title: Solr安装配置及使用
categories: 搜索
tags: Solr
date: 2019-07-25 15:47:55
1.Solr安装与配置
1.1什么是Solr
大多数搜索引擎应用都必须具有某种搜索功能,问题是搜索功能往往是巨大的资源消耗并且它们由于沉重的数据库加载而拖垮你的应用的性能。
这就是为什么转移负载到一个外部的搜索服务器是一个不错的主意,Apache Solr是一个流行的开源搜索服务器,它通过使用类似REST的HTTP
API,这就确保你能从几乎任何编程语言来使用solr。
Solr是一个开源搜索平台,用于构建搜索应用程序。 它建立在Lucene(全文搜索引擎)之上。 Solr是企业级的,快速的和高度可扩展的。
使用Solr构建的应用程序非常复杂,可提供高性能。
为了在CNET网络的公司网站上添加搜索功能,Yonik Seely于2004年创建了Solr。并在2006年1月,它成为Apache软件基金会下的一个开源项目。
并于2016年发布最新版本Solr 6.0,支持并行SQL查询的执行。
Solr可以和Hadoop一起使用。由于Hadoop处理大量数据,Solr帮助我们从这么大的源中找到所需的信息。不仅限于搜索,Solr也可以用于存储目的。
像其他NoSQL数据库一样,它是一种非关系数据存储和处理技术。
总之,Solr是一个可扩展的,可部署,搜索/存储引擎,优化搜索大量以文本为中心的数据。
1.2 Solr安装
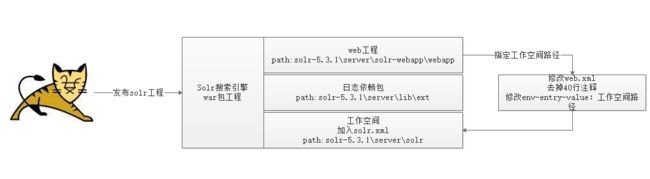
安装流程如上图:
- 发布solr的web工程
- 加入日志依赖包
- 创建工作空间
- 指定solr工作空间
- 创建solr索引库
首先解压tomcat,并将tomcat放在D:\solr\apache-tomcat-8.5.23目录下,在tomcat的webapps目录下创建solr目录。如下图:
找到solr的web工程,工程在solr-5.3.1\server\solr-webapp\webapp目录下,将该目录下所有文件拷贝到tomcat的webapps/solr目录下,如下图
1.2.2 加入日志依赖
找到日志包,日志包在solr-5.3.1\server\lib\ext目录下,并将所有jar包加入到tomcat的webapps/solr/WEB-INF/lib目录下。

加入log4j.properties
将solr-5.3.1\server\resources目录下的log4j.properties加入到tomcat的webapps/solr/WEB-INF/classes目录下,不过classes目录不存在,需要手动创建。

1.2.3 创建工作空间
在tomcat的webapps/solr目录下创建solrhome目录,把该目录作为solr的工作空间,该工作空间主要用于存储创建索引的索引文件信息。该目录创建后,需要拷贝solr-5.3.1\server\solr\solr.xml到该目录(solrhome)下,solr才能识别该目录为solr工作空间。

1.2.4 指定solr工作空间
创建solrhome工作空间后,需要告诉solr的web工程solrhome的路径。打开tomcat的webapps/solr/WEB-INF下的web.xml文件,找到第40行。

把注释去掉,并将

1.2.5 创建solr索引库
我们在solrhome目录下创建一个文件叫collection1,该目录用于存储我们创建的索引信息。索引信息需要引入一些核心配置,对应核心配置在solr-5.3.1\server\solr\configsets目录下,我们拷贝sample_techproducts_configs目录下的所有文件,并粘贴到collection1目录中。

1.2.6 启动tomcat并关联索引库
启动tomcat,并访问 http://localhost:8080/solr 效果如下:
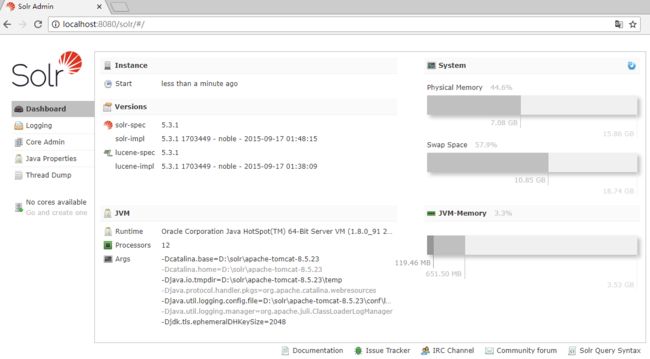
此时看到左下角有一段提示: No cores available 表明没有索引库,原因是刚才我们手动创建的索引库并未交给solr管理,需要创建对应关联信息。
点击 No cores available 弹出一个添加界面,分别填写对应信息,然后点击 Add Core 按钮即可。
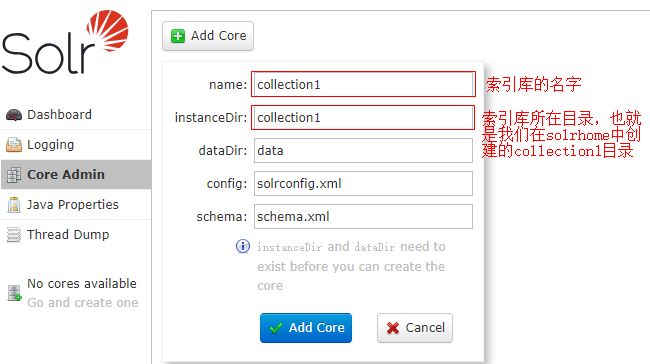
此时会出现collection1索引库对应信息
1.2.7 其他依赖工具安装

我们点击solr的管理界面的logging,发现有一片警告,原因是solr默认还依赖了其他包,当然这些包可以引用也可以不引用,不影响solr使用。不过为了让这里不出现警告,我们还是安装一下。
将solr-5.3.1目录下的contrib和dist目录拷贝到tomcat的webapps/solr/solrhome目录下,并修改solrhome目录下的的collection1/conf/solrconfig.xml,修改75行
修改前:

修改后:

其中${solr.install.dir:}指的是当前索引所在的位置 collection1文件夹里,../表示向上一级目录,这里从collection1里向上一级查找的话就正好是contrib和dist目录。此时再次重启tomcat,黄色警告消失!
1.3 管理界面介绍
1.3.1 Dashboard
仪表盘,显示了该Solr实例开始启动运行的时间、版本、系统资源、jvm等信息。
1.3.2 Logging
Solr运行日志信息
1.3.3 Cloud
Cloud即SolrCloud,即Solr云(集群),当使用Solr Cloud模式运行时会显示此菜单.
1.3.4 Core Admin
Solr Core的管理界面。在这里可以添加SolrCore实例(有bug,不推荐使用浏览器界面添加SolrCore)。
1.3.5 java properties
Solr在JVM 运行环境中的属性信息,包括类路径、文件编码、jvm内存设置等信息。
1.3.6 Tread Dump
显示Solr Server中当前活跃线程信息,同时也可以跟踪线程运行栈信息。
1.3.7 Core selector
选择一个SolrCore进行详细操作,如下:
1.3.7.1 dataimport
可以定义数据导入处理器,从关系数据库将数据导入到Solr索引库中。
默认没有配置,需要手工配置。
1.3.7.2 Document
通过/update表示更新索引,solr默认根据id(唯一约束)域来更新Document的内容,如果根据id值搜索不到id域则会执行添加操作,如果找到则更新。
通过此菜单可以创建索引、更新索引、删除索引等操作,界面如下:
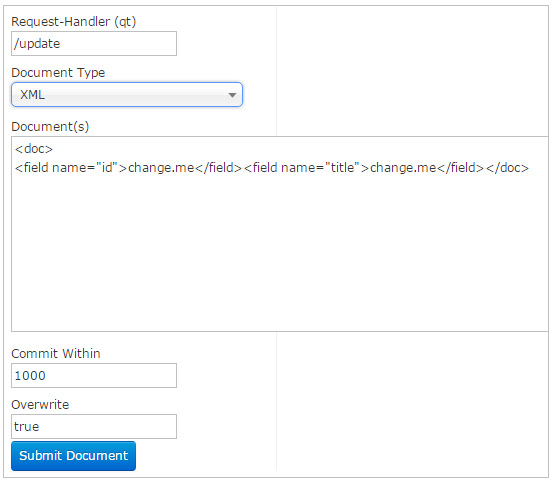
- overwrite="true" : solr在做索引的时候,如果文档已经存在,就用xml中的文档进行替换
- commitWithin="1000" : solr 在做索引的时候,每隔1000(1秒)毫秒,做一次文档提交。为了方便测试也可以在Document中立即提交,后添加“
”
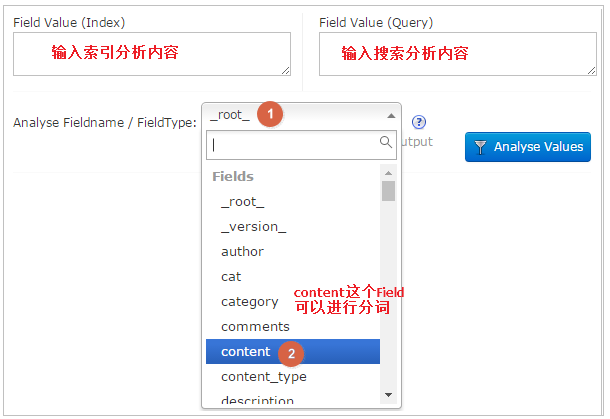
1.3.7.3 Analysis
通过此界面可以测试索引分析器和搜索分析器的执行情况
1.3.7.4 Query
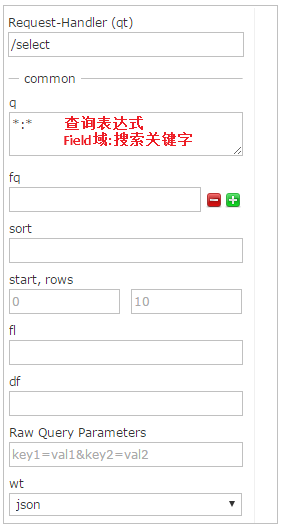
通过/select执行搜索索引,必须指定“q”查询条件方可搜索。
第2章 中文分析器IK Analyzer
2.1 IK Analyzer简介
IK Analyzer 是一个开源的,基亍 java 语言开发的轻量级的中文分词工具包。从 2006年 12 月推出 1.0 版开始, IKAnalyzer 已经推出了 4 个大版本。最初,它是以开源项目Luence 为应用主体的,结合词典分词和文法分析算法的中文分词组件。从 3.0 版本开始,IK 发展为面向 Java 的公用分词组件,独立亍 Lucene 项目,同时提供了对 Lucene 的默认优化实现。在 2012 版本中,IK 实现了简单的分词歧义排除算法,标志着 IK 分词器从单纯的词典分词向模拟语义分词衍化。
2.2 IK Analyzer配置
步骤:
1、把 IKAnalyzer的依赖包添加到 webapps/solr/WEB-INF/ lib 目录下

2、把扩展词典、停用词词典、配置文件放到 solr 工程的 WEB-INF/classes 目录下。
3、修改 Solrhome 的 schema.xml 文件,配置一个 FieldType,使用 IKAnalyzer,可以在320行添加。

第3章 配置域
schema.xml文件在SolrCore的conf目录下,在此配置文件中定义了Filed域以及域的类型等一些配置。在solr中域必须先定义后使用。
域相当于数据库的表字段,用户存放数据,因此用户根据业务需要去定义相关的Field(域),一般来说,每一种对应着一种数据,用户对同一种数据进行相同的操作。
域的常用属性:
· name:指定域的名称
· type:指定域的类型
· indexed:是否索引
· stored:是否存储
· required:是否必须
· multiValued:是否多值,存储多个值时设置为true,solr允许一个Field存储多个值,比如存储一个用户的好友id(多个),商品的图片(多个,大图和小图)
3.1 域
修改solrhome的schema.xml 文件 设置业务系统 Field

3.2 复制域
可以将多个Field复制到一个Field中,以便进行统一的检索。当创建索引时,solr服务器会自动的将源域的内容复制到目标域中。
- source:源域
- dest:目标域,搜索时,指定目标域为默认搜索域,可以提高查询效率。
定义目标域:
目标域必须要使用:multiValued="true"
复制域的作用在于将某一个Field中的数据复制到另一个域中.在我们项目中,搜索关键词的时候,一般会搜索标题、分类名称、商家名称、品牌名称,如果要我们搜索,一般会挨个挨个匹配,就像使用SQL语句中的OR一样,这种效率比较低,我们可以使用复制域,将多个域的数据集中到一个域中搜索。
过去SQL实现示例
select * from table where title like '%华为%' or category like '%华为%' or seller like '%%华为' or brand like '%华为%'
使用复制域实现示例:
select * from table where keywords like '%华为%'
一般会搜索标题、分类名称、商家名称、品牌名称,我们可以把这几个组合到一起去,说通俗点,就是讲多个域的值拼接到一起,组成一个新的域。我们项目中可以如下实现:
3.3 动态域
当我们需要动态扩充字段时,我们需要使用动态域。对于品优购,规格的值是不确定的,所以我们需要使用动态域来实现。
name:动态域的名称,是一个表达式,*匹配任意字符,只要域的名称和表达式的规则能够匹配就可以使用。
例如:搜索时查询条件[product_i:钻石]就可以匹配这个动态域,可以直接使用,不用单独再定义一个product_i域。
配置:
3.4 主键域
uniqueKey
id
相当于主键,每个文档中必须有一个id域。
3.5 fieldType(域类型)

- name:域类型的名称
- class:指定域类型的solr类型。
- analyzer:指定分词器。在FieldType定义的时候最重要的就是定义这个类型的数据在建立索引和进行查询的时候要使用的分析器analyzer,包括分词和过滤。
- type:index和query。Index 是创建索引,query是查询索引。
- tokenizer:指定分词器
- filter:指定过滤器
第4章 Spring Data Solr入门
4.1 Spring Data Solr简介
虽然支持任何编程语言的能力具有很大的市场价值,你可能感兴趣的问题是:我如何将Solr的应用集成到Spring中?可以,Spring Data Solr就是为了方便Solr的开发所研制的一个框架,其底层是对SolrJ(官方API)的封装
4.2 Spring Data Solr入门小Demo
4.2.1 搭建工程
创建maven工程 springdatasolr-demo
4.2.2 pom.xml

在src/main/resources下创建 spring-solr.xml

4.2.2 @Field 注解
创建 com.it.model 包,将品优购的Item实体类拷入本工程 ,属性使用@Field注解标识 。 如果属性与配置文件定义的域名称不一致,需要在注解中指定域名称。

4.2.3 增加(修改)
创建测试类SpringDataSolrTest.java




4.2.7 条件查询
Criteria 用于对条件的封装:

