在线工具:微信文章转PDF
抓取程序已开源:wechat_spider
程序原理
准备工作
1. 安装Node.js
去Node.js 官网下载对应操作系统的安装包,然后按照默认步骤安装至电脑中。
下载地址:http://nodejs.cn/download/
安装好之后,打开终端或命令行运行输入下面代码,检查是否安装成功,如果成功,会输出当前Node 版本号。
node -v
2. 安装AnyProxy 代理服务器
命令行或终端输入以下命令,表示全局安装AnyProxy 程序包:
npm install -g anyproxy
如果是Mac 系统,可能需要在命令前添加sudo ,然后输入密码:
sudo npm install -g anyproxy
输入以上命令后,电脑会自动从网络下载程序包并安装。
参考网址:https://github.com/alibaba/anyproxy
3. 启动AnyProxy
终端输入:
anyproxy
Mac 系统需输入(以后的命令也是需要输入sudo ,下面就忽略不写了):
sudo anyproxy
如出现下面提示,则表明安装成功:
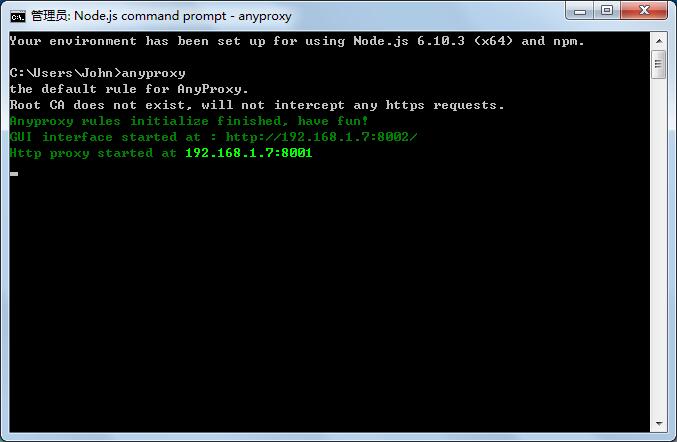
4. 安装HTTPS 网络传输所需的证书
电脑安装
微信采用加密的HTTPS 网络传输,所以需要安装证书。结束上面的运行程序,一般为ctrl + c 。然后在终端运行命令:
anyproxy --root
此时会在文件夹生成rootCA.crt 证书与对应的密钥rootCA.key,根据提示打开对应文件夹,双击安装rootCA.crt 证书。
手机安装
电脑命令行或终端输入anyproxy 命令启动代理程序,然后浏览器中输入网址http://localhost:8002/qr_root,则会出现证书二维码,然后手机扫描此证书二维码,下载按照提示完成安装即可。
参考网址1:https://github.com/alibaba/anyproxy/wiki/HTTPS%E7%9B%B8%E5%85%B3%E6%95%99%E7%A8%8B
参考网址2:http://anyproxy.io/cn.html#配置帮助
安装mysql 模块部分
默认你的电脑上已经安装了mysql 数据库,现在node 连接mysql 数据库,也需要安装一个程序包来实现:
npm install -g mysql
程序部分
程序地址
windows 程序AnyProxy 默认的安装目录在:C:\Users\你的用户名\AppData\Roaming\npm\node_modules\anyproxy
Mac 安装目录为:/usr/local/lib/node_modules/anyproxy
本程序为修改和增加AnyProxy 中lib 文件中对应的代码部分。
我的代码部分
我会发送给你下面5个文件,你只需覆盖掉lib 目录中对应的文件即可。(建议先备份)
./anyproxy
./lib
myRule.js
rule_default.js
1.png
requestHandler.js
httpsServerMgr.js
- 其中逻辑部分主要写在
myRule.js文件中,此文件已做了详细的注释 -
rule_default.js是判断各种网络请求数据然后调用对应的方法 -
1.png为很小的一个图片,替换手机所有图片请求,加快网络传输速度 - 其余两个文件是注释掉了之前在终端打印的一些提示性的字符,不重要
运行程序部分
anyproxy -i
终端输入以上命令即可运行。参数-i 表示开启HTTPS 。
可操作myRule.js 文件,选择对应的功能。修改文件后,需重启程序。
运行后,确保电脑和手机在同一个WiFi 环境下,然后根据提示设置手机WiFi 的代理,输入代理网址与端口(运行后终端会提示连接地址)。
之后选择查看公众号文章,即可自动抓取数据至数据库中。
myRule.js 代码主要部分
三个主要函数:
getProfile - 对历史页的操作,获取文章其他数据;插入自动翻页代码
getReadAndLikeNum - 获取文章点赞、阅读、打赏等数据
insertJsForRefresh - 对文章页的操作,主要是插入自动翻页代码
代码原理
此程序为事件驱动。即一开始要给定一个触发事件,例如打开历史详情页或打开某篇文章。
微信打开历史详情页之后会触发事件,运行getProfile 函数,跳至下一个历史详情页后又会触发打开历史详情页此事件。
同理,微信打开文章页会触发事件运行insertJsForRefresh 函数,此函数会向网页中插入一段脚本自动翻页,当翻页后,又会触发此事件,然后一直运行下去。同时,打开文章页时,微信会请求另一个链接,然后会自动触发getReadAndLikeNum 函数。
历史详情页有4种插入js 代码的方式,已在代码中注释。
Js 注入详解
文章页自动翻页原理为在网页head 部分插入类似以下形式代码,表示隔5s 跳转至下一个文章页
历史详情页注入Js 脚本示例,将以下脚本插入至返回给微信客户端的数据中,可以使网页自动下拉至最低端,到最早一篇文章之后再跳转至下一个历史消息详情页:
我在代码部分写了4个这样类似的脚本,用于实现不同情况下特定的功能。你可在运行时作出选择。
数据库部分
myRule.js 文件开头会有数据库连接,对应修改成自己的数据库配置。
// 创建数据库连接,需根据自己数据库账号密码修改
var connection = mysql.createConnection({
host: 'localhost',
user: 'root',
password: '0000',
database: 'phone_weixin'
});
数据库中有4张表,分别对应文章信息,历史消息抓取记录和公众号信息。
msg
history
mpaccout
content
表的结构也在发你的文件中。在mysql 数据库中新建好即可。
数据库字段解释
msg.sql
id - 文章id,自动递增
msg_title - 文章标题
msg_link - 文章永久链接
publish_time - 文章发布时间,13位时间戳形式
modi_time - 数据抓取时间,13位时间戳形式
read_num - 阅读量
like_num - 点赞量
reward_total_count - 安卓手机赞赏量
msg_idx - 文章发布位置,首条、二条等等
msg_biz - 公众号唯一标识,重要
msg_source_url - 文章阅读原文链接,若无则空
msg_cover - 文章封面图片链接
msg_digest - 文章摘要
is_fail - 文章是否删除,如果删除改为1,下次就不在抓取
copyright_stat - 文章是否原创标识 11为原创 100为无原创 101为转发
author - 文章作者
mpaccount.sql
id - 公众号id,自动递增
biz - 公众号唯一标识
nickname - 公众号名称
metavalue - 公众号id
history.sql
id - 公众号id,自动递增
biz - 公众号唯一标识
url - 上次抓取的链接
moditime - 上次抓取时间