_acc: 0.9830
Epoch 44/50
60000/60000 [==============================] - 1s 11us/sample - loss: 7.9767e-05 - acc: 1.0000 - val_loss: 0.0813 - val_acc: 0.9833
Epoch 45/50
60000/60000 [==============================] - 1s 11us/sample - loss: 7.2581e-05 - acc: 1.0000 - val_loss: 0.0825 - val_acc: 0.9831
Epoch 46/50
60000/60000 [==============================] - 1s 11us/sample - loss: 6.8911e-05 - acc: 1.0000 - val_loss: 0.0829 - val_acc: 0.9828
Epoch 47/50
60000/60000 [==============================] - 1s 11us/sample - loss: 6.0209e-05 - acc: 1.0000 - val_loss: 0.0841 - val_acc: 0.9833
Epoch 48/50
60000/60000 [==============================] - 1s 11us/sample - loss: 5.6985e-05 - acc: 1.0000 - val_loss: 0.0848 - val_acc: 0.9826
Epoch 49/50
60000/60000 [==============================] - 1s 11us/sample - loss: 5.1581e-05 - acc: 1.0000 - val_loss: 0.0848 - val_acc: 0.9827
Epoch 50/50
60000/60000 [==============================] - 1s 11us/sample - loss: 4.8771e-05 - acc: 1.0000 - val_loss: 0.0851 - val_acc: 0.9824
# 5、评估模型
# model.predict(test_images)
# model.predict_class(test_images)
model.evaluate(test_images, test_labels)
10000/10000 [==============================] - 1s 56us/sample - loss: 0.0851 - acc: 0.9824
[0.08507671587202557, 0.9824]
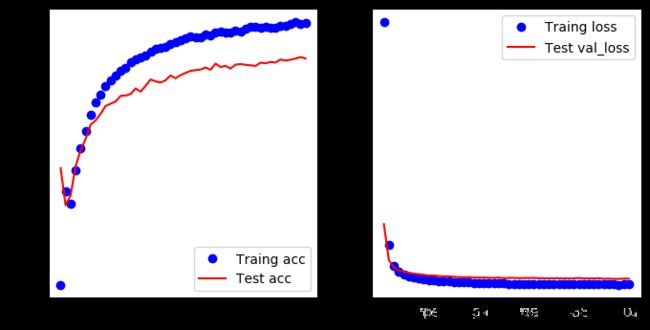
# 结果可视化
acc = history.history.get('acc')
val_acc = history.history.get('val_acc')
loss = history.history.get('loss')
val_loss = history.history.get('val_loss')
epochs = range(1, len(acc)+1)
plt.figure(figsize=(8,4),dpi=100)
plt.subplot(1, 2, 1)
plt.plot(epochs, acc, 'bo', label='Traing acc')
plt.plot(epochs, val_acc, 'r', label='Test acc')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(epochs, loss, 'bo', label='Traing loss')
plt.plot(epochs, val_loss, 'r', label='Test val_loss')
plt.legend()
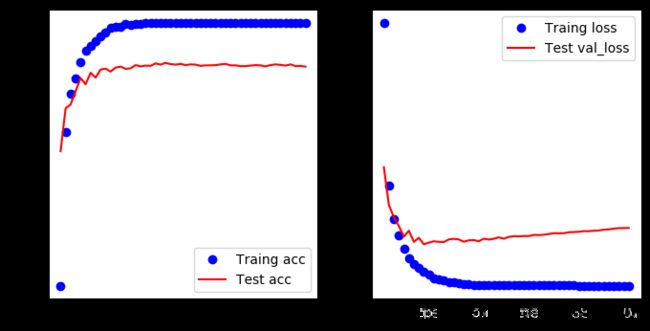
可以看出,准确率还是可以,不过测试数据比训练数据的结果还是要差一些,可能是因为有点过拟合了,我们只是一个3层的模型呀,增加一个Dropout层看看结果如何
# 2、构建模型
model = Sequential([Dense(512, activation='relu', input_shape=(28*28,)),
Dense(256, activation='relu'),
Dropout(0.5),
Dense(10, activation='softmax')])
# 3、编译模型
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['acc'])
# 4、拟合模型
history = model.fit(train_images, train_labels,
epochs=10, batch_size=128,
validation_data=(test_images, test_labels))
Train on 60000 samples, validate on 10000 samples
Epoch 1/10
60000/60000 [==============================] - 2s 36us/sample - loss: 0.2852 - acc: 0.9139 - val_loss: 0.1057 - val_acc: 0.9678
Epoch 2/10
60000/60000 [==============================] - 2s 29us/sample - loss: 0.1090 - acc: 0.9674 - val_loss: 0.0758 - val_acc: 0.9769
Epoch 3/10
60000/60000 [==============================] - 2s 28us/sample - loss: 0.0730 - acc: 0.9775 - val_loss: 0.0704 - val_acc: 0.9767
Epoch 4/10
60000/60000 [==============================] - 2s 29us/sample - loss: 0.0530 - acc: 0.9837 - val_loss: 0.0580 - val_acc: 0.9817
Epoch 5/10
60000/60000 [==============================] - 2s 29us/sample - loss: 0.0415 - acc: 0.9871 - val_loss: 0.0650 - val_acc: 0.9800
Epoch 6/10
60000/60000 [==============================] - 2s 29us/sample - loss: 0.0345 - acc: 0.9886 - val_loss: 0.0584 - val_acc: 0.9831
Epoch 7/10
60000/60000 [==============================] - 2s 30us/sample - loss: 0.0282 - acc: 0.9912 - val_loss: 0.0603 - val_acc: 0.9831
Epoch 8/10
60000/60000 [==============================] - 2s 30us/sample - loss: 0.0238 - acc: 0.9918 - val_loss: 0.0727 - val_acc: 0.9821
Epoch 9/10
60000/60000 [==============================] - 2s 30us/sample - loss: 0.0211 - acc: 0.9929 - val_loss: 0.0742 - val_acc: 0.9818
Epoch 10/10
60000/60000 [==============================] - 2s 31us/sample - loss: 0.0188 - acc: 0.9935 - val_loss: 0.0703 - val_acc: 0.9825
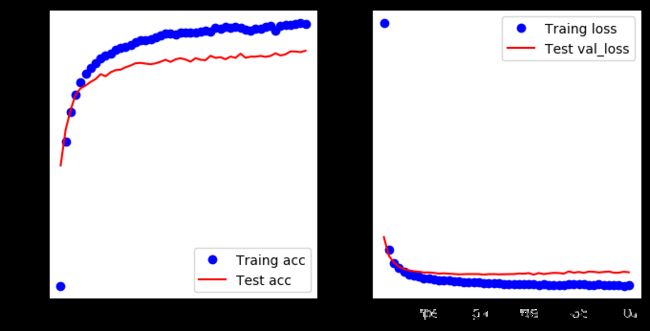
# 结果可视化
acc = history.history.get('acc')
val_acc = history.history.get('val_acc')
loss = history.history.get('loss')
val_loss = history.history.get('val_loss')
epochs = range(1, len(acc)+1)
plt.figure(figsize=(8,4),dpi=100)
plt.subplot(1, 2, 1)
plt.plot(epochs, acc, 'bo', label='Traing acc')
plt.plot(epochs, val_acc, 'r', label='Test acc')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(epochs, loss, 'bo', label='Traing loss')
plt.plot(epochs, val_loss, 'r', label='Test val_loss')
plt.legend()
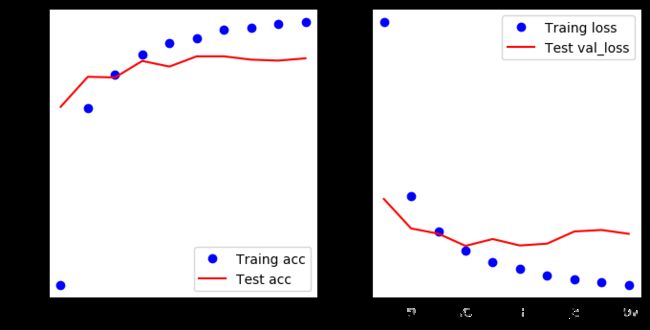
结果的趋势还没有很明显,增加epochs看看
history = model.fit(train_images, train_labels,
epochs=20, batch_size=128,
validation_data=(test_images, test_labels))
Train on 60000 samples, validate on 10000 samples
Epoch 1/20
60000/60000 [==============================] - 2s 31us/sample - loss: 0.0154 - acc: 0.9952 - val_loss: 0.0694 - val_acc: 0.9842
Epoch 2/20
60000/60000 [==============================] - 2s 29us/sample - loss: 0.0167 - acc: 0.9944 - val_loss: 0.0651 - val_acc: 0.9837
Epoch 3/20
60000/60000 [==============================] - 2s 29us/sample - loss: 0.0142 - acc: 0.9953 - val_loss: 0.0829 - val_acc: 0.9823
Epoch 4/20
60000/60000 [==============================] - 2s 30us/sample - loss: 0.0126 - acc: 0.9956 - val_loss: 0.0928 - val_acc: 0.9788
Epoch 5/20
60000/60000 [==============================] - 2s 29us/sample - loss: 0.0109 - acc: 0.9963 - val_loss: 0.0758 - val_acc: 0.9832
Epoch 6/20
60000/60000 [==============================] - 2s 28us/sample - loss: 0.0114 - acc: 0.9961 - val_loss: 0.0850 - val_acc: 0.9821
Epoch 7/20
60000/60000 [==============================] - 2s 29us/sample - loss: 0.0141 - acc: 0.9957 - val_loss: 0.0962 - val_acc: 0.9815
Epoch 8/20
60000/60000 [==============================] - 2s 31us/sample - loss: 0.0099 - acc: 0.9965 - val_loss: 0.0815 - val_acc: 0.9852
Epoch 9/20
60000/60000 [==============================] - 2s 29us/sample - loss: 0.0108 - acc: 0.9964 - val_loss: 0.0870 - val_acc: 0.9839
Epoch 10/20
60000/60000 [==============================] - 2s 30us/sample - loss: 0.0095 - acc: 0.9968 - val_loss: 0.0848 - val_acc: 0.9841
Epoch 11/20
60000/60000 [==============================] - 2s 29us/sample - loss: 0.0102 - acc: 0.9966 - val_loss: 0.0864 - val_acc: 0.9826
Epoch 12/20
60000/60000 [==============================] - 2s 29us/sample - loss: 0.0070 - acc: 0.9977 - val_loss: 0.0897 - val_acc: 0.9843
Epoch 13/20
60000/60000 [==============================] - 2s 30us/sample - loss: 0.0092 - acc: 0.9973 - val_loss: 0.0935 - val_acc: 0.9834
Epoch 14/20
60000/60000 [==============================] - 2s 29us/sample - loss: 0.0077 - acc: 0.9976 - val_loss: 0.0928 - val_acc: 0.9840
Epoch 15/20
60000/60000 [==============================] - 2s 29us/sample - loss: 0.0085 - acc: 0.9974 - val_loss: 0.0921 - val_acc: 0.9850
Epoch 16/20
60000/60000 [==============================] - 2s 30us/sample - loss: 0.0085 - acc: 0.9973 - val_loss: 0.1007 - val_acc: 0.9829
Epoch 17/20
60000/60000 [==============================] - 2s 29us/sample - loss: 0.0090 - acc: 0.9972 - val_loss: 0.1169 - val_acc: 0.9813
Epoch 18/20
60000/60000 [==============================] - 2s 29us/sample - loss: 0.0066 - acc: 0.9978 - val_loss: 0.0962 - val_acc: 0.9838
Epoch 19/20
60000/60000 [==============================] - 2s 29us/sample - loss: 0.0077 - acc: 0.9977 - val_loss: 0.1108 - val_acc: 0.9812
Epoch 20/20
60000/60000 [==============================] - 2s 29us/sample - loss: 0.0074 - acc: 0.9977 - val_loss: 0.1012 - val_acc: 0.9836
# 结果可视化
acc = history.history.get('acc')
val_acc = history.history.get('val_acc')
loss = history.history.get('loss')
val_loss = history.history.get('val_loss')
epochs = range(1, len(acc)+1)
plt.figure(figsize=(8,4),dpi=100)
plt.subplot(1, 2, 1)
plt.plot(epochs, acc, 'bo', label='Traing acc')
plt.plot(epochs, val_acc, 'r', label='Test acc')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(epochs, loss, 'bo', label='Traing loss')
plt.plot(epochs, val_loss, 'r', label='Test val_loss')
plt.legend()
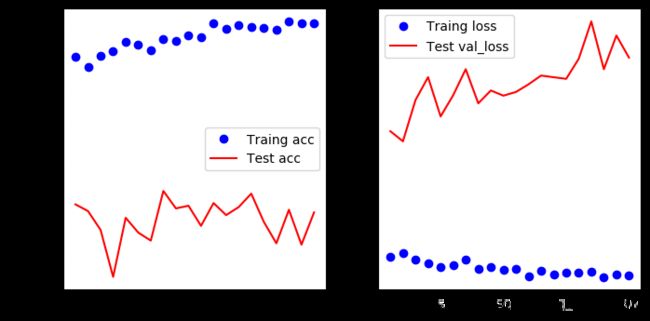
看样子又出现过拟合情况了,接下来大家可以调整各个超参数和网络层数,继续试试
# 全部代码
import pandas as pd
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Flatten, Dense, Conv2D, MaxPooling2D, Dropout
from tensorflow.keras import datasets
%matplotlib inline
# 1、加载数据
(train_images,train_labels),(test_images,test_labels) = datasets.mnist.load_data()
# 训练图像保存在一个uint8 类型的数组中,其形状为(60000, 28, 28),取值区间为[0, 255]。我们需要将其变换为一个float32 数组,其形状为(60000, 28 * 28),取值范围为0~1。
train_images = train_images.reshape(60000, 28*28).astype('float32') / 255
test_images = test_images.reshape(10000, 28*28).astype('float32') / 255
# 对标签进行分类编码
train_labels = tf.keras.utils.to_categorical(train_labels)
test_labels = tf.keras.utils.to_categorical(test_labels)
# 2、构建模型
model = Sequential([Dense(512, activation='relu', input_shape=(28*28,)),
Dense(256, activation='relu'),
Dropout(0.4),
Dense(10, activation='softmax')])
# 3、编译模型
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['acc'])
# 4、拟合模型
history = model.fit(train_images, train_labels,
epochs=10, batch_size=128,
validation_data=(test_images, test_labels))
# 5、评估模型
# model.predict(test_images)
# model.predict_class(test_images)
model.evaluate(test_images, test_labels)
# 结果可视化
acc = history.history.get('acc')
val_acc = history.history.get('val_acc')
loss = history.history.get('loss')
val_loss = history.history.get('val_loss')
epochs = range(1, len(acc)+1)
plt.figure(figsize=(8,4),dpi=100)
plt.subplot(1, 2, 1)
plt.plot(epochs, acc, 'bo', label='Traing acc')
plt.plot(epochs, val_acc, 'r', label='Test acc')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(epochs, loss, 'bo', label='Traing loss')
plt.plot(epochs, val_loss, 'r', label='Test val_loss')
plt.legend()
Train on 60000 samples, validate on 10000 samples
Epoch 1/10
60000/60000 [==============================] - 2s 33us/sample - loss: 0.2642 - acc: 0.9219 - val_loss: 0.1211 - val_acc: 0.9613
Epoch 2/10
60000/60000 [==============================] - 2s 29us/sample - loss: 0.1001 - acc: 0.9698 - val_loss: 0.0777 - val_acc: 0.9770
Epoch 3/10
60000/60000 [==============================] - 2s 29us/sample - loss: 0.0665 - acc: 0.9794 - val_loss: 0.0769 - val_acc: 0.9758
Epoch 4/10
60000/60000 [==============================] - 2s 29us/sample - loss: 0.0488 - acc: 0.9849 - val_loss: 0.0749 - val_acc: 0.9772
Epoch 5/10
60000/60000 [==============================] - 2s 31us/sample - loss: 0.0384 - acc: 0.9877 - val_loss: 0.0714 - val_acc: 0.9797
Epoch 6/10
60000/60000 [==============================] - 2s 32us/sample - loss: 0.0285 - acc: 0.9908 - val_loss: 0.0722 - val_acc: 0.9786
Epoch 7/10
60000/60000 [==============================] - 2s 29us/sample - loss: 0.0247 - acc: 0.9916 - val_loss: 0.0683 - val_acc: 0.9816
Epoch 8/10
60000/60000 [==============================] - 2s 29us/sample - loss: 0.0221 - acc: 0.9924 - val_loss: 0.0653 - val_acc: 0.9818
Epoch 9/10
60000/60000 [==============================] - 2s 27us/sample - loss: 0.0182 - acc: 0.9939 - val_loss: 0.0738 - val_acc: 0.9806
Epoch 10/10
60000/60000 [==============================] - 2s 31us/sample - loss: 0.0175 - acc: 0.9943 - val_loss: 0.0761 - val_acc: 0.9820
10000/10000 [==============================] - 1s 55us/sample - loss: 0.0761 - acc: 0.9820