本篇目的:
- c/c++中如何判断大小端的函数
- c/c++中通过指针法,移位法获取多字节数据类型中的各个字节
- java/c#/js中如何获取多字节数据类型中的各个字节
- 什么是装箱和拆箱
- 为什么要装箱拆箱
- java js c# objc中尽可能的避免装箱拆箱的方法
- 顺便介绍js一些新的内置类(有些还处于实验性质)
- 介绍一些simd相关知识
用c/c++实现测试大小端的函数:
bool isLittleEdian() {
union {
unsigned int a;
unsigned char b[4];
}U;
U.a = 1;
if (U.b[0] == 1)
return true;
else
return false;
}
- 使用union关键来声明一个联合数据类型,它可以实现:以一种数据类型存储数据,以另一种数据类型来读取数据。
例如我们用unsigned int a来进行赋值,却使用unsgined char b[idx]数组索引来读取某个unsigned char的数值
- c/c++中,内存是根据变量的顺序来分配的,从低到高。
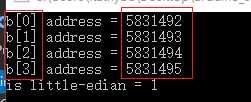
因此unsigned char b[4]在内存中从低到高【左->右】的分布是:
【b[0],b[1],b[2],b[3]】
闲聊c/c++: 谈内存(大/小端,高/低字节,高/低地址)的结论:
- 在小端模式中,数据的高字节保存在内存的高地址中,而数据的低字节保存在内存的低地址中
当我们U.a = 1赋值时, 1 < 255,因此属于最低字节,其值保存在最低地址中(也就是b[0]的地址5831492所指向的byte中)。
因为: 低字节保存在内存的低地址
所以: b[0] = 1
- 在大端模式中,数据的高字节保存在内存的低地址中,而数据的低字节保存在内存的高地址中
因为: 低字节保存在内存的高地址(5831495,指向的是b[3]所在的byte)
所以: b[3] = 1
应该很清楚明了的吧!
关键点:高低字节、高低地址!!!!
除了union外,c/c++中还有多种方式从unsigned int 中获取某个unsigned char的数值:
指针法:
//指针法
void printUInt4ComponentByPointer(unsigned int n) {
unsigned char* ptr = (unsigned char*)(&n);
unsigned char char0 = *ptr; //最低地址
unsigned char char1 = *(ptr + 1); //指针移动方式
unsigned char char2 = ptr[2]; //使用[]变址操作符
unsigned char char3 = ptr[3]; //使用[]变址操作符,最高地址
printf("[%u,%u,%u,%u]\n",char3,char2,char1,char0);
}
移位法:
void printUInt4ComponentByShift(unsigned int n) {
unsigned char bytes[4];
bytes[0] = (n >> 24) & 0xFF;
bytes[1] = (n >> 16) & 0xFF;
bytes[2] = (n >> 8) & 0xFF;
bytes[3] = n & 0xFF;
printf("[%u,%u,%u,%u]\n", bytes[0], bytes[1], bytes[2], bytes[3]);
}
//测试:
printUInt4ComponentByPointer(257);
printUInt4ComponentByShift(257);
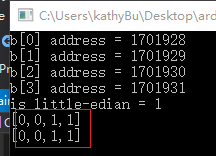
在java,c#(事实上c#在unsafe{}中支持指针操作的),js等这些语言支持移位操作,只能使用移位法进行分量的提取操作(或许每个语言类库有提供相关操作,请自己查api文档)
public class Main {
static void printUInt4ComponentByShift( int n) {
byte[] bytes = new byte[4];
bytes[0] = (byte)((n >> 24) & 0xFF);
bytes[1] = (byte)((n >> 16) & 0xFF);
bytes[2] = (byte)((n >> 8) & 0xFF);
bytes[3] = (byte)(n & 0xFF);
System.out.printf("[%d,%d,%d,%d]\n",bytes[0],bytes[1],bytes[2],bytes[3]);
}
public static void main(String[] args) {
printUInt4ComponentByShift(257);//[0,0,1,1]
}
}
- 用java举例子,其他语言都一样(上面代码稍作修改,用于c#,js,...等语言具有同等效果)
- java中char是2个字节,表示一个utf16字符。byte才是一个字节,是值类型
- 大写的Byte是引用类型,用于容器存储时的装箱使用。自jdk1.5开始引入自动装箱拆箱。
- 事实上,java中,所有的基本数据类型都有对应的首字母大写的同名的类,例如char->Char/byte->Byte.........,就是为了装箱拆箱使用
装箱(boxing)与拆箱(unboxing)
1. 什么是装箱拆箱:
装箱: 将值类型转换为引用类型
拆箱: 将引用类型转换为值类型
Integer i = 100; //装箱
int j = i; //拆箱
用java代码来分析一下:
因为Integer是引用类型,而100字面量是一个数值类型
将一个数值类型赋值给引用类型时,就发生了装箱这段代码只能在jdk1.5以后使用,因为这是自动装箱拆箱
如果在jdk1.5之前,只能使用 Integer i = new Integer(100)以及int j = i.intValue()
-
装箱的流程如下:
首先: 因为100是数值类型,因此内存是分配在栈内
然后: 使用new 操作符,查询整个堆,是否有连续的,可以分配sizeof(Integer)的内存块,如果有,则返回Integer的首地址,如果没有连续容纳的内存块,就需要不停的往下查找,直到找到连续内存块才返回,否则就报out of memory错误
最后: 将栈上分配的100赋值给堆分配的Integer中的成员变量,完成装箱工作
拆箱的流程正好和装箱相反
由此可见,装箱拆箱涉及到堆和栈的内存分配,内存拷贝以及内存析构,是一个很耗时的操作!
一次的装箱拆箱不可怕,可怕的是成千上万的数据需要拆箱装箱。例如java容器类,装填的是Object,因此每次add基本数据类型时候,需要装箱,每次get(i)基本数据类型时,需要拆箱,当每次你循环成千上万个数据时,进行成千上万次的装箱或拆箱行为。js,objc也是如此,c#比较特别,我们下面来说明!
2. 为什么要装箱拆箱:
原因: 统一类型系统
来自.net本质论的解释:
装箱与拆箱是我们能够统一的来考察类型系统,其中任何类型的值都可以按对象处理
- java中所有的类都继承自Object
- .net中,公共语言运行库中的类都继承自Object
- objc中,所有的类都继承自NSObject
- js中,所有一切都是object
所以不可避免的,这些语言都会产生装箱和拆箱行为,这是由其本质所决定的!!!!
对于c#来说,比较特别。在c#2.0之前,和java一样,需要装箱和拆箱。但是c#2.0引入了泛型机制,而且c#本身支持struct定义值类型,class定义引用类型,这些机制可以避免装箱拆箱。因此在c#中,现在肯定都是用泛型容器类。
c#非泛型容器类则只能存储object类型,和java一样会自动进行装箱拆箱工作。(其实可以查看java/.net中间语言代码,就会非常清晰的了解整个机制和流程)
随便说一下,java的泛型系统到目前为止还是所谓的"擦除式"泛型系统,也就是在编写的时候,是用泛型的方式写代码,但实际在生成字节码运行时的时候,泛型表示全部变为object类型表示,因此也是无法消除装箱拆箱的行为。
为什么java会如此,很简单,为了兼容性,Java虚拟机使用广泛,而装箱拆箱需要重写底层机制,导致不兼容性!!
.net是看到了java的不良之处,从一开始设计时候就考虑好了,在.net 2.0之前虽然没支持泛型,但是struct/class可是一开始就已经拥有了!
3. 如何避免装箱拆箱?
- c#中直接使用泛型类
- objc中.m支持c语言,.mm支持c++,所以实在要追求效率,就使用c语言或c++ stl库,clang还是非常棒的东西!!facebook pop即使这么干的,很棒的库,对吧!
- java中,觉得好像没什么可能性了,即使用ndk,除非你全部使用ndk编写,否则即使jni导出给java使用,也面临这c++数据类型到java数据类型的包装。所以并不合算
- 来聊一下js吧,js一定会成为王者之剑。现在的js中增加了很多基本数据类型的Array内置对象:
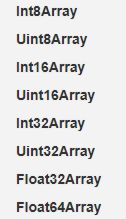
没验证过,但是90%的可能不会产生装箱和拆箱行为!
simd-单指令多数据流指令集,游戏中的必备技术。16byte字节对齐(续谈内存,我们来聊字节对齐和padding),特适合3D数学表示。(关于simd方面的参考资料,最好的就是id soft(发表在intel的5篇论文,详细描述了Doom3中simd数学库的性能优化及测试,约翰卡马克就是3D引擎之神,几年前Doom3已经开源了,可以在github中下载到,simd数学库可以参考:Doom3 数学库以及微软的XNA Math库,也是Simd实现)
还有就是增加了红黑色之类的数据结构。由此可见,js所图宏大啊!一定要跟踪js的发展!
今天到此为止,下一篇我们聊一下nodejs的核心库libuv中的几个核心宏,你会看到那是多么的美妙!

非常有深度,信息量巨大的一本书!!
.Net 本质论作者: Don Box: 也是COM本质论的作者
"关于COM,没有任何人能阐释得比Don Box更棒!"
这是微软"COM guy" Charlie Kindel对Don Box的评价!
.net以前被称为"COM+"
ID soft发布在intel上的论文,一共7篇,详细的测试,实现过程描述,涉及骨骼动画,阴影计算,骨骼动画流水线等等,其实整个3D都是建立在数学基础上的。因此如果想搞图形开发,这几篇论文绝对就是最好的选择!!
https://software.intel.com/en-us/articles/optimizing-the-rendering-pipeline-of-animated-models-using-the-intel-streaming-simd-extensions
我在unity3d中实现了Doom3场景地图的渲染和Doom3 MD5骨骼动画渲染,其实最终目的就是为了js webgl demo(我的闲聊js系列文章),两个无头男人是MD5骨骼动画,一个静态,一个运动,而小美女是著名的她:
