Weka安装及简单应用
因为前段时间上课有接触WEKA这个软件 ,写了一个实验报告,特此把它贴出来,希望能对大家有所帮助~
一、Weka介绍
1、Weka简介
Weka是怀卡托智能分析环境(Waikato Environment for Knowledge Analysis)的英文字首缩写,在该网站可以免费下载可运行软件和源代码,还可以获得说明文档、常见问题解答、数据集和其他文献等资源。Weka是新西兰怀卡托大学用Java开发的数据挖掘著名开源软件,该系统自1993年开始由新西兰政府资助,至今已经历了20年的发展,其功能已经十分强大和成熟。
Weka作为一个公开的数据挖掘工作平台,集合了大量能承担数据挖掘任务的机器学习算法,包括对数据进行预处理,分类,回归、聚类、关联规则以及在新的交互式界面上的可视化。如果想自己实现数据挖掘算法的话,可以看一看WEKA的接口文档。在WEKA中集成自己的算法甚至借鉴它的方法自己实现可视化工具并不是件很困难的事情。
2、Weka的安装
WEKA的官方地址是http://www.cs.waikato.ac.nz/ml/weka/downloading.html。点开左侧download栏,可以进入下载页面,里面有windows, mas os, linux等平台下的版本。目前稳定的版本是3.8。
如果本机没有安装java,可以选择带有jre的版本。下载后是一个exe的可执行文件,双击进行安装即可。
安装步骤:







安装完毕,启动weka的快捷方式,就可以看到图1的界面。

图1 weka主界面
一般常用的有四个应用,分别是:
(1)Explorer
系统提供的最容易使用的图像用户接口。通过选择菜单和填写表单,可以调用weka的所有功能。这是用来进行数据实验、挖掘的环境,它提供了分类,聚类,关联规则,特征选择,数据可视化等等功能,如图2所示。
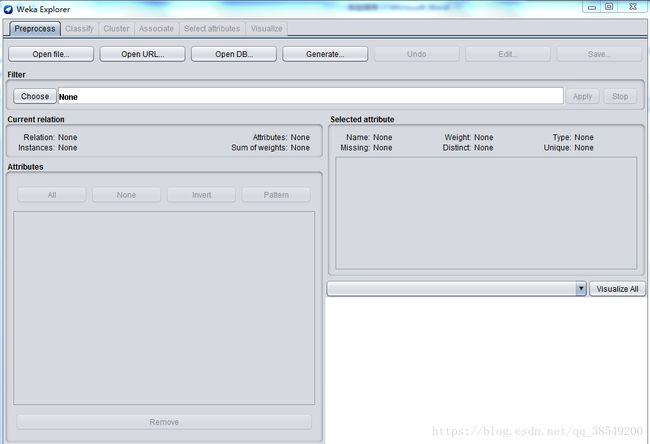
图 2 Explorer 界面
(2)Experimenter
用于帮助用户解答实际应用分类和回归技术中遇到的一个基本问题——对于一个已知问题,哪种方法及参数值能够取得最佳效果?通过Weka提供的实验者工作环境,用户可以比较不同的学习方案。尽管探索者界面也能通过交互完成这样的功能,但通过实验者界面,用户可以让处理过程实现自动化。实验者界面更加容易使用不同参数去设置分类器和过滤器,使之运行在一组数据集中,收集性能统计数据,实现重要的测试实验,界面如图3所示。
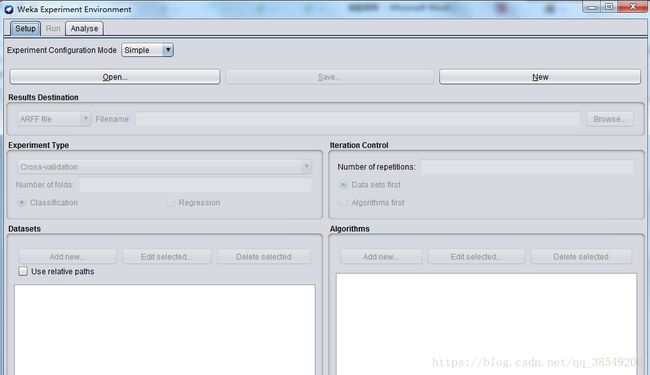
图3 Experimenter主界面
(3)KnowledgeFlow
可以使用增量方式的算法来处理大型数据集,用户可以定制处理数据流的方式和顺序。知识流界面允许用户在屏幕上任意拖曳代表学习算法和数据源的图形构件,并以一定的方式和顺序组合在一起。也就是,按照一定顺序将代表数据源、预处理工具、学习算法、评估手段和可视化模块的各构件组合在一起,形成数据流。如果用户选取的过滤器和学习算法具有增量学习功能,那就可以实现大型数据集的增量分批读取和处理,界面如图4所示。
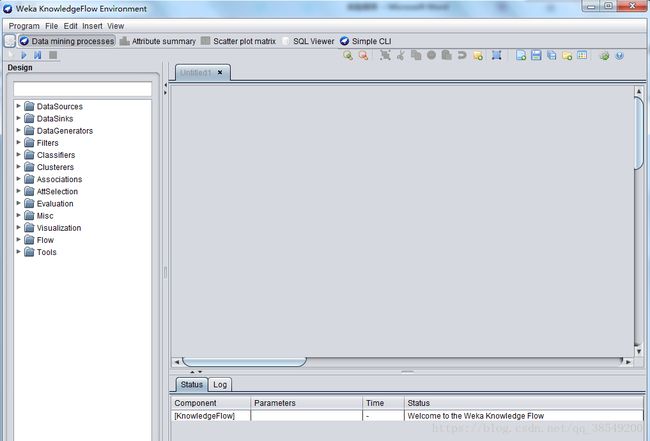
图4 KnowledgeFlow界面
(4)Simple CLI
是为不提供自己的命令行界面的操作系统提供的,该简单命令行界面用于和用户进行交互,可以直接执行Weka命令,如图5所示。

图5 Simple CLI界面
二、分类算法
1、数据说明
实验的数据来源于UCI数据集,网址如下:
http://archive.ics.uci.edu/ml/datasets/Bank+Marketing。这是葡萄牙一家银行机构的营销活动的数据。
该数据的数据属性如下:
- age (numeric),年龄;
- job (nominal),工作类型;
- marital (nominal),婚姻状态;
- education (nominal),教育程度;
- default (nominal),是否有信用违约记录;
- balance (numeric),年平均余额;
- housing (nominal),是否有房贷;
- loan (nominal),是否有个人贷款记录;
- contact (nominal),沟通类型;
- day (numeric),每月最后一个接触日;
- month (nominal),每年最后一个接触月;
- duration (numeric),最后一次接触时间;
- campaign (numeric),在此活动期间和此客户执行的联系人数量;
- pdays (numeric),上次与客户联系的日期是在上次活动之后;
- previous (numeric),在此活动之前和此客户端执行的联系人数量;
- poutcome (nominal),上次营销活动的结果;
- y(nominal)
2、数据预处理
(1)导入数据
Weka平台支持ARFF格式和CSV格式的数据。我在UCI上下载的是CSV格式的数据,但在导入的时候还是会报错。经过反复实验发现,我下载的CSV文件中的数据是由冒号将数据隔开的,把冒号换成逗号,就能成功导入了。
也可以利用WEKA将CSV格式转换成ARFF格式再导入,方法如下:
运行WEKA的主程序,出现GUI后可以点击下方按钮进入相应的模块。我们点击进入“Simple CLI”模块提供的命令行功能。由于weka暂不支持中文输入,所以挑选了在D盘下进行转换,在新窗口的最下方(上方是不能写字的)输入框写上java weka.core.converters.CSVLoader D:/bank-full.csv > D:/bank-full.arff,即可成功转换,生成文件“D:/bank-full.arff”如图6。

图6 数据转换过程图
还有一种方法,进入“Exploer”模块,从上方的按钮中打开CSV文件然后另存为ARFF文件亦可。实验所需的训练集为bank-full.arff,测试集为bank-test.arff。
(2)数据预处理
通常对于WEKA来说并不支持中文,所以我们将一些涉及中文的字段删除。WEKA支持的
而本表只有nemeric和nominal两种类型,数值属性(nemeric) 数值型属性可以是整数或者实数,但WEKA把它们都当作实数看待。分类属性(nominal) 分类属性由
实验数据集中所有的数据都是实验所需的,因此不存在属性筛选的问题。若所采用的数据集中存在大量的与实验无关的属性,则需要使用weka平台的Filter(过滤器)实现属性的筛选。Filter处可以通过Choose 选择某个筛选器Filter,以实现筛选数据或者对数据进行某种变换。数据预处理主要就是利用它来实现,如图7所 示。

图7 Filter(过滤器)
3、决策树算法
WEKA中的“Classify”选项卡中包含了分类(Classification)和回归(Regression),在这两个任务中,都有一个共同的目标属性(输出变量)。可以根据一个样本(WEKA中称作实例)的一组特征(输入变量),对目标进行预测。为了实现这一目的,我们需要有一个训练数据集,这个数据集中每个实例的输入和输出都是已知的。观察训练集中的实例,可以建立起预测的模型。有了这个模型,我们就可以新的输出未知的实例进行预测了。衡量模型的好坏就在于预测的准确程度。在WEKA中,待预测的目标(输出)被称作Class属性,这应该是来自分类任务的“类”。一般的,若Class属性是分类型时我们的任务才叫分类,Class属性是数值型时我们的任务叫回归。而我们使用决策树算法C4.5对Fund-data-normal建立起分类模型。因此我们制作分类不做回归。
用“Explorer”打开训练集“bank-full.arff”。切换到“Classify”选项卡,点击“Choose”按钮后可以看到很多分类或者回归的算法分门别类的列在一个树型框里。树型框下方有一个“Filter...”按钮,点击后勾选“Binary attributes”“Numeric attributes”和“Binary class”。点“OK”后回到树形图,可以发现一些算法名称变灰了,说明它们不能用。选择“trees”下的“J48”,这就是我们需要的C4.5算法。
点击“Choose”右边的文本框,弹出新窗口为该算法设置各种参数。我们把参数保持默认。
选上“Cross-validation”并在“Folds”框填上“10”。点“Start”按钮开始让算法生成决策树模型。很快,用文本表示的一棵决策树以及对这个决策树的误差分析结果出现在右边“Classifier output”中。见图8、图9,图10。
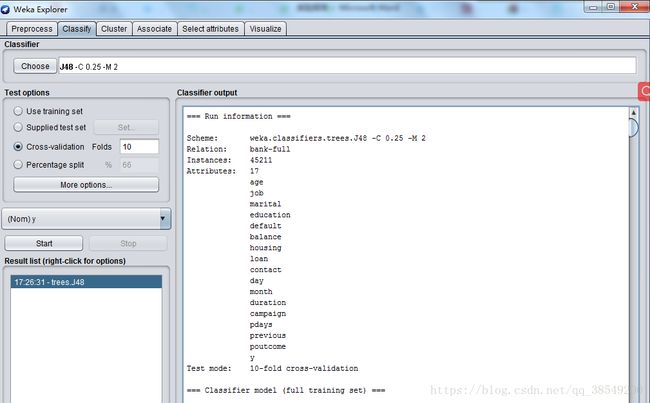
图8 决策树算法结果
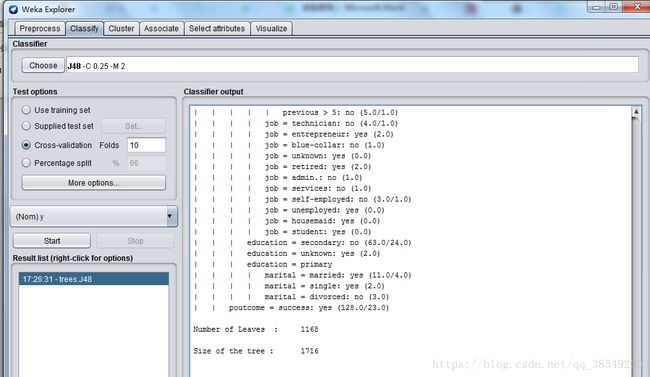
图9 决策树算法结果

图10 决策树算法结果
分析结果:
该结果的开头给出了数据集的概要,同时注明所用的评估方法是10折交叉验证。该方法是默认的。再往下是一棵剪枝过的决策树,这棵树是文本形式的。这里给出的模型通常是从Preprocess面板中的完整数据集上产生。第一层的分裂基于属性outlook进行
在这个树结构中,冒号后面的是分配到某叶子节点的类标,类标后面是到达该叶子结点的实力数量,该数量以十进制数表示。由图可知,由9.6879%的实例在交叉验证中被错误分类。从结尾处的混淆矩阵中可以看出,有1633属于no的实例被分为yes,同时有2747属于yes的实例被分为no类,总实例是45211。P=0.895,R=0.903,ROC面积为0.843
将模型运用在测试集:

图11 训练集结果
结果分析:
准确率为98.5075%,有2个实例被错误分类。P=0.985,R=0.985,ROC面积为0.981。
4、朴素贝叶斯分类器
到“Classify”选项卡,点击“Choose”按钮后可以看到很多分类或者回归的算法分门别类的列在一个树型框里。选择“bayes”下的“NaiveBayes”,这就是我们需要的朴素贝叶斯算法。
选上“Cross-validation”并在“Folds”框填上“10”。点“Start”按钮开始让算法生成贝叶斯分类器,结果如图12、图13。
图12 朴素贝叶斯
图13 朴素贝叶斯算法结果
结果分析:如图所示,这个输出与决策树算法输出显著不同就在于它输出的不是一颗文本形式的树,这里关于朴素贝叶斯模型的参数呈现在表中。第一列给出了属性,其他两列给出了类标值,表中每项可以死名目值得频度计数,也可以是数值型属性正态分布的参数。使用朴素贝叶斯分类器训练数据集,正确分类实例比例为88.0073%。根据混淆矩阵,有2924属于no的实例被分为yes,同时有2498属于yes的实例被分为no类。P=0.884,R=0.880,ROC面积为0.861
将模型应用于测试集:

图14 测试集结果
结果分析:
准确率为85.7143%,有18个实例被错误分类。P=0.852,R=0.857,ROC面积为0.829。
5、KNN算法
到“Classify”选项卡,点击“Choose”按钮后可以看到很多分类或者回归的算法分门别类的列在一个树型框里。选择“lazy”下的“IBk”,这就是我们需要的朴素贝叶斯算法。
选上“Cross-validation”并在“Folds”框填上“10”。点“Start”按钮开始让算法生成KNN分类器。K值设为10,如图15。

图15 K值设定位置
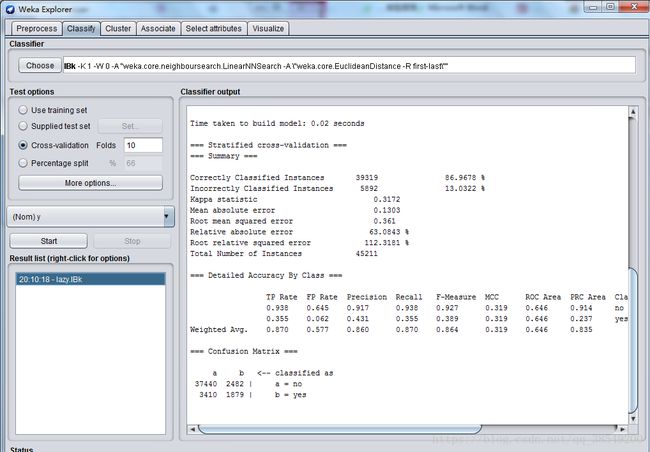
图16 KNN结果
使用KNN分类器训练数据集,正确分类实例比例为86.9678%。根据混淆矩阵,有2482属于no的实例被分为yes,同时有3410属于yes的实例被分为no类。P=0.860,R=0.870,ROC面积为0.646。

图17 KNN测试集上结果
结果分析:
准确率为94.7761%,有7个实例被错误分类。P=0.941,R=0.948,ROC面积为0.785。
三、聚类算法
weka提供采用k-means算法聚类的SimpleKMeans,簇的数目由参数指定,用户可以选择使用欧式距离或曼哈顿距离作为距离度量。这里使用weka data自带的iris数据建立起聚类模型。iris里包括四个属性变量(比如花的长度和宽度)和一个分类变量class(分成了3种,每种50个数据,一共150条数据),我们这里不需要分类结果,于是我们要在实验开始的时候将class给remove掉,自定义新的分类种数。
用“Explorer”打开软件自带的“iris.arff”,并切换到“Cluster”。点“Choose”按钮选择“SimpleKMeans”,这是WEKA中实现K均值的算法。点击旁边的文本框,修改“numClusters”为5,说明我们希望把这150条实例聚成5类,即K=5。下面的“seed”参数是要设置一个随机种子,依此产生一个随机数,用来得到K均值算法中第一次给出的K个簇中心的位置。我们不妨暂时让它就为10。
选中“Cluster Mode”的“Use training set”,点击“Start”按钮,观察右边“Clusterer output”给出的聚类结果。见下图18:

图18 聚类算法结果
分析结果:within cluster sum of squared errors:是评价聚类好坏的标准,数值越小说明同一簇实例之间的距离越小,此时的值为5.13.seed参数设置不同会导致该数值不同(因为初始点的选择对kmeans方法十分重要)cluster controids:其后列出了各个簇中心(最终趋向收敛不再迭代)的位置。对于数值型的属性,簇中心就是它的均值。clustered instances:是各个簇中实例的数目及百分比。
四、关联规则
使用weka安装目录data文件夹下的breast-cancer.arff数据数据作关联规则的分析。用“Explorer”打开“breast-cancer.arff”后,切换到“Associate”选项卡。默认关联规则分析是用Apriori算法,我们就用这个算法,但是点“Choose”右边的文本框修改默认的参数。
从网上获得的Apriori有关知识:对于一条关联规则L->R,我们常用支持度(Support)和置信度(Confidence)来衡量它的重要性。规则的支持度是用来估计在一个购物篮中同时观察到L和R的概率P(L,R),而规则的置信度是估计购物栏中出现了L时也出会现R的条件概率P(R|L)。关联规则的目标一般是产生支持度和置信度都较高的规则。

图19 Apriori算法结果
结果分析:规则采用“条件 num1=>结论 num2”的形式表示,num1表示满足条件的实例个数,num2表示满足整个规则(包括后面的结果,如X=>Y中的Y)的实例个数,num2/num1=conf,即该规则的置信度。距离,第一行的inv-nodes=0-2, irradiat都是X中的某项条件,这表示x1,x2,...,xn=>yi这条关联规则。因为在上面apriori中的参数选择里numRules默认写的是10,所以从上往下列出了10条挖掘出的最佳关联规则。可以改,比如改成12,(在满足置信条件的情况下)就会列出12条。
五、小结
通过本次数据挖掘实验,重新学习了一下数据挖掘的相关概念和知识,理解了数据挖掘的用途和使用步骤;进一步学习了WEKA开源数据挖掘工具在数据挖掘学习中的使用方法。并且对WEKA的分类与回归、聚类分析、关联规则几个模块化的基本分析方式进行了操作实验。在此过程中学会了运用各个模块的分析方法。由于是初次实验WEKA分析软件,对WEKA的运用和最终的数据结果运用还不熟悉,还需要在以后的学习中加以着重研究。