通常决定一个机器学习模型能不能取得好的效果,以下三个方面的因素缺一不可。
1. 理论模型 (站在 vc-dimension 的角度)
2. 实际数据
3. 系统的实现 (主要基于 xgboost:基于C++通过多线程实现了回归树的并行构建)
--------------------------------------------------------------------------------
(1)站在理论模型的角度
我们可以假设有一个“上帝函数” hypothesis可以完美的拟合所有数据(包括训练数据,以及未知的测试数据)。但这个函数我们肯定是不知道的 (不然就不需要机器学习了)。我们只可能选择一个 “假想函数” 来 逼近 这个 “上帝函数”
一个机器学习模型想要取得好的效果,这个模型需要满足以下两个条件:
1. 模型在我们的训练数据上的表现要不错:也就是trainning error 要足够小。
2. 模型的 vc-dimension 要低。换句话说,就是模型的自由度不能太大,以防overfit.(vc dimension的值越大,参数的个数越多,模型越复杂)
http://www.thebigdata.cn/JiShuBoKe/14027.html
那么这么多算法中,选择依据是“模型的可控性”。
1.对于 LR 这样的模型。如果 underfit,我们可以通过加 feature,或者通过高次的特征转换来使得我们的模型在训练数据上取得足够高的正确率。而对于 tree-enseble 来说,我们解决这一问题的方法是通过训练更多的 “弱弱” 的 tree. 所以,这两类模型都可以把 training error 做的足够低,也就是说模型的表达能力都是足够的。
2.在 tree-ensemble 模型中,通过加 tree 的方式,对于模型的 vc-dimension 的改变是比较小的。而在 LR 中,初始的维数设定,或者说特征的高次转换对于 vc-dimension 的影响都是更大的。所以,一不小心我们设定的多项式维数高了,模型就 “刹不住车了”。俗话说的好,步子大了,总会扯着蛋。这也就是我们之前说的,tree-ensemble 模型的可控性更好,也即更不容易 overfit.
----------------------------------------------------------------------------
(2)站在数据的角度
1.kaggle 比赛选择的都是真实世界中的问题。所以数据多多少少都是有噪音的。而基于树的算法通常抗噪能力更强。
2.除了数据噪音之外,feature 的多样性也是 tree-ensemble 模型能够取得更好效果的原因之一。特征的多样性也正是为什么工业界很少去使用 svm 的一个重要原因之一(因为会 过拟合overfitting),因为 svm 本质上是属于一个几何模型,这个模型需要去定义 instance 之间的 kernel 或者 similarity。
噪声问题:学习了天鹅的外形(全局特征)之后,你的例子都是白色的。计算机看见黑天鹅就认为不是天鹅。(黑色只是局部特征)
过拟合:把学习太彻底了,所有样本都学了,包括局部特征,所以识别新样本没有几个是对的。
解决方法:不要那么彻底,降低机器学习局部特征和错误特征机率。收集多样化样本,简化模型,交叉验证。
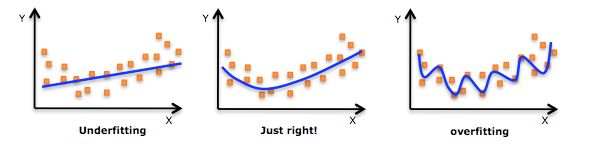
overfitting:http://www.qbiao.com/25555.html
--------------------------------------------------------------------------------------
(3)站在系统实现的角度
除了有合适的模型和数据,一个良好的机器学习系统实现往往也是算法最终能否取得好的效果的关键。一个好的机器学习系统实现应该具备以下特征:
1. 正确高效的实现某种模型。我真的见过有些机器学习的库实现某种算法是错误的。而高效的实现意味着可以快速验证不同的模型和参数。
xgboost 高效的 c++ 实现能够通常能够比其它机器学习库更快的完成训练任务。
2. 系统具有灵活、深度的定制功能。
在灵活性方面,xgboost 可以深度定制每一个子分类器,并且可以灵活的选择 loss function(logistic,linear,softmax 等等)。
3. 系统简单易用。
xgboost 提供了各种语言的封装,使得不同语言的用户都可以使用这个优秀的系统。
4. 系统具有可扩展性, 可以从容处理更大的数据。
xgboost 提供了分布式训练(底层采用 rabit 接口),并且其分布式版本可以跑在各种平台之上,例如 mpi, yarn, spark 等等。
机器学习算法中GBDT和XGBOOST的区别有哪些?
xgboost能自动利用cpu的多线程,而且适当改进了gradient boosting,加了剪枝,控制了模型的复杂程度
陈天奇大神的文章和slides
- 传统GBDT以CART作为基分类器,xgboost还支持线性分类器,这个时候xgboost相当于带L1和L2正则化项的逻辑斯蒂回归(分类问题)或者线性回归(回归问题)。
- 传统GBDT在优化时只用到一阶导数信息,xgboost则对代价函数进行了二阶泰勒展开,同时用到了一阶和二阶导数。顺便提一下,xgboost工具支持自定义代价函数,只要函数可一阶和二阶求导。
- xgboost在代价函数里加入了正则项,用于控制模型的复杂度。正则项里包含了树的叶子节点个数、每个叶子节点上输出的score的L2模的平方和。从Bias-variance tradeoff角度来讲,正则项降低了模型的variance,使学习出来的模型更加简单,防止过拟合,这也是xgboost优于传统GBDT的一个特性。
- Shrinkage(缩减),相当于学习速率(xgboost中的eta)。xgboost在进行完一次迭代后,会将叶子节点的权重乘上该系数,主要是为了削弱每棵树的影响,让后面有更大的学习空间。实际应用中,一般把eta设置得小一点,然后迭代次数设置得大一点。(补充:传统GBDT的实现也有学习速率)
- 列抽样(column subsampling)。xgboost借鉴了随机森林的做法,支持列抽样,不仅能降低过拟合,还能减少计算,这也是xgboost异于传统gbdt的一个特性。
- 对缺失值的处理。对于特征的值有缺失的样本,xgboost可以自动学习出它的分裂方向。
- xgboost工具支持并行。boosting不是一种串行的结构吗?怎么并行的?注意xgboost的并行不是tree粒度的并行,xgboost也是一次迭代完才能进行下一次迭代的(第t次迭代的代价函数里包含了前面t-1次迭代的预测值)。xgboost的并行是在特征粒度上的。我们知道,决策树的学习最耗时的一个步骤就是对特征的值进行排序(因为要确定最佳分割点),xgboost在训练之前,预先对数据进行了排序,然后保存为block结构,后面的迭代中重复地使用这个结构,大大减小计算量。这个block结构也使得并行成为了可能,在进行节点的分裂时,需要计算每个特征的增益,最终选增益最大的那个特征去做分裂,那么各个特征的增益计算就可以开多线程进行。
- 可并行的近似直方图算法。树节点在进行分裂时,我们需要计算每个特征的每个分割点对应的增益,即用贪心法枚举所有可能的分割点。当数据无法一次载入内存或者在分布式情况下,贪心算法效率就会变得很低,所以xgboost还提出了一种可并行的近似直方图算法,用于高效地生成候选的分割点。
树集成方法中 随机森林和XGboost之间有什么区别?
先得了解一下回归树和树集成的概念
判断用户是否会喜欢电脑游戏的回归树模型,每个树叶的得分对应了该用户有多可能喜欢电脑游戏(分值越高可能性越大)。
上图中的回归树只用到了用户年龄和性别两个信息,过于简单,预测的准确性自然有限。在图2中使用2个回归树对用户是否喜爱电脑游戏进行了预测,并将两个回归树的预测结果加和得到单个用户的预测结果。
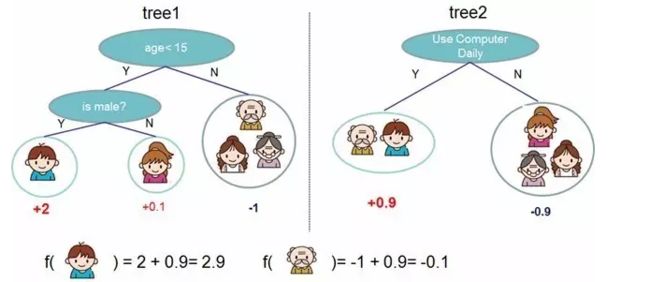
在实际的预测模型建立过程中,我们通过不断的增加新的回归树,并给每个回归树赋予合适的权重,在此基础上综合不同的回归树得分获得更为准确的预测结果,这也就是树集成(tree ensemble)的基本思路。
Random Forest和Boosted Trees都采用了树集成的方法,但是在具体的模型构造和参数调整的方法有所差别。
XGBoost的建模思路:就是在每轮迭代中生成一棵新的回归树,并综合所有回归树的结果,使预测值越来越逼近真实值。
如何评判预测值与真实值的差距,并避免过拟合的存在呢?我们首先给出了一个泛化的目标函数的定义,在此基础上针对XGBoost提供了相应的数学表达式,并进行了泰勒二阶展开。接下来,我们所需要做的工作就是在每一轮迭代中找到一棵合适的回归树,从而使得目标函数进一步最小化;
通过树结构q和树叶权重w来描述一棵回归树。将树叶权重带入目标函数后,发现一旦树结构q确定了,目标函数能够唯一确定。所以模型构建问题最后转化为:找到一个合理的回归树结构q,使得它具有最小的目标函数。对于这个问题,XGBoost提供了贪心算法来枚举所有可能的树结构并找到最优的那个。
https://mp.weixin.qq.com/s?__biz=MzIyNjE2Nzk2Mw==&mid=2649623429&idx=1&sn=0793d85ccd73c833abec9415a6261946&chksm=f06e3671c719bf67243505bb2fb1ec8d42e4c8b7b147b84b4aa513ea67735ba9cc8fc85d48a1&mpshare=1&scene=24&srcid=0417H4688iWa3unwz16zuZtI&key=0ee500f7354eb2512f4daaf224829ec5fb4c008d4f22a6490f2efdc7025cf514993b45fa62ca69c4c1df114ed6556ba51aa9c53ec2ede33eab2f440de223ea9a1c22262f395afb0d63b7642a703f6f08&ascene=0&uin=NDUxNjE0Nzk1&devicetype=iMac+MacBookPro13%2C2+OSX+OSX+10.12.5+build(16F73)&version=12020610&nettype=WIFI&fontScale=100&pass_ticket=I1hRPTiOiFMMD1JdlCoGWgIwrIbvsbzf3pVenH58NngAUM48xsibcX%2BnCjbYv%2F9b
http://blog.csdn.net/a819825294/article/details/51206410