感谢Dr.fish的耐心讲解和细致回答。
本次课的随堂作业如下:
基于HRSalaries.csv数据回答问题:
- 计算HRSalaries数据中评分Review_Score的均值和中位数,并判断其偏度是左偏还是右偏;
- Review_Score的IQR值是多少?并绘制该数据的box图;
- Review_Score的标准差是多少?
- 在Review_Score中,求落在两个标准差内的数据占总数的百分比;
- 对于DoIT部门,计算其收入和评分的相关系数。
先导入要用的计算包们:
# 导入所有要用的分析库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from __future__ import division # 导入精确除法
%matplotlib inline
%config InlineBackend.figure_format = 'retina'
然后导入数据并看一眼!~
# 导入数据并查看
df = pd.read_csv('HRSalaries.csv')
df.head()
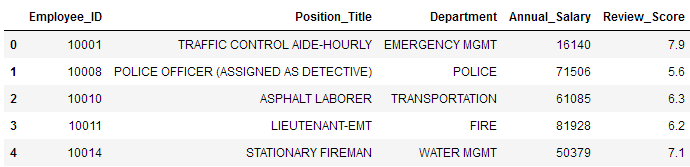
查看数据
# 查看整体数据(主要看是否存在缺失值)
df.info()

查看数据整体信息
** 小结:**
- 数据表共5个字段,30284条数据
- 未存在缺失值,可直接使用
** Q1.计算HRSalaries数据中评分Review_Score的均值和中位数,并判断其偏度是左偏还是右偏**
# 计算review_score均值
score = df.Review_Score
score.mean()
6.4558908994849205
# 计算review_score中位数
score.median()
6.5
** 答:**Review_Score字段均值6.46,中位数6.5,因为 中位数>均值 ,所以数据呈左偏状态,整体样本score偏小。
** Q2.Review_Score的IQR值是多少?并绘制该数据的box图**
# 1.计算review_score的IQR值
sort = score.sort_values() #排序
Q1 = score.quantile(0.25)
Q3 = score.quantile(0.75)
score.quantile(0.5)
IOR = Q3 - Q1
Q1:5.8
Q3:7.2
IOR:1.4000000000000004
** 备注: **
pandas可以直接输出中位数,使用.median()函数实现
score.median() #验证中位数
6.5
# 2.绘制IQR的box图
score.plot(kind = 'box', vert = False, figsize = (15,5))
plt.show()

IQR box图
绘制正态分布图验证一下
#绘制正态分布柱图
mu = score.mean() #正态分布均值
sigma = score.std() #标准差
x = score
num_bins = 200 #柱子的数量
plt.hist(x, num_bins, normed = 1,facecolor = '#00bfff') # normed 概率密度,和为1
plt.xlabel('Review_Score')
plt.ylabel('Probability')
plt.title('SCORE NORMAL DISTRIBUTION' )
plt.show()
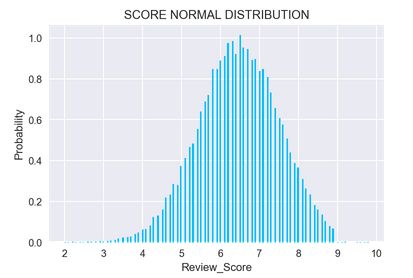
score normal distribution
** 答:**通过观察图形,发现score数据呈右偏态分布,大部分数据分布在 5.8 - 7.2 之间。
** Q3.Review_Score的标准差是多少?**
# 计算标准差
std = score.std()
1.030404588021642
# 验证一下
mean = score.mean()
np.sqrt(np.sum(((score - mean) ** 2) / (len(score) - 1)))
1.0304045880216568
** 答:**score标准差约为1.03,利用两种计算方法得到的结果基本一致(.std()仅给出小数点后15位)。
** Q4.在Review_Score中,求落在两个标准差内的数据占总数的百分比 **
# 落在两个标准差内的数据占总体的百分比
section = score[(score > score.mean() - score.std() * 2) & (score < (score.mean() + score.std() * 2))] # 过滤两个标准差之间的数据
section.count() / len(score) # 计算占比
0.96179500726456213
# 另一种方法
len(score[score.between(mean - std * 2, mean + std * 2)]) / len(score)
0.9617950072645621
** 答:**约有96.2%的数据落在2个标准差之间。
** Q5.对于DoIT部门,计算其收入和评分的相关系数**
# 计算DoIT部门收入和评分的相关系数
department = df[df.Department == 'DoIT']
print(np.corrcoef(department.Annual_Salary, department.Review_Score)[1,0])
0.00602457101049
出个散点图看一下
# DoIT部门收入和评分散点图
plt.scatter(department.Review_Score, department.Annual_Salary, c = ('#00bfff'), alpha = 0.6)
plt.show()
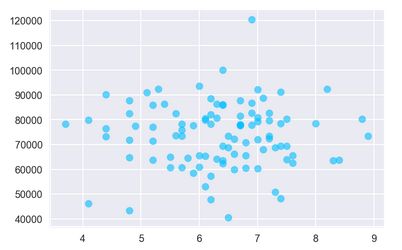
DoIT部门收入和评分散点图
** 答:**DoIT部门收入和评分的相关系数为0.006,不相关。