介绍
Mask RCNN提出于2018年,是在Faster-RCNN的基础上改进后被用于解决图像instance segmentation的问题。相对于原来的Faster_RCNN主干框架,它在网络的头上引入了另外一条FCN并行分支用来检测ROI的mask map信息。这样最终它的头部共有三条并行的分支分别用来处理ROI区域的类别识别、目标框位置回归及相应的mask map回归。
下图为Mask-RCNN的基本框架描述。

instance segmentation
instance segmentation = object detection + semantic segmentation。
object detection我们知道是用于检测出图片上目标的位置框。而semantic segmentation我们在之前的FCN模型介绍时也提到过它是用于识别出图片上每一个像素点所对应的物体类别。instance segmentation可视为这两个问题的合集即用于识别出目标框里面目标物体的每个像素点的归属类别(因为已经知道了目标框内存在物体的类别,所以我们这里只需分辨出目标框内的每一个像素点是前景还是背景即可,所以它是个目标框内部像素级别的二分类问题。)
从下图Mask-RCNN的输出结果中我们能更好地理解何为instance segmentation及它与objection detection和semantic segmentation之间的关系。

Mask-RCNN
在前面已经说过了本质上Mask-RCNN = Faster-RCNN + FCN。
Mask-RCNN的主干特征提取网络同Faster-RCNN一样可以选用任何CNN网络如VGG16/Resnet系列等。论文中作者使用了基本Resnet与FPN网络来分别作为模型的主干网络。在主干网络最终产生的feature maps集合之上,我们使用RPN生成多个region proposals出来。然后再将这些region proposals分别生成对应的ROI窗口,进而用于后续的分类、目标框定位及目标框Mask map识别等。在这里作者对之前的粗粒度ROI pool进行了改进,提出了更加细粒度的,可在子像素级别上提取ROI窗口区域特征的ROI align层。它可以有效地避免像素错位,能够取得更加准确的区域位置信息。
下图为Mask-RCNN的网络头部结构描述。

Mask-RCNN最终的loss也由三部分来组成即:L = Lcls + Lbox + Lmask。
- Mask分支
关于分类与目标框定位的分支,Mask-RCNN与之前介绍过的Faster-RCNN并无区别,因此我们这里只对另外的Mask分支进行讲解。
Mask分支通过在ROI Align层后吐出的ROI特征上接上一个FCN,最终得到一个与些ROI区域相对应的mask map出来。这个mask map有K个channels。K在这里表示目标可能的类别数目。另外每个channel的mask map上面都是些二元信息,分别表示ROI区域上面的某位置点是前景还是背景。
在计算Lmask时,我们只对这K个maps中的第k个map进行处理,在这里k表示由另外的类别识别分支所定位出的此ROI区域的物体类别。
这样一种设计本质上使得mask分支可与另外两个分支真正是独立进行,互不影响(当然只有在计算training loss进而对模型参数进行优化时才会有所干联)。
- ROIAlign
不同于之前Faster-RCNN用于提取ROI窗口的RPIPool,Mask-RCNN使用了更加细粒度的可在亚像素级别上进行ROI特征提取的ROIAlign层。
一般,我们使用ROIPool来对某个ROI区域进行处理时,当除不尽时会在像素级别上进行近似。比如若ROIPool的kernel size为7x7即我们最终要得到7x7大小的区域特征,而我们的ROI proposal在feature map上提取的窗口大小为16x16。那么我们在进行ROIPool处理时会将16x16的feature map近似划为[16/7] x [16/7]大小的格子出来。这样得到的7x7的区域特征必将会使得原有的信息在像素级别位置上有所偏离。
如果单纯只是检测目标框的话,RoIPool所引入的这种偏离并不会对最终目标框位置或类别结果产生过多影响。但是Mask map的检测却会因像素级别上的错位而导致整个map出现较大错误。为此作者提出了更为细致的ROIAlign来解决ROIPool在除不尽时近似取整所带来的误差问题。
下图为ROIAlign的具体实现,可以看出它是通过将每个ROI Grid内部进行细致的二分插值,在除不尽时拟合出一定数目的像素点来计算最终的pool值。

Mask-RCNN的训练与推理
- Mask-RCNN训练
它生成的每个ROI如果最终与某个Ground truth box的IOU为0.5以上,那么就可视为一个positive box,若小于0.5则为negative box。而Lmask的计算则只在positive box上面进行。
训练时将输入图片按短边保持分辨率不变resize为800的大小。每个mini-batch含2 images/GPU。最终每个image经RPN网络生成出N个候选的ROI,其中正负样本区域的比例保持为1:3(自然在这里作者有使用Hard mining的方法来过滤掉大批量的简单负样本区域,此方法与Faster-RCNN中用到的亦相同)。
以naive Resnet为主干网络时,N为64;以FPN为主干网络时,N为256。作者使用了8个GPUs进行训练,最大iterations数目为160,000。初始lr为0.02,然后随着训练进行,以stepwise的方式递减(通过除10)。因为用的是SGD模型,所以还有weight decay系数为0.0001及momentum factor为0.9。
RPN的anchor box共包含5个尺度及3种分辨率的组合。
- Mask-RCNN推理
推理时,当以naive Resnet为主干网络时,最终产生300个Region proposals;而以FPN为主干时,最终生成1000个Region proposals。在box prediction branch上forward时会作NMS(non-maximum suppression)处理。然后Mask branch会在排名最靠前的100个region proposals上进行forward计算(这样做违背了训练时三分支并行计算的特点,但确实有助于提升inference时的计算性能。)在这些ROI上面,mask分支最终得到K个mask maps / ROI。然后再对由classification分支预测得到的第k个分支进行resize,使它的大小与ROI的大小相符合。最终以0.5为threshold,对mask map作二分值化处理就得到最终的binarized mask map。
Mask-RCNN实验结果
作者尝试使用Mask-RCNN在许多需要在像素级别上定位物体类别的问题。如下为其部分实验结果展示。
- Instance segmentation
与state-of-art instance segmentation模型FCIS++相比,它在处理overlapped 物体时能取得更好结果。

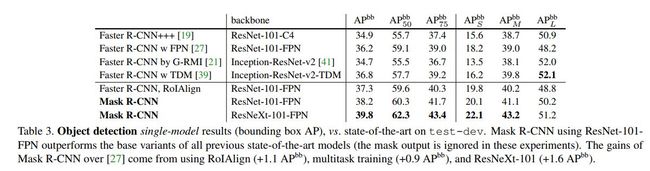
- object detection
- Keypoint detection

代码分析
关于mask branch的设计可见于如下的comment当中。
"""Various network "heads" for predicting masks in Mask R-CNN.
The design is as follows:
... -> RoI ----\
-> RoIFeatureXform -> mask head -> mask output -> loss
... -> Feature /
Map
The mask head produces a feature representation of the RoI for the purpose
of mask prediction. The mask output module converts the feature representation
into real-valued (soft) masks.
"""
以下为基于caffe2 API的Mask R-CNN的network head及Lmask loss的实现。
# ---------------------------------------------------------------------------- #
# Mask R-CNN outputs and losses
# ---------------------------------------------------------------------------- #
def add_mask_rcnn_outputs(model, blob_in, dim):
"""Add Mask R-CNN specific outputs: either mask logits or probs."""
num_cls = cfg.MODEL.NUM_CLASSES if cfg.MRCNN.CLS_SPECIFIC_MASK else 1
if cfg.MRCNN.USE_FC_OUTPUT:
# Predict masks with a fully connected layer (ignore 'fcn' in the blob
# name)
blob_out = model.FC(
blob_in,
'mask_fcn_logits',
dim,
num_cls * cfg.MRCNN.RESOLUTION**2,
weight_init=gauss_fill(0.001),
bias_init=const_fill(0.0)
)
else:
# Predict mask using Conv
# Use GaussianFill for class-agnostic mask prediction; fills based on
# fan-in can be too large in this case and cause divergence
fill = (
cfg.MRCNN.CONV_INIT
if cfg.MRCNN.CLS_SPECIFIC_MASK else 'GaussianFill'
)
blob_out = model.Conv(
blob_in,
'mask_fcn_logits',
dim,
num_cls,
kernel=1,
pad=0,
stride=1,
weight_init=(fill, {'std': 0.001}),
bias_init=const_fill(0.0)
)
if cfg.MRCNN.UPSAMPLE_RATIO > 1:
blob_out = model.BilinearInterpolation(
'mask_fcn_logits', 'mask_fcn_logits_up', num_cls, num_cls,
cfg.MRCNN.UPSAMPLE_RATIO
)
if not model.train: # == if test
blob_out = model.net.Sigmoid(blob_out, 'mask_fcn_probs')
return blob_out
def add_mask_rcnn_losses(model, blob_mask):
"""Add Mask R-CNN specific losses."""
loss_mask = model.net.SigmoidCrossEntropyLoss(
[blob_mask, 'masks_int32'],
'loss_mask',
scale=model.GetLossScale() * cfg.MRCNN.WEIGHT_LOSS_MASK
)
loss_gradients = blob_utils.get_loss_gradients(model, [loss_mask])
model.AddLosses('loss_mask')
return loss_gradients
以下为宏观上在backend网络之后添加network mask head的代码:
def add_ResNet_roi_conv5_head_for_masks(model, blob_in, dim_in, spatial_scale):
"""Add a ResNet "conv5" / "stage5" head for predicting masks."""
model.RoIFeatureTransform(
blob_in,
blob_out='_[mask]_pool5',
blob_rois='mask_rois',
method=cfg.MRCNN.ROI_XFORM_METHOD,
resolution=cfg.MRCNN.ROI_XFORM_RESOLUTION,
sampling_ratio=cfg.MRCNN.ROI_XFORM_SAMPLING_RATIO,
spatial_scale=spatial_scale
)
dilation = cfg.MRCNN.DILATION
stride_init = int(cfg.MRCNN.ROI_XFORM_RESOLUTION / 7) # by default: 2
s, dim_in = ResNet.add_stage(
model,
'_[mask]_res5',
'_[mask]_pool5',
3,
dim_in,
2048,
512,
dilation,
stride_init=stride_init
)
return s, 2048
关于ROIAlign的实现,已经在caffe2中作为base operator得到了支持,我们可调用如下API来完成ROIAlign的功能添加。
model.RoIFeatureTransform(
blob_in,
blob_out='_[mask]_pool5',
blob_rois='mask_rois',
method=cfg.MRCNN.ROI_XFORM_METHOD,
resolution=cfg.MRCNN.ROI_XFORM_RESOLUTION,
sampling_ratio=cfg.MRCNN.ROI_XFORM_SAMPLING_RATIO,
spatial_scale=spatial_scale
)
参考文献
- Mask R-CNN, Kaiming He, 2018
- https://github.com/facebookresearch/Detectron