Spark+Hadoop集群搭建:(二)集群节点上搭建Hadoop环境
Spark+Hadoop集群搭建:(二)集群节点上搭建Hadoop环境
- 1 集群规划
- 1.1 节点规划
- 2 构建data1
- 2.1 复制生成data1
- 2.2 设置网卡
- 2.3 配置data1服务器
- 2.3.1 编辑hostname主机名
- 2.3.2 配置core-site.xml
- 2.3.3 配置YARN-site.xml
- 2.3.4 配置mapred-site.xml
- 2.3.5 配置hdfs-site.xml
- 2.4 通过data1复制产生data2、data3、master
- 2.5 配置data2服务器
- 2.5.1 设置主机名
- 2.6 配置data3服务器
- 2.6.1 设置主机名
- 2.7 配置master服务器
- 2.7.1 设置主机名
- 2.7.2 设置hdfs-site.xml
- 2.7.3 设置masters文件
- 2.7.4 设置slaves文件
- 3 配置host文件
- 3.1 查看各个节点的IP
- 3.2 设置hosts文件
- 4 创建HDFS目录
- 4.1 为data1创建HDFS目录
- 4.2 为data2创建HDFS目录
- 4.3 为data3创建HDFS目录
- 4.4 为master创建HDFS目录
- 5 设置SSH无密码登录
- 5.1 安装SSH与rsync
- 5.2 修改ssh配置文件
- 5.3 产生SSH Key
- 5.4 测试
- 5.5 data2、data3
- 5.6 master本身
- 5.7 从其他节点免密登录
- 6 启动集群
1 集群规划
1.1 节点规划
集群由4台服务器组成。其中1台为master,作为HDFS的NameNode、MapReduce的ResourceManager。其余三台为data,作为HDFS的DataNode、MapReduce的NodeManager。规划图如下。
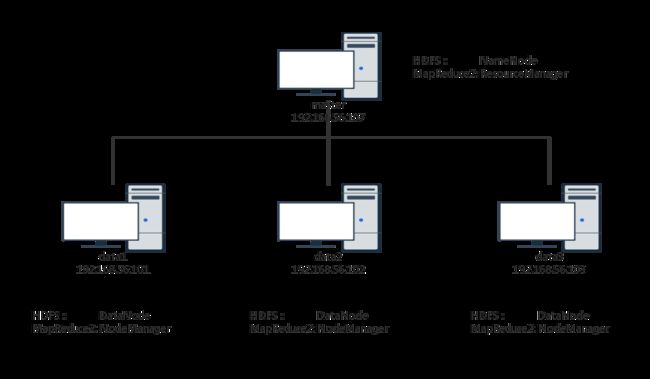
注意,这里4台服务器全部是虚拟机。
2 构建data1
2.1 复制生成data1
这里,我们将直接由之前构建的单节点虚拟机复制过来,加以修改。将Hadoop复制到data1(注意需要Hadoop处于关闭状态)。右击Hadoop,点击复制
设置名称为data1,MAC地址设定:为所有网卡重新生成MAC地址,点击下一步

选择完全复制
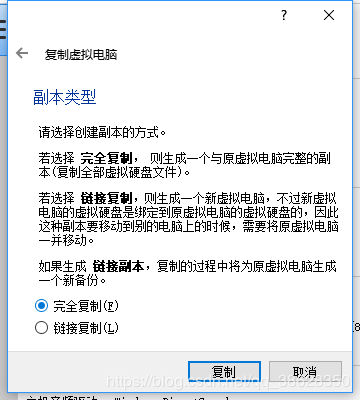
复制完成后,得到一个新的虚拟机data1
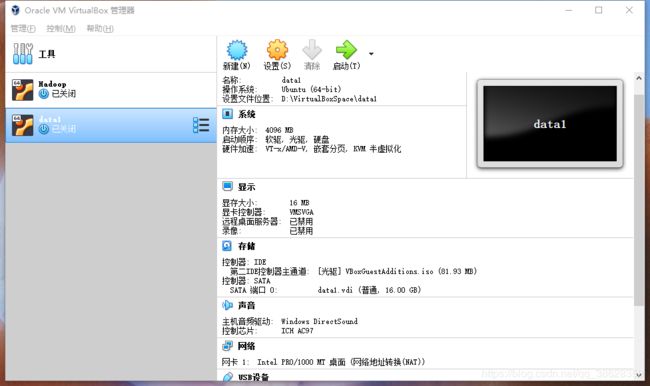
2.2 设置网卡
选中data1,点击设置,选择”网络“。设置网卡1为”NAT“网卡,点击确定,用于通过Host主机与外部连通
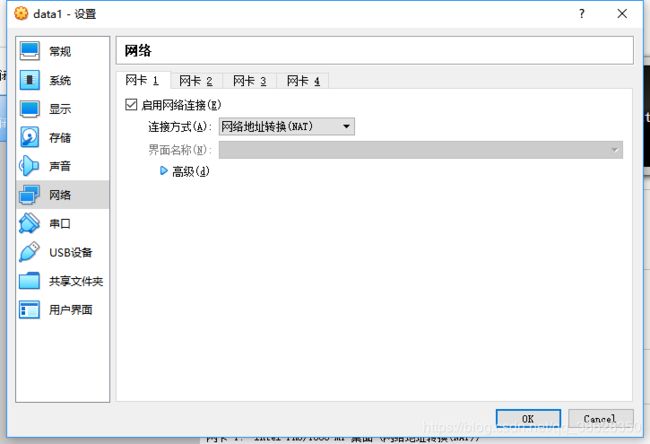
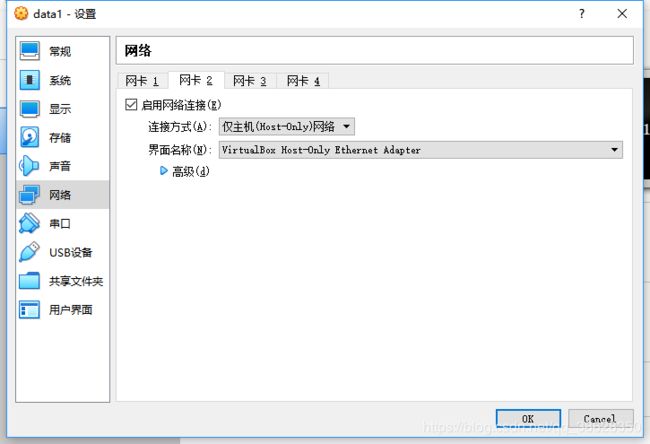
设置网卡2为”仅主机适配器“
2.3 配置data1服务器
启动data1,进行配置
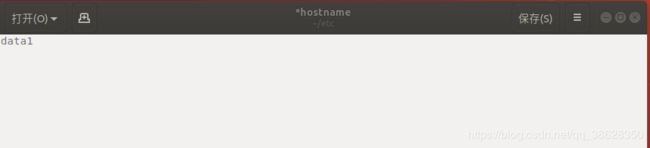
2.3.1 编辑hostname主机名
sudo gedit /etc/hostname 打开文件,改为data1
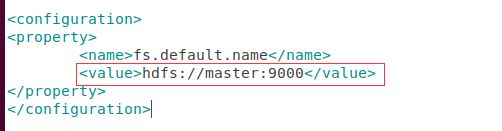
2.3.2 配置core-site.xml
sudo gedit /usr/local/hadoop/etc/hadoop/core-site.xml
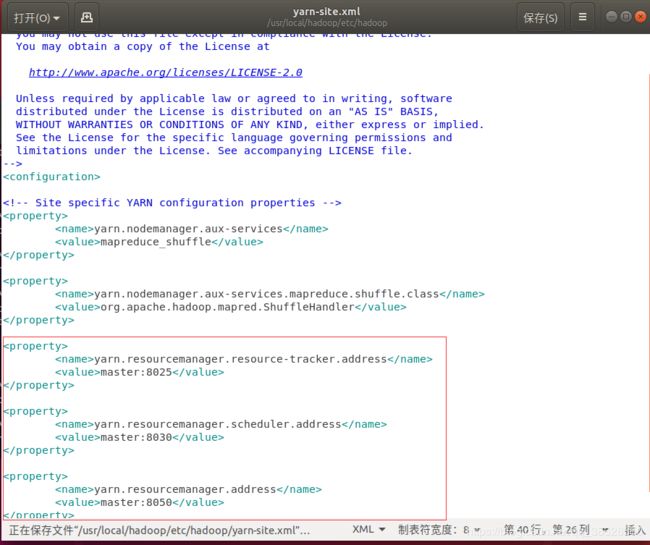
2.3.3 配置YARN-site.xml
sudo gedit /usr/local/hadoop/etc/hadoop/yarn-site.xml
在其中新增如下内容
ResourceManager主机与NodeManager的连接地址:8025
ResourceManager主机与ApplicationMaster的连接地址:8030
ResourceManager主机与客户端的连接地址:8050
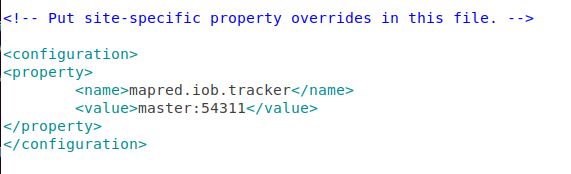
2.3.4 配置mapred-site.xml
sudo gedit /usr/local/hadoop/etc/hadoop/mapred-site.xml
修改设置如下图所示:
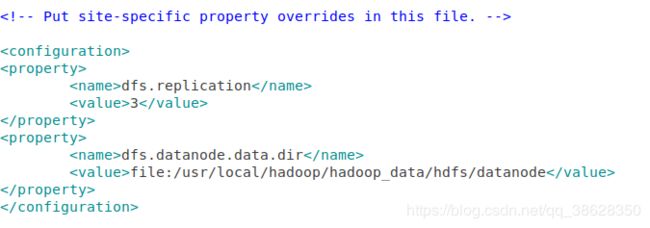
2.3.5 配置hdfs-site.xml
sudo gedit /usr/local/hadoop/etc/hadoop/hdfs-site.xml
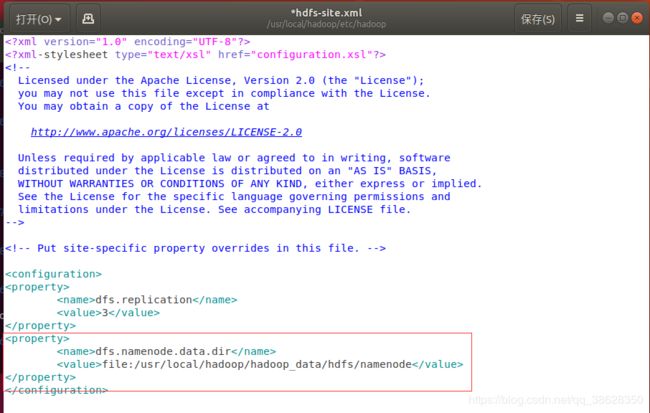
data1是datanode,修改配置如下.然后重新启动。
2.4 通过data1复制产生data2、data3、master
将data1关机,在virtualbox中复制。复制方式和复制生成data1的一样,只是虚拟机名称有所改变。复制后如下:

由于使用的时候,4台服务器需要同时启动,因此,要根据自己的实体主机内存来调整虚拟机的内存设置。
这里使用的实体主机内存为16G,因此master内存设为了4G,其他的data各自设置为2G.
选择data1,点击”设置“-”系统“,调整内存大小为2G。
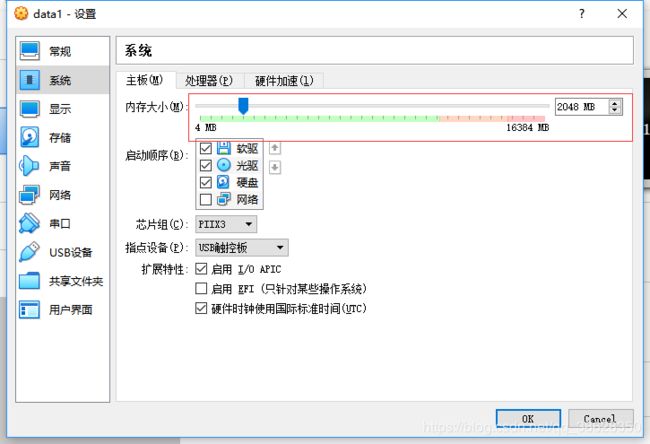
以相同的方式调整其他虚拟机的内存大小即可
2.5 配置data2服务器
启动data2虚拟机,进行配置
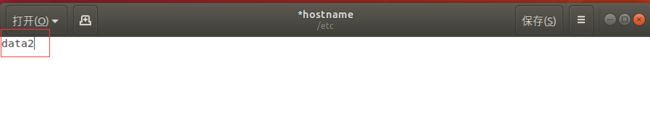
2.5.1 设置主机名
sudo gedit /etc/hostname 然后重新启动
2.6 配置data3服务器
启动data3虚拟机,进行配置
2.6.1 设置主机名
sudo gedit /etc/hostname 然后重新启动

2.7 配置master服务器
启动master虚拟机,进行配置
ext_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzM4NjI4MzUw,size_16,color_FFFFFF,t_70)
2.7.1 设置主机名
sudo gedit /etc/hostname

2.7.2 设置hdfs-site.xml
sudo gedit /usr/local/hadoop/etc/hadoop/hdfs-site.xml
2.7.3 设置masters文件
sudo gedit /usr/local/hadoop/etc/hadoop/masters

2.7.4 设置slaves文件
sudo gedit /usr/local/hadoop/etc/hadoop/slaves

3 配置host文件
3.1 查看各个节点的IP
以master为例,输入命令:ifconfig,获得其IP为:192.168.56.107
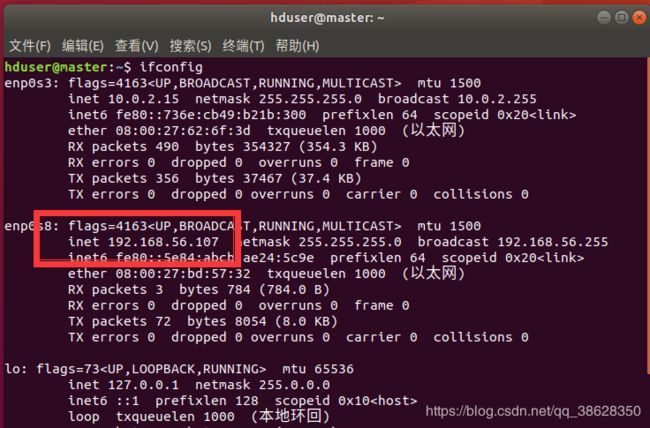
以相同的方式获得data1、data2、data3的IP地址
3.2 设置hosts文件
在master中输入命令:sudo gedit /etc/hosts
根据之前查询到的IP地址,设置hosts文件如下图所示。重新启动。

以相同的方式在data1、data2、data3中配置hosts文件
4 创建HDFS目录
首先启动4个虚拟机。然后通过master连接其他data节点,创建HDFS目录
进入master虚拟机
4.1 为data1创建HDFS目录
输入命令:ssh data1
连接data1,中途需要输入data1的密码
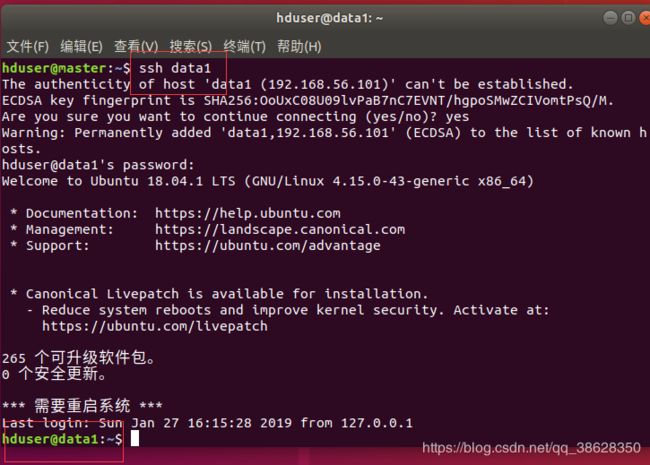
删除HDFS所有目录:sudo rm -rf /usr/local/hadoop/hadoop_data/hdfs
创建DataNode存储目录:mkdir -p /usr/local/hadoop/hadoop_data/hdfs/datanode
将目录的所有者更改为hduser:sudo chown -R hduser:hduser /usr/local/hadoop
中断连接,返回master:exit
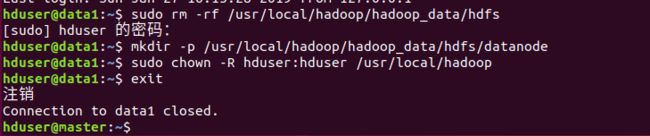
然后以相同的方式处理data2、data3
4.2 为data2创建HDFS目录
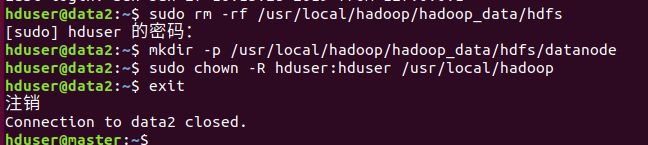
4.3 为data3创建HDFS目录

4.4 为master创建HDFS目录
删除之前的HDFS目录:sudo rm -rf /usr/local/hadoop/hadoop_data/hdfs
创建NameNode目录:mkdir -p /usr/local/hadoop/hadoop_data/hdfs/namenode
将目录的所有者更改为hduser:sudo chown -R hduser:hduser /usr/local/hadoop
格式化NameNode HDFS目录:hadoop namenode -format
5 设置SSH无密码登录
启动Hadoop时候,NameNode需要与DataNode建立连接并管理这些节点,此时系统会要求用户输入密码。为了避免手动输入密码,我们需要将SSH设置为无密码登录。这里,利用SSH Key进行身份验证。
我们以master与data1的连接为例,进行说明。
5.1 安装SSH与rsync
sudo apt-get install ssh
sudo apt-get install rsync
5.2 修改ssh配置文件
sudo gedit /etc/ssh/sshd_config
配置如下
PubkeyAuthentication yes # 启用公钥私钥配对认证方式
RSAAuthentication yes # 启用RSA认证
AuthorizedKeysFile %h/.ssh/authorized_keys # 公钥文件路径
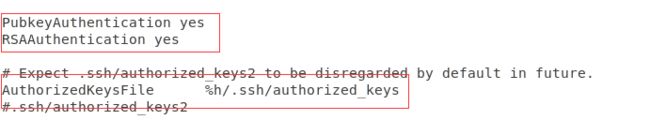
保存后,重启SSH服务
sudo service sshd restart
5.3 产生SSH Key
在master中输入:ssh-keygen -t rsa -f ~/.ssh/id_rsa -P ‘’
生成了一对密钥,公钥:id_rsa.pub 私钥:id_rsa
将生成的公钥id_rsa.pub拷贝到data1
命令:ssh-copy-id -i .ssh/id_rsa.pub data1
5.4 测试
命令:ssh data1
可以直接登陆,无需密码了
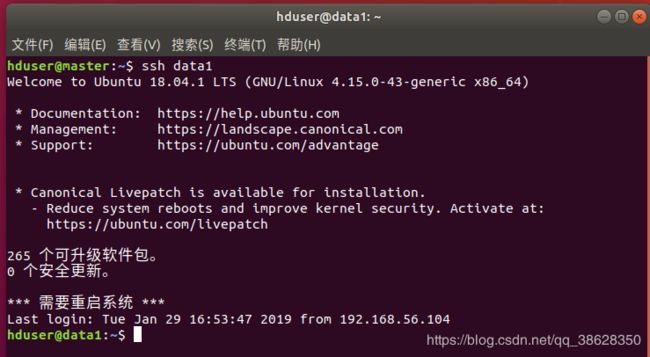
5.5 data2、data3
ssh-copy-id -i .ssh/id_rsa.pub data2
ssh-copy-id -i .ssh/id_rsa.pub data3
5.6 master本身
修改配置文件
sudo gedit /etc/ssh/sshd_config
设置:PermitRootLogin prohibit-password
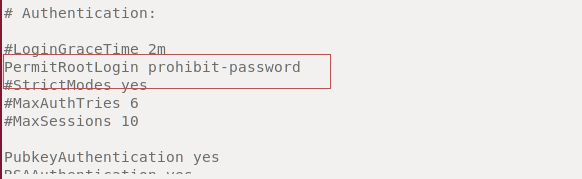
保存并重新启动SSH服务,命令:service sshd restart
为了master自己连接自己无需密码,也要把公钥添加给自己,命令:
ssh-copy-id -i .ssh/id_rsa.pub localhost
5.7 从其他节点免密登录
设置data1免密登录其他所有节点,可以参照上述方式对data1进行设置。data2、data3同理。
6 启动集群
首先启动全部虚拟机。
在master输入命令:start-all.sh
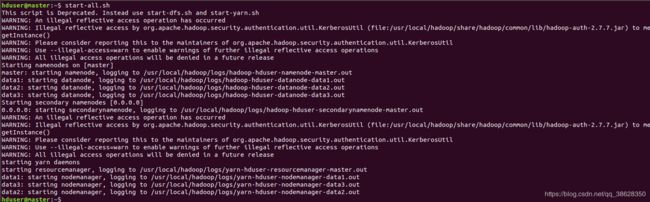
输入jps命令,可以看到进程已开启。
NameNode、SecondaryNameNode、ResourceManager三个进程都已经启动
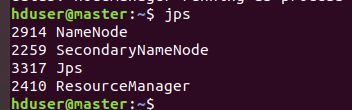
如果发现NameNode进程未开启,可以重新格式化一下NameNode,然后重启。
格式化命令:hadoop namenode -format
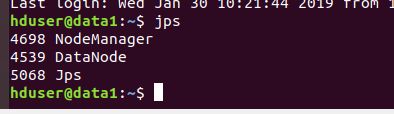
还可以通过ssh连接到data1,输入jps查看data1的进程
输入命令:ssh data1

输入命令:jps
可以看到NodeManager和DataNode进程都已启动