译:深度学习,自然语言处理及特征表示方法 Deep Learning, NLP, and Representations
from: http://colah.github.io/posts/2014-07-NLP-RNNs-Representations/
Intro
过去数年间,深度神经网络(DNN)已经统治了模式识别领域,尤其在计算机视觉领域,DNN几乎将此前的旧有方法全部赶出了竞争舞台,语音识别领域的情况也在向同样的方向发展。但暂且抛开表面结果,为什么DNN会获得如此大的成功?
这篇博文回顾了在DNN在自然语言处理(NLP)领域的应用中数种极具代表性的方法及其结果。此举的目的是想通过尽量优雅简洁的方式,帮助各位更好地理解DNN之所以如此work的原因。
One hidden layer neural networks
我们已知道单隐层NN具有一条性质:给定足够多的隐层单元,单隐层网络可以1/n的精度逼近任意函数。这是一个经常被提及——但不幸的是被更多人错误理解了的一条结论。
直观来看这条定理的确是正确的,因为我们可以将隐层以查找表的方式来使用 (used as a lookup table)。
为了简洁起见,考虑一个感知机网络。我们知道感知机是一个非常简单的神经元,在达到某一阈值的时候被激活,在未达到的时候不激活。一个感知机网络接收0-1的二值化输入并给出二值的输出。
注意此处只有有限种可能的输入(由于是二值的,有n^2个可能输入)。为每一个可能的输入,我们可构建一个神经元被且仅被该输入激活,而后我们可以利用该神经元与输出层的连接权值来控制该输入情况下的输出。
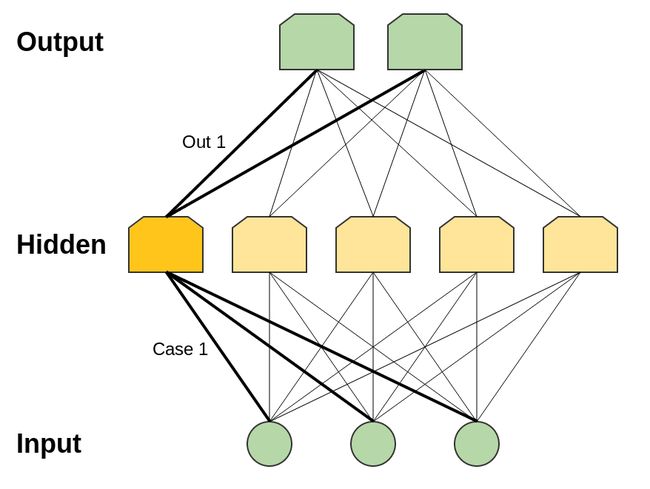
由上可知,单隐层网络的确是具有普适性的逼近能力,但拥有这个能力并不稀奇。模型能做到跟查编码表一样的功能并不会是一个证明模型优越性的有力论据:这只意味着你的模型并不能很好地完成现实任务。
普适性意味着一个网络可以拟合任意给定的训练数据,但并不意味着该网络对未知的新数据有很好的泛化预测能力。
所以我们得到了一个结论,普适逼近的能力并不能解释为什么神经网络有如此良好的表现,看起来真实的原因隐藏的更深。。。为了理解它,我们首先需要了解一些确切的结论。
Word Embeddings
首先引入一个深度学习研究的分支:词嵌入 作为一个确切的例子来开始整篇文章。以我个人的观点来看,词嵌入是当前最激动人心的深度学习研究领域之一,尽管在十多年前Bengio等人就提出了其基础理论[3]。在这之外,我认为这也是一个极佳的可以用来解释DL高效性的领域。
词嵌入 W : words -> Rn 是一个参数化的函数,可将某种语言中的一个词汇映射为一个n维实数空间中的向量(可能有200-500维)。举个栗子:

(一般来说,此函数为一个由参数矩阵θ决定的矩阵,每行对应一个词![]() )
)
一般对于每一个词生成一个随机向量来初始化 W,其在最优化某些目标的过程中完成学习,最终生成有意义的词向量。
举个栗子,我们可能想要训练一个网络来预测一个5-gram(五个词汇构成的序列)是否是“有效的”。我们可以很轻易地从维基百科上得到很多5-gram(如:"cat sat on the mat")然后通过随机替换某一个词(如:"cat sat song the mat")来将它们"破坏",如此我们可以让替换后的5-gram变得无意义,得到一些无意义的句子。
我们要训练的模型会在输入的5-gram的每一个单词上运行得到对应该单词的向量,然后这些向量将会传递给另一个模块(此处记做R),R将会尝试预测输入的5-gram是“有效的(valid)”还是“被破坏过的(broken)”。

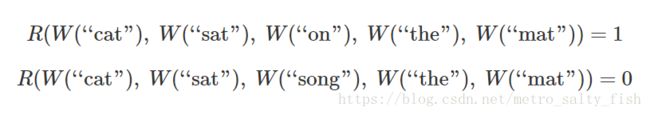
为了实现这些值的正确预测,网络需要为模型 W 和 R 都学习到较好的参数。
目前看来,这个任务本身并不是非常的有意思。它可能可以用来检测文档中语法错误或者别的什么,仅此而已。但真正有趣的,也是我们真正关心的是 W。(实际上,对我们来说,上述任务的关键点就在于学习W。我们还可以使用别的一些什么任务——另一个常被使用的是预测句子中的下一个词。但我们并不关心任务本身。在本节的余下部分里会讨论很多词嵌入的结果,并且此处对不同方法间的差异不做过多区分。)
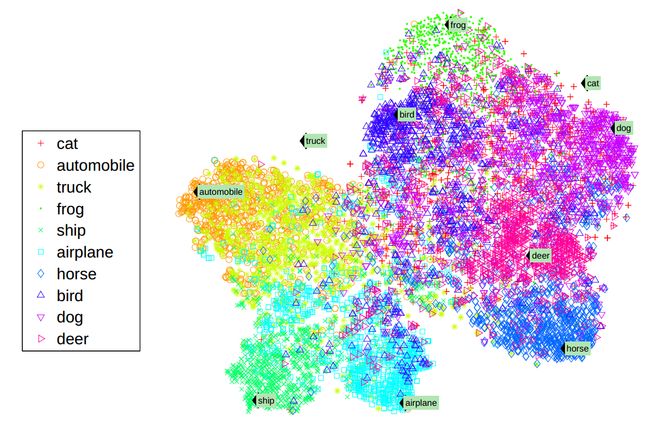
先来做一件事:使用一种复杂的可视化高维数据的技术t-SNE,来可视化词嵌入的向量空间,感觉一下词嵌入究竟在做什么。

t-SNE的词嵌入可视化结果 From Turian et al. (2010)
这样的词图可以让我们更直观的看到词嵌入在做什么:相似的词位置会相对靠近。我们也可以观察与一个给定的词的嵌入结果最相近的词(下图),一般来说这些词的含义会趋于相似。
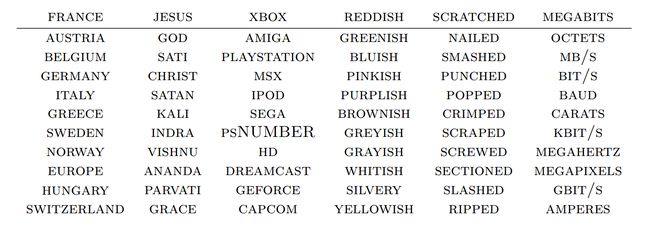
数个给定词的“嵌入最近”词表,From Collobert et al. (2011)
网络给意思相近的词汇赋予一个相近的向量是很自然的行为。如果将一个句子中的词替换为它的同义词(例:"a few people sing well" -> "a couple people sing well"),这个句子的有效性并没有被改变。但是单纯观察原始输入的句子,一个词的替换是很大的改变了,如果我们训练的 W 可以将同义词以及近义词映射为距离比较近的向量,那么在决策器 R 看来,R接受的输入并不会有太大的改变。
上述特性是一个非常有用的特性,一种语言中可能的5-grams组合的数目十分庞大,相比之下,我们只有数目非常有限的训练样本可供学习使用。相似词汇的映射接近性可以让我们把对一个句子的处理方式和结果,推广到与其相似的该类句子集合上去。此处所说的推广并不只意味着将一个词替换为同义词,我们也可以处理讲一个词替换为同一类词的情况(例:"the wall is blue" -> "the wall is red")。更进一步地,我们还可以推广到多个同类词的替换(例:"the wall is blue" -> "the ceiling is red")。随着单词数量的提升,这种推广效应可处理的同类句子数量会呈指数级上升。
现在我们知道了 W 所做的工作非常具有现实意义,但是 W 是如何实现这个学习过程的呢?有时在处理类似于“墙是红色的”这种句子之前,模型已经处理过类似的句子,例如“墙是蓝色的”,并且得到了该句子是有效的结论,这种情况在训练过程中会经常出现。既然如此,我们发现将“红色”的嵌入结果向“蓝色”对应的向量稍微靠近一些可以让系统表现的更好。
在模型中,我们仍需要处理每一个样本,但是类推的能力可以赋予模型更好的泛化能力,能让模型把已有的知识应用于没遇到过的句子的分类中去。以人类为例,你见到一个新单词就会理解一个新单词,但当你见到一个新句子,可以理解很多个与其类似的新句子,即使这些句子此前你并没有遇到过。我们尝试赋予网络的就是这个能力。
词嵌入还表现出了一个更加令人称奇的特性:词与词之间的类推关系似乎被编码在了词汇间的差异向量(向量的差值)之中。举个栗子,我们可以看到此处似乎生成了一个表示“男女差异”的一致的差异向量(constant male-female difference vector)。
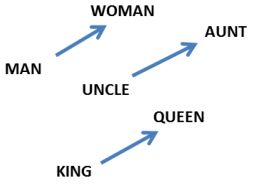
其中:
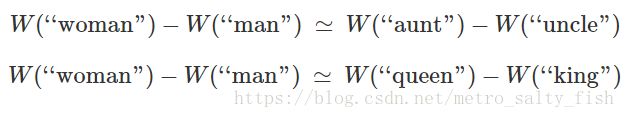
可能这个结果看起来没什么大不了的。但是我们做一下思考,由于性别代词的存在。使得这种有男女差异性词汇的不当使用可以造成句子的语法错误。比如我们会说“她是姑姑”与“他是舅舅”,相似地“他是国王”和“她是女王”也是如此。如果我们看到“她是舅舅”这样一个句子,一般会认为这个句子存在语法上的错误。在本节讨论的问题中我们会随机替换一个词,上述不当替换情况出现的可能性会非常大。
“那是当然!”可能会有人这样说“词嵌入当然可以学习如何编码性别之间的差异,要我说,很有可能最后的向量空间里有一个维度就是专门描述性别的,单数/复数可能也是这么区分出来的!分辨这种简单特征我上我也行!”
但实验结果表明,很多比性别复杂的多的关系也同样可以以这种方式编码,实在是很神奇。
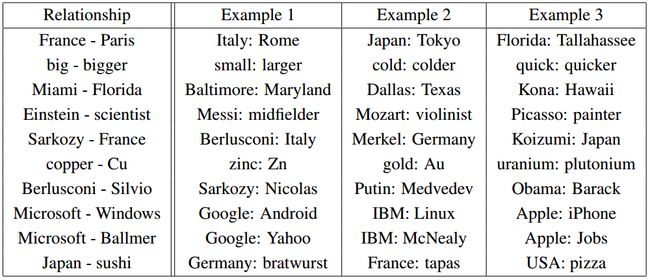
在词嵌入中可以找到的关系对 From Mikolov et al.(2013b).
注意:所有这些有利特性其实都是“附带效应”,我们并未显式地约束词嵌入模型应该让相似的词汇彼此靠近,也没有让它将词汇间的类比关系编码在差异向量中。任务自始至终都非常简单,比如判断一个句子是否有效。所有这些有利的特性或多或少都是在最优化过程中自然形成的。
此处我们可以看到神经网络的一大优势:神经网络模型可以自动地学习如何更好地表示数据(由低级特征解离出高层特征)。而更好的数据表示,目前来看是解决很多机器学习问题的关键。词嵌入只是一个展现NN特征学习表示能力的,特别显著的例子。
Shared representations
词嵌入模型所表现出的特性的确非常有趣,但是我们能不能利用这些特性做一些实际的事情呢?而不是预测一些,比如一个5-grams是否是有效的,这种愚蠢的问题。
我们是为了在一个简单任务中得到更好地表现而学习的词嵌入模型,但基于我们观察到的词嵌入模型的良好表现,你可能会设想将其应用到一些更实际的NLP问题当中去。实际上,类似于此的词表示方法是非常非常重要的:
"词表示方法的应用...已经成为了今年很多NLP系统取得成功的"致胜秘诀(secret sauce)",其应用范围涵盖命名实体识别,词性标注,词义解析和语义角色标注。(Luong et al. (2013))
这种泛用性的策略——在任务A上学习良好的表示而后在任务B上再次使用它——是深度学习工具使用的主要窍门(trick)之一。取决于任务细节的不同它也有不同的名字:预训练、迁移学习和多任务学习。此种方法的关键优势之一是其可以从多于一种的数据中学习其表示。
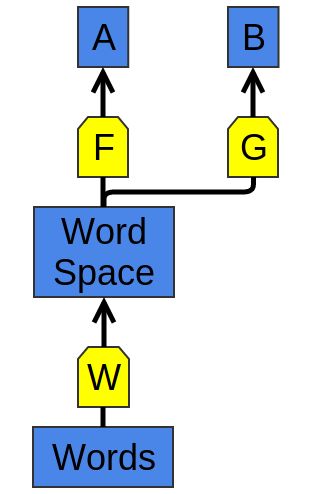
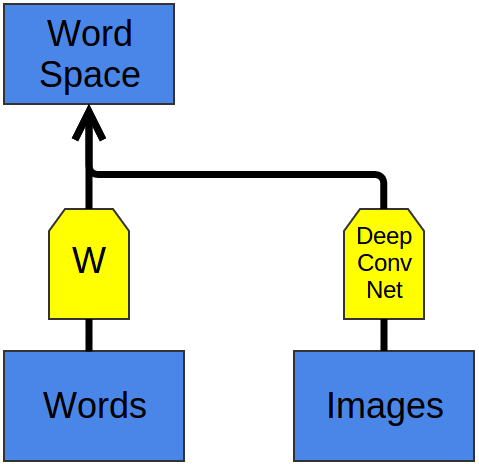
学习W,F以处理任务A,之后G可以在W的基础上学习以处理任务B
这个trick有一个与之对应的想法。 我们可以学习一种将多种数据映射为单一表示的方法,而不是学习如何表示一种数据并使用它来执行多种任务。
Socher et al. (2013a) 提出的双语词嵌入系统是一个非常好的例子。 我们可以学习如何将来自两种不同语言的单词映射到一个共享的特征空间去。 此处我们学习如何在同一个空间中嵌入英文和中文单词。我们以上述方式训练两个词嵌入模型Wen和Wzh,此处我们还知道一些先验知识:已知的一些英语词汇与中文词汇有相似的含义。所以在求解最优化问题时,我们可以加上相应的罚项来使这些已知的双语词汇对的词向量互相尽可能地靠近。
最终我们可以观察到那些我们已知的翻译词汇对的词向量会比较接近,由于我们在最优化问题中加入了这一目标,所以这个结果是合理的。但是有趣的事情发生了:那些我们未知的翻译词汇对的词向量也十分接近。
鉴于我们此前观察到的词嵌入模型的特点,这个结论可能并不是特别令人惊讶。词嵌入模型会将相似的词的向量聚集在一起,所以如果我们给定一个英语词汇与中文词汇的对应关系,则两个词在各自语言中的同义词也会彼此接近。此外我们还知道词汇之间的类别差异会趋向于被一个一致的差异向量所表示,所以如果我们在两种语言不同类的词汇中给定足够多的翻译配对,应该就可以强制英语词嵌入和中文词嵌入模型生成相似的类别差异向量。带来的结果就是,如果我们给定一对“男性版本”词汇的翻译配对,模型应该可以由此学习出“女性版本”词汇的翻译配对。
直观来看这个过程,可以理解为对于一部分类别,给定这些类别的一些词在两种语言中的对应关系,从而固定两种语言中这些类别的词向量位置,此后再由这些固定位置的类别与差异向量产生其他类别的位置,最终使两种语言的嵌入有着类似的“形状”。
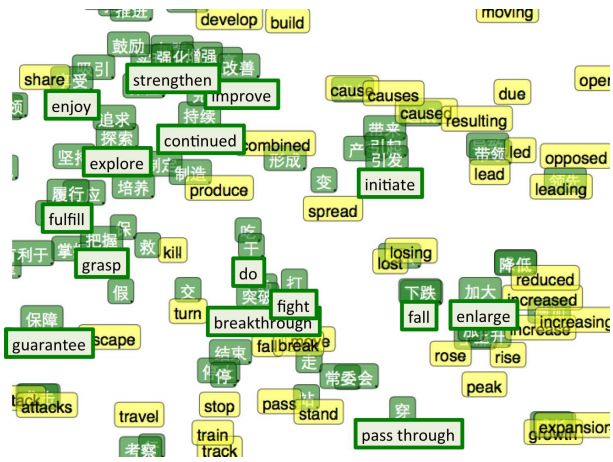
t-SNE可视化的双语词嵌入结果,绿色为中文,黄色为英文 (Socher et al. (2013a))
在双语词嵌入中,我们为两种非常相似的数据学习了一个共享的表示方法。但进一步地,我们还可以学习如何将两种非常不同的数据映射到同一个特征空间中去。
最近,深度学习的相关研究已经开始探索可以将图像与词汇映射为同一种表示的模型。
其用来分类图像基础想法是模型对一个图像输出一个词向量。狗的图像的词向量会被映射到“狗”这个词的词向量附近,马的的图像映射到“马”附近,车的图像映射到“车”附近,以此类推。
该模型有趣的部分在于使用它尝试分类一种它从未见过的图像的时候。举个栗子,假设该模型从未被训练过检测含有猫的图像——即未被告知过猫的图像应该被映射在“猫”的词向量附近——那么当我们尝试使用这个模型分类猫的图像时,会发生什么呢?

(Socher et al. (2013b))
从结果来看,网络仍然能够给这些未见过的新一类图像一个合理的分类结果。含有猫的图像并未被映射到语义空间的随机点,相反,这些猫的图像会趋向于被映射到“狗”的词簇的词向量范围附近,并且实际上更靠近“猫”向量。同样地,卡车的图像被映射到“汽车”附近,并且相比之下更靠近“卡车”向量。
(Socher et al. (2013b))
斯坦福NLP组的成员仅使用了8个已知类(和两个未知的类)就得到了上图所示的结果,已经令人印象十分深刻。但是由于已知的类很少,所以只有很有限个点能够用来表示图像和语义空间之间的映射关系(不是很理解,原文:But with so few known classes, there are very few points to interpolate the relationship between images and semantic space off of.)。
几乎与此同时Google的组做了一个更大规模的实验——他们用了1000个类,而非8个(Frome et al. (2013)),并且此后又有了新的变种(Norouzi et al. (2014))。这些方法都基于同一个非常强力的图像分类模型(Krizehvsky et al. (2012)),但在将图像嵌入到语义空间时所用的方法有一些小小的偏差。
实验结果是令人印象深刻的。即便模型不一定能够给所有未见类的图像都映射一个完全精确的代表该类的向量,但其能够保证至少映射到正确类的近邻类中去。所以,如果你使用该模型来分类数个不同的未见类图像,且其各自所属的类之间差别巨大,该模型的分类结果能够分辨出这种差别。
即便我之前从没见过Aesculapian蛇和Armadillo(犰狳),但如果你给我看这两种动物的照片,我仍然能够告诉你哪个是哪个,因为我对于可能与这两个词分别相关的其他动物有一个大致的判断,然后根据相关的已知动物的样子做出最终判断。这个网络所做的事与此差不多。
(这些结果都是利用某种“这些词类似”的推理规则得到的,但似乎基于单词之间的关系来推导可能会有更好的结果。在我们的词嵌入空间中,男性版本词汇和女性版本词汇之间存在一致的差异向量。而在图像空间中,男性和女性之间则有着一致的区别特征,络腮胡、小胡子、秃头都是某种显而易见的且强烈的男性特征,而乳房、长头发、化妆和珠宝则是显而易见的女性指标。即使你以前从未见过国王,但如果皇后都喜欢戴王冠或者突然都留起了络腮胡,则此时认为“皇后”是一个男性版本的词汇也是合理的。)
共享数据表示是一个非常令人令人兴奋的研究领域,并且它也阐释了为什么关注于数据表示的深度学习方法能受到如此大的关注。
Recursive Neural Networks
(关于递归神经网络RNN与其变体LSTM,见之前转载的简要理解LSTM)
我们以如下的网络结构开展关于词嵌入的讨论:
学习词嵌入模型的模块化网络(From Bottou (2011))
上图表示了一个可写作R(W(w1), W(w2), W(w3), W(w4), W(w5))的模块化网络(Modular network)。其主要包含两个模块 R 和 W。这种将小的神经网络拼接形成总体神经网络结构的方法并未得到非常广泛的应用,但其在NLP领域获得了巨大的成功。
上图所示的模型很强大,但不幸的是有一个限制条件:只能接受固定个数的输入。
可以通过添加关联模块A来解决这个问题,该模块可取得两个单词或短语的表示并将它们融合。
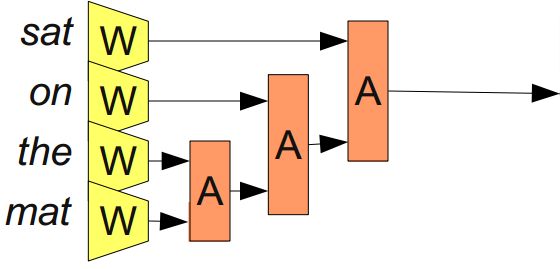
(From Bottou (2011))
通过不断合并单词序列,A将单词的表示转化为短语的表示,甚至最终得到整个句子的表示! 同时因为我们可以合并不同数量的单词,所以我们不必拥有固定数量的输入。
考虑到线性地组合句子中的单词并不一定有意义,比如考虑句子“The cat sat on the mat”,根据语义可以做如下分解:“((the cat) (sat (on (the mat))))”。我们基于此分解来应用模型A:
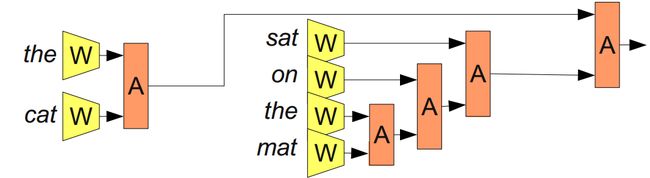
(From Bottou (2011))
这种模型通常被称为“递归神经网络”,因为一个模块的输出经常会被输入给一个相同类型的模块。 它们有时也被称为“树状结构的神经网络”。
RNN已经在相当数量的NLP任务中取得了巨大成功。例如Socher et al. (2013c)使用一个递归神经网络来预测句子的情绪:

还有一个主要的目标是创建一个可逆的句子表示,利用这个表示可以重构一个实际的句子,其意义与原句大致相同。 例如,尝试引入一个解码器 D (A为编码器),它尝试完成的是 A 的逆操作:
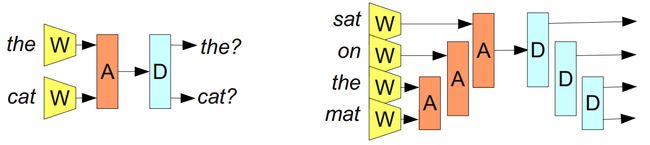
(From Bottou (2011))
如果我们能完成类似的工作,这将会是一个非常强力的工具,比如我们可以尝试建立一个双语的,以句子为输入的表示,并可用其来进行机器翻译。
但不幸的是这个目标非常难以实现,非常非常难以实现(注:本文写于2014年,相关知识可参见AutoEncoder,与16年刘铁岩博士组提出的对偶学习于神经机器翻译的应用)。但考虑到它所能带来的美好愿景,很多研究者都在进行相关的工作。
最近Cho et al. (2014)在短语表示的工作上取得了一些进展,实现了一个可以编码英语短语并解码为法语的模型。我们来看一看它所学到的短语表示:
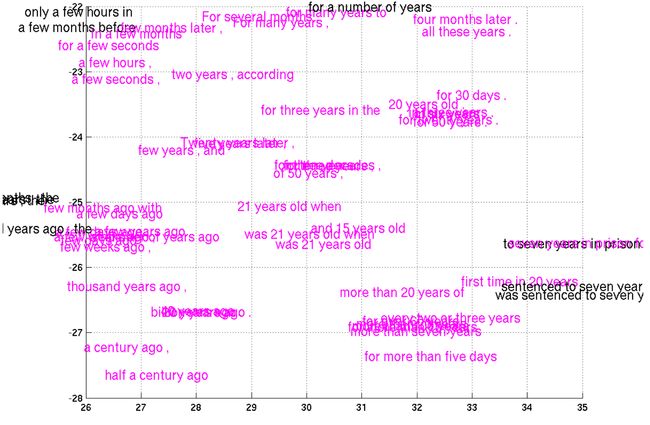
t-SNE可视化的短语表示结果的一小部分(From Cho et al. (2014))
Criticsms
我曾听到过一些批评上述结论的声音,大部分来自其他领域的研究者,主要地,来自自然语言处理以及(计算)语言学。重点不在于这些结果本身,而是从这些结果中我们能够得到的结论,以及这些技术与其他技术的横向对比。
我不认为我有资格评判这些观点谁是谁非,但我鼓励各位有相似担忧或者其他想法的读者在评论中留下你们的想法。
Conclusion
深度学习模型强大的抽象表现能力是一个强有力的观点,这似乎可以回答DNN为何有效这个问题。在这之上,我认为其中隐藏着一些非常美妙的性质:为什么NN如此有效?原因是更好的数据表示方法,更有意义的高级特征,可以在分层模型的最优化过程中慢慢浮现出来。
深度学习是一个非常年轻的领域,其还没有扎实的理论基础,并且各种观点在飞快地更替。也就是说,以表示为中心的神经网络在当下非常流行仅仅是我个人的观点。
这篇文章回顾了很多我认为非常exciting的研究成果,但我的主要动机是为将来阐明深度学习、类型理论与函数式编程之间的关系打好基础。如果你感兴趣可以订阅我的rss feed,以便在在我发布新博文的第一时间收到通知。
(我非常乐意听取各位的意见和想法:对于错别字、技术错误或者希望添加的说明等等,都欢迎在评论中提出,或在github上pull request)
Acknowledgments
I’m grateful to Eliana Lorch, Yoshua Bengio, Michael Nielsen, Laura Ball, Rob Gilson, and Jacob Steinhardt for their comments and support.
Constructing a case for every possible input requires 2n hidden neurons, when you have n input neurons. In reality, the situation isn’t usually that bad. You can have cases that encompass multiple inputs. And you can have overlapping cases that add together to achieve the right input on their intersection.↩
(It isn’t only perceptron networks that have universality. Networks of sigmoid neurons (and other activation functions) are also universal: give enough hidden neurons, they can approximate any continuous function arbitrarily well. Seeing this is significantly trickier because you can’t just isolate inputs.)↩
Word embeddings were originally developed in (Bengio et al, 2001; Bengio et al, 2003), a few years before the 2006 deep learning renewal, at a time when neural networks were out of fashion. The idea of distributed representations for symbols is even older, e.g. (Hinton 1986)."↩
The seminal paper, A Neural Probabilistic Language Model (Bengio, et al. 2003) has a great deal of insight about why word embeddings are powerful.↩
Previous work has been done modeling the joint distributions of tags and images, but it took a very different perspective.↩
I’m very conscious that physical indicators of gender can be misleading. I don’t mean to imply, for example, that everyone who is bald is male or everyone who has breasts is female. Just that these often indicate such, and greatly adjust our prior.↩