Sarsa Algorithm and Q_Learning Algorithm-- Reinforcement Learning
Author: LiChong0309
Label: Deep learning、Artificial Intelligence、Reinforcement learning
- 1. Introduction of Sarsa
- 1.1 Reinforcement Learning
- 1.1.1 General of Reinforcement Learning
- 1.1.2 Four elements of Reinforcement Learning
- 1.1.3 Process of Reinforcement Learning
- 1.2 Q_learning
- 1.2.1 Q_learning决策
- 1.2.2 Q_Learning 更新
- 1.2.3 Q_learning整体算法
- 1.3 Sarsa Algorithm
- 1.3.1 Sarsa Algorithm决策
- 1.3.2 Sarsa 更新
- 1.3.3 Sarsa 整体算法
- 1.1 Reinforcement Learning
- 2.References
1. Introduction of Sarsa
了解Sarsa算法,要先了解强化学习、Q_learing。
Reinforcement learning —> Q_learning —> Sarsa algorithm
1.1 Reinforcement Learning
https://www.jianshu.com/p/f8b71a5e6b4d
1.1.1 General of Reinforcement Learning
强化学习是一类算法,是让计算机实现从一开始完全随机的进行操作,通过不断地尝试,从错误中学习,最后找到规律,学会了达到目的的方法。这就是一个完整的强化学习过程。让计算机在不断的尝试中更新自己的行为,从而一步步学习如何操自己的行为得到高分。
①:强化学习是一类算法
②:开始—>随机 —–>(在错误中学习)—> 更新自己的行为—->找到规律 —–>学会方法
1.1.2 Four elements of Reinforcement Learning
Agent —->智能体 、计算机
Environment —-> 环境
Action —–>行动
Reward —->奖励
学习的目标是获得更多的累积奖励。
Agent:
1.做出行动 At A t
2. 观察环境(状态) Ot O t
3. 计算收益 R ewardt e w a r d t
Environment:
- 感知Agent做出的行动 At A t
- 做出环境(状态)反应 Ot+1 O t + 1
- 反馈收益 Rewardt+1 R e w a r d t + 1
1.1.3 Process of Reinforcement Learning
Reinfrocement Learning 的整体过程如下图流程图所示.
计算机就是 Agent,他试图通过采取行动来操纵环境,并且从一个状态转变到另一个状态,当他完成任务时给高分(奖励),但是当他没完成任务时,给低分(无奖励)。
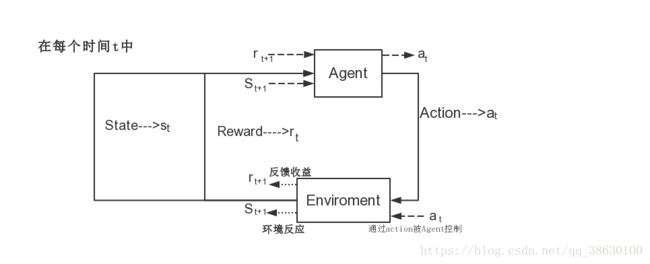
也可以将Agent看作是大脑,Environment看作是地球。

在计算机中有一个虚拟的裁判,这个裁判不会告诉Agent该怎么做,他只会记录每次Agent的行为,并未起打分。最开始的时候,Agent完全不知道该怎么做,所以Agent的行为是随机的。之后Agent记住高分和低分对应的行为,下次用同样的行为得到高分,避免低分。
1.2 Q_learning
Q_learning是强化学习中的一个决策算法
Q_learing 是使用Q表的形式决策的
Q表中的值是随机设置的,称为估计值
Q_learing的目的是为了更新Q表,使之成为更准确的Q表。
1.2.1 Q_learning决策
我们选取Agent处在 s1 s 1 状态的时候,此时Agent要向 s2 s 2 和 s3 s 3 状态转换。
s 和a的潜在奖励我们用如下的Q表格表示。

决策:当Agent处在 s1 s 1 状态的时候,有两个action可供选择, a1 a 1 和 a2 a 2 ,从上面的Q表可以看出,选择 a2 a 2 的潜在奖励要比 a1 a 1 高,Q( s1 s 1 , a1 a 1 )= -2,Q( s1 s 1 , a2 a 2 ) = 1。所以我们判断选择 a2 a 2 作为下一步行为。
当Agent选择了 a2 a 2 之后,就进入状态 s2 s 2 ,然后从Q表格中得到Q( s2 s 2 , a1 a 1 ),和Q( s2 s 2 , a2 a 2 )的值,比较他们的大小,选择下一步的行为。然后进入状态 s3 s 3 ,重复之前的操作。
1.2.2 Q_Learning 更新
当Agent在 s1 s 1 的状态选择 a2 a 2 之后,Q_learning算法会进行Q表的更新,更新原Q表中maxQ( s1 s 1 )的值。在未修改之前,Q表中的值都是估计量。
设置两个值:
gamma(γ)—–>衰减值(这里的衰减值和超市打γ折意思差不多)
alpha(α) ——> 学习效率(学习的内容为现实值 - 估计值)
更新方式:

根据1.2.1中的Q表,得知maxQ( s1 s 1 ) = Q( s1 s 1 , a2 a 2 ),所以在这一步中修改的为Q( s1 s 1 , a2 a 2 )的估计值。
①:Q( s1 s 1 , a2 a 2 )的估计值:Q( s1 s 1 , a2 a 2 )
②:Q( s1 s 1 , a2 a 2 )的现实值:maxQ( s2 s 2 ) * γ + R
③:计算估计值与现实值之间的差距:差距 = 现实值 - 估计值
④:得到新的Q( s1 s 1 , a2 a 2 ):新Q( s1 s 1 , a2 a 2 ) = 老Q( s1 s 1 , a2 a 2 ) + α * 差距
整理得到:
==》Q( s1 s 1 , a2 a 2 ) <— (1-α) Q( s1 s 1 , a2 a 2 ) + α(γ * maxQ( s2 s 2 ) + R)
①:这个公式可以看做一个加权平均的公式,学习效率(α)表示了新学到的现实值在修改后的Q表中占得比重。
②:根据公式可以看出,学习速率α越大,保留之前训练的效果就越少,衰减值γ越大,所起到的作用就越大。这个过程可以看做是“(1 - γ)为遗忘过去的能力,α为记住现在的能力”的过程。
③:做一个形象比喻:假如有一只小鸟,小鸟在对状态进行更新时,会考虑到眼前利益(R),和记忆中的利益(Q( s1 s 1 , a2 a 2 ))。如果小鸟之前在下一个状态的某个动作上吃过甜头(选择了某个动作之后获得了50的奖赏),那么它就更希望提早地得知这个消息,以便下回在状态可以通过选择正确的动作继续进入这个吃甜头的状态。可以看出,γ越大,小鸟就会越重视以往经验,越小,小鸟只重视眼前利益(R)。
虽然我们使用了max(Q( s2 s 2 ))来估计了 s2 s 2 的状态,但是此时 s2 s 2 还没有做出任何的选择, s2 s 2 的行为决策要等到Q表更新之后在做出选择。大致的流程如下流程图所示。

1.2.3 Q_learning整体算法
Initialize Q arbitrarily // 随机初始化Q表
Repeat (for each episode): // 每一次从开始到结束是一个episode
Initialize S // S为初始位置的状态
Repeat (for each step of episode):
Choose a from s using policy derived from Q(ε-greedy) //根据当前Q和位置S,使用一种策略,得到动作A,这个策略可以是ε-greedy等
Take action a, observe r // 做了动作A,到达新的位置S',并获得奖励R,奖励可以是1,50或者-1000
Q(S,A) ← Q(S,A) + α*[R + γ*maxQ(S',a))-Q(s,a)] // 在Q中更新S
S ← S'
until S is terminal //即到游戏结束为止当Agent处在 s1 s 1 的时候,通过Q网络和策略选择了 a2 a 2 ,观察到下一步的状态 s2 s 2 ,估计出下一步选择哪个action会有maxQ,,用这个 Q 值作为当前状态动作对 Q 值的目标。这样就有了一个[ s1 s 1 , a2 a 2 , r , s2 s 2 ].
处于状态 s’ 时,仅计算了 在 s’ 时要采取哪个 a’ 可以得到更大的 Q 值,并没有真的采取这个动作 a’;动作 a 的选取是根据当前 Q 网络以及策略(e-greedy),目标 Q 值的计算是根据 Q 值最大的动作 a’ 计算得来。
Epsilon-greedy 策略是在决策之上的一种策略。比如 epsilon = 0.9 时, 就说明有 90% 的情况我会按照 Q 表的最优值选择行为,10% 的时间使用随机选行为,这样做的目的是让其有机会跳出局部最优
1.3 Sarsa Algorithm
Sarsa Algorithm 是强化学习中的一个决策算法
Sarsa Algorithm是使用Q 表的形式决策的。
Q表中的值是随机设置的,称为估计值
Sarsa Algorithm的目的是为了更新Q表,使之成为更准确的Q表。
1.3.1 Sarsa Algorithm决策
Sarsa Algorithm使用的决策和Q_learning的决策是一样的。
我们选取Agent处在 s1 s 1 状态的时候,此时Agent要向 s2 s 2 和 s3 s 3 状态转换。
s 和a的潜在奖励我们用如下的Q表格表示。
决策:当Agent处在 s1 s 1 状态的时候,有两个action可供选择, a1 a 1 和 a2 a 2 ,从上面的Q表可以看出,选择 a2 a 2 的潜在奖励要比 a1 a 1 高,Q( s1 s 1 , a1 a 1 )= -2,Q( s1 s 1 , a2 a 2 ) = 1。所以我们判断选择 a2 a 2 作为下一步行为。
当Agent选择了 a2 a 2 之后,就进入状态 s2 s 2 ,然后从Q表格中得到Q( s2 s 2 , a1 a 1 ),和Q( s2 s 2 , a2 a 2 )的值,比较他们的大小,选择下一步的行为。然后进入状态 s3 s 3 ,重复之前的操作。
1.3.2 Sarsa 更新
Agent 在 s1 s 1 状态时,会选择一个最大潜在奖励的 a2 a 2 .
Sarsa Algorithm更新和Q_learning的更新有一个区别就是:Sarsa Algorithm是说到做到,而Q_learning是说到未必做到。在Q_learning Algorithm, s2 s 2 中Agent估算过最大收益的action,但是在真正 s2 s 2 做决策的时候,却不一定是这个估算的最大收益的action。在Sarsa Algorithm, s2 s 2 所做的估算的动作,也是接下来要执行的Action。所以在Sarsa Algorithm和Q_learning会在现实值中有所不同,Sarsa Algorithm去掉了Q_learning中的maxQ( s2 s 2 ),而直接选择了Q( s2 s 2 , a2 a 2 )。然后计算差距和更新Q表中的Q( s1 s 1 )。
当Agent在 s1 s 1 的状态选择 a2 a 2 之后,Sarsa Algorithm会进行Q表的更新,更新原Q表中maxQ( s1 s 1 )的值。在未修改之前,Q表中的值都是估计量。
设置两个值:
gamma(γ)—–>衰减值(这里的衰减值和超市打γ折意思差不多)
alpha(α) ——> 学习效率
更新方式:

根据1.2.1中的Q表,得知maxQ( s1 s 1 ) = Q( s1 s 1 , a2 a 2 ),所以在这一步中修改的为Q( s1 s 1 , a2 a 2 )的估计值。
①:Q( s1 s 1 , a2 a 2 )的估计值:Q( s1 s 1 , a2 a 2 )
②:Q( s1 s 1 , a2 a 2 )的现实值:Q( s2 s 2 , a2 a 2 ) * γ + R
③:计算估计值与现实值之间的差距:差距 = 现实值 - 估计值
④:得到新的Q( s1 s 1 , a2 a 2 ):新Q( s1 s 1 , a2 a 2 ) = 老Q( s1 s 1 , a2 a 2 ) + α * 差距
整理得到:
Q( s1 s 1 , a2 a 2 ) <—-(1-α) * Q( s1 s 1 , a2 a 2 ) + α *(Q( s2 s 2 , a2 a 2 ) + R)
1.3.3 Sarsa 整体算法
Initialize Q arbitrarily // 随机初始化Q表
Repeat (for each episode): // 每一次从开始到结束是一个episode
Initialize S // S为初始位置的状态
Choose a from s using policy derived from Q(ε-greedy)
Repeat (for each step of episode):
Take action a, observe r, s'
Choose a' from s' using policy derived from Q(ε-greedy)
Q(S,A) ← Q(S,A) + α*[R + γ*Q(S',a')-Q(s,a)] //在Q中更新S
S ← S'; a← a'
until S is terminal //即到游戏结束为止
当状态处在 s1 s 1 的时候,根据当前的Q网络和策略选择了行动 a2 a 2 ,观察到下一个状态 s2 s 2 ,并再一次运用当前Q网络和策略选择了行动 a2 a 2 。获得了一个[ s1 s 1 , a2 a 2 , r , s2 s 2 , a2 a 2 ]序列。
处于状态 s’ 时,就知道了要采取哪个 a’,并真的采取了这个动作。动作 a 的选取遵循 ε-greedy 策略,目标 Q 值的计算也是根据策略得到的动作 a’ 计算得来。
2.References
强化学习总概:https://www.jianshu.com/p/f8b71a5e6b4d
Q_learing算法介绍:https://www.jianshu.com/p/44ce8a55d820
Sarsa算法介绍:https://www.jianshu.com/p/a2a2efcee79c