ML是什么?
。。。别想歪。。。你好污。。。
ML是Machine Learning的缩写,也就是‘机器学习’,这正是现在很火的一个技术,它也是人工智能最核心的内容。比如说横扫世界棋坛大名鼎鼎的阿尔法狗(AlphaGo),或者已经深入大家生活场景的车牌识别,这其实都是机器学习的具体实际应用的结果。
‘机器学习’就是一种能让计算机不需要不断被人工显示编程而能自己学习的人工智能技术,它不是通过具体的编码算法,而是在大量的模型数据中找到一个合适的模式从而让计算机能够不断的发展和完善自身算法。
这个技术所要模拟的就是一个庞大而复杂的‘神经网络’,这个'神经网络'就需要大量的训练好的模型(model)来提供数据,使得这个'神经网络'能对各种输入(inputs)产生出一个对应的输出结果(outputs),并且还能通过不断的训练数据来提高自己的算法准确性。
这里的核心其实就是训练各种模型(model)来处理各种不同的情况和需求。比如说有了一个专门识别人脸的模型,给一个输入图片他就能把人脸位置输出出来等等等等。。。。最后如果将无限多的训练好的模型都结合起来,那这个计算机可能就能像人一样应对各种情况还能不断地自我完善。
iOS11让我们能做什么?
上面说的看起来好像很复杂,其实。。。他真的很复杂
不过别担心,复杂的是训练模型,而我们要做的只是使用一些训练好的模型来实现一些实际的需求。
苹果新系统iOS11多了几个新的开发库,其中最核心的就是CoreML这个库:官方文档地址
根据官方文档里的这张图就可以看出,其实它的作用就是将一个ML模型,转换成我们的app工程可以直接使用的对象
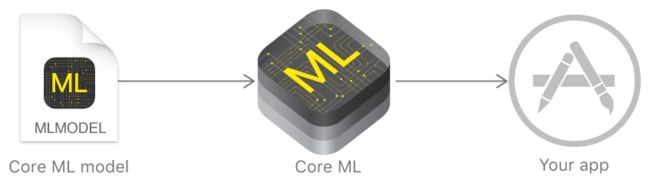
所以不要担心,使用它是很简单的事情
除了CoreML,iOS11新出还有一个库是很有用的,叫做Vision:官方文档地址
这个库是一个高性能的图片分析库,他能识别在图片和视频中的人脸、特征、场景分类等
你如果打开Vision的官方文档看,官方对他包含的所有类做了分类,比如有Face Detection and Recognition(人脸检测识别)、Machine Learning Image Analysis(机器学习图片分析)、Barcode Detection(条形码检测)、Text Detection(文本检测)。。。。。等等等等
所以你可以这样理解:Vision库里就已经自带了很多训练好的模型,这些模型是针对上面提到的人脸识别、条形码检测等等功能,如果你要实现的功能刚好是Vision库本身就能实现的,那么你直接使用Vision库自带的一些类和方法就行,也就没有CoreML什么事了。
那么什么时候Vision才需要CoreML呢?就是当你要使用一个你在网上找的训练好的模型或者你自己训练好的模型的时候,才需要CoreML来将这个相当于‘第三方’模型转换成app认得的类,然后结合上面提到的Vision的Machine Learning Image Analysis(机器学习图片分析)分类下的类和方法来使用这个模型进行图形分析。
CoreML也可以看做一个模型的转换器,可以将一个MLModel格式的模型文件自动生成一些类和方法,可以直接使用这些类去做分析,让你更简单是在app使用训练好的模型。
Vision本身就是能对图片视频做分析的一个库,他自带了针对很多特征检测的功能,而他也能使用一个你设置好的MLModel来对图片做分析。可以说在针对一些图片分析的需求情况下,使用Vision结合CoreML的方法会比直接使用CoreML更加直观,它应该是做了一点封装
所以对于我们下面要说的例子,会给出两种做法,一种就是只使用CoreML,一种是使用CoreML + Vision
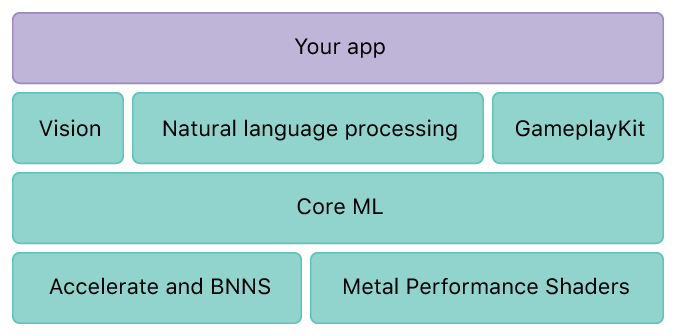
PS:其实上面说的有些不太准确,因为Vision就是建立在CoreML层之上的,你使用Vision其实还是用到了CoreML,所以不可能没有CoreML的事。只是你可能没有显式地直接写CoreML的代码而已。看下面这张官方给的图你就应该明白了
工程实例讲解
因为CoreML和Vision都是iOS11才有的功能,所以你要确保你有一台装了iOS11 beta版本的手机,还有一个beta版本的Xcode9:下载地址
开发语言我们使用Swift,Xcode9应该是用的Swift4了
1.模型文件下载
我们要做的demo例子就是使用一个下载的模型来识别图像的场景,他能告诉我们这个图片是海边,还船舶或者森林等等。
可以先去苹果官方下载一个已经训练好的模型,叫 Places205-GoogLeNet:下载地址
这个模型是可以从图片里识别出205不同的场景。
进入这个网址滚到下面就能找到,你还可以看到他还有另外几个模型,每个模型都有它的描述和大小,我们挑这个Places205-GoogLeNet模型稍微小一点的(24.5M),下载完会得到一个GoogLeNetPlaces.mlmodel文件,一会我就要使用它。
2.创建工程和引入模型
我们先打开Xcode,创建一个Single View模板的工程,然后将上面我们下载的那个GoogLeNetPlaces.mlmodel模型文件拖入工程

我们再工程里单击一下GoogLeNetPlaces.mlmodel这个文件,然后右边就会显示出这个文件的信息如下图
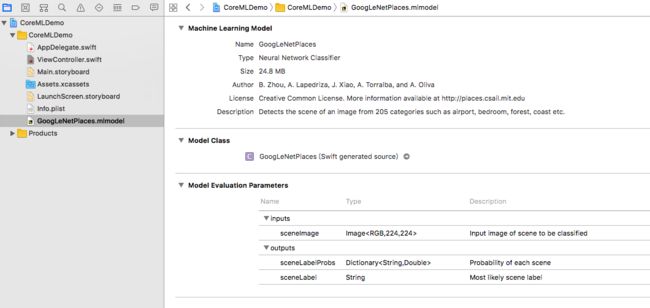
我们先看右边最下面那一栏Model Evaluation Parameters
可以看出这个模型需要的input是一个图片,大小是224*224。
ouput会有两个参数一个参数叫sceneLabelProbs是一个[string:Double]的字典数组,数组里每一个字典就是这个输入图片分析得出可能的一个结果,string就是对图片类型的描述,而double就是可能性百分比。另一个sceneLabel就是最有可能的一个一个结果描述
然后我们再看到右边中间那一栏Model Class,下面有有一个GoogLeNetPlaces(Swift generated source),看到右边有一个小箭头么?刚开是可能你还看不到这个小箭头,因为这个时候Xcode正在给这个模型自动生成他的类和方法,等你看到这个小箭头了就可以点击一下这个箭头,就会进入这个模型自动生成的类的文件里,可以看到这个模型会有三个类:
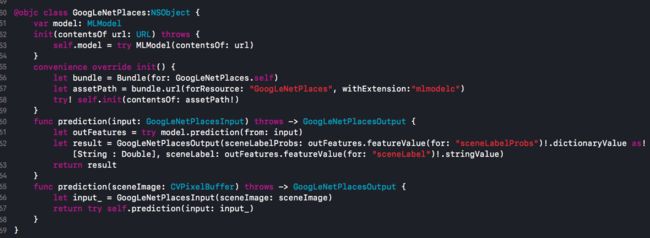
类GoogLeNetPlacesInput: 输入源,可以看到验证了我们上面说的他就是需要一个CVPixelBuffer格式的图片作为输入

类GoogLeNetPlacesOutput:可以看到输出的两个参数sceneLabel和sceneLabelProbs正式我们上面有介绍过的所有可能的结果数组与最有可能的结果描述
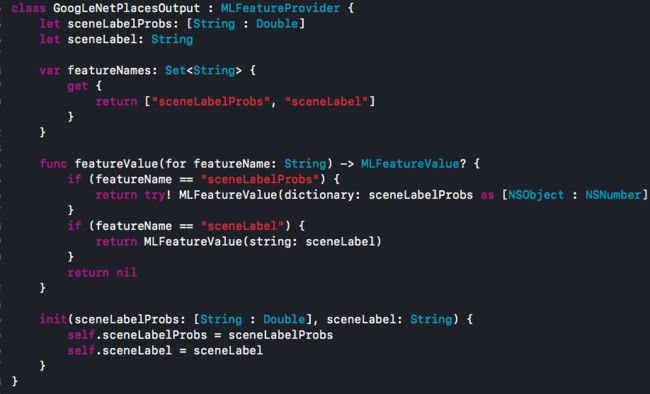
类GoogLeNetPlaces:如果单纯使用CoreML的话,那就是调用这个类的Prediction方法来开始进行分析。如果是使用CoreML+Vision的话,就是使用这个类的model: MLModel属性来创建Vision的分析request,稍后会做介绍
3.编写准备代码
接下来我们去到Storyboard来创建几个要用的控件,因为这是个小demo,我就直接用Storyboard了,平时我还是习惯用纯代码的
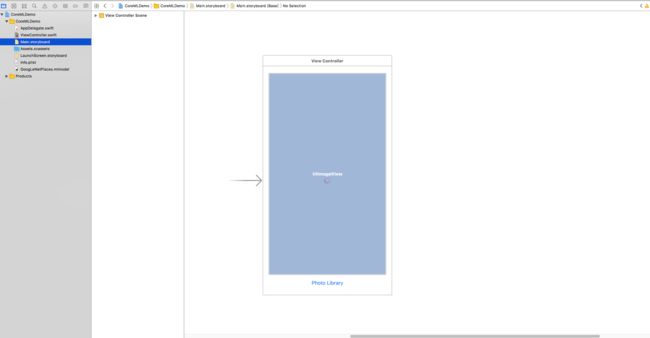
可以看到我们就加了三个控件
imageView:用来显示等会我们从相册选取的图片
button: 底部有一个叫做Photo Library的按钮,点击它我们就弹出相册图片选择界面
indicator:屏幕中间放了个用来显示转圈的indicator,用来在图片分析等待的时候显示,记得勾选他的hides When Stopped属性
然后我们就直接去到ViewController文件给我们的控制器添加三个属性,然后将这三个属性跟我们的空间链接起来
@IBOutlet weak var button: UIButton!
@IBOutlet weak var imageView: UIImageView!
@IBOutlet weak var indicator: UIActivityIndicatorView!
然后给我们的button创建一个buttonClick方法,记得把这个方法跟button空间的touchUpInside链接起来
@IBAction func buttonClick(_ sender: UIButton) {
let picker = UIImagePickerController()
picker.delegate = self
picker.sourceType = .photoLibrary
present(picker, animated: true, completion: nil)
}
可以看到我们在点击按钮的方法里先创建了一个ImagePicker,然后将delegate设置为当前控制器,再设置我们要从手机相册选取图片而不是相机,最后将这个ImagePicker显示出来。
因为我们的控制器成为了图片选择器的代理,所以现在让我们的ViewController再遵守下面两个协议
UIImagePickerControllerDelegate, UINavigationControllerDelegate
然后给ViewController加上下面这个协议方法实现
func imagePickerController(_ picker: UIImagePickerController, didFinishPickingMediaWithInfo info: [String : Any]) {
if let image = info["UIImagePickerControllerOriginalImage"] as? UIImage {
imageView.image = image
}
picker.dismiss(animated: true, completion: nil)
}
可以看到我们将取到的图片显示到我们的imageView里面了
这个时候运行程序就能看到下面的样子了(注意你手机相册要有照片喔)
现在我们基本就准备好了基本的工程,现在能从相册选择图片并且拿到这个图片UIImage类型的对象了。接下来再添加一个下面一个辅助的方法到ViewController我们就正式开始我们的图片分析
func showAnalysisResultOnMainQueue(with message: String) {
//回到主线程上
DispatchQueue.main.async {
//创建alert
let alert = UIAlertController(title: "Completed", message: message, preferredStyle: .alert)
let cancelAct = UIAlertAction(title: "Cancel", style: .cancel, handler: nil)
alert.addAction(cancelAct)
self.present(alert, animated: true) {
//点击取消后允许用户操作
self.indicator.stopAnimating()
self.view.isUserInteractionEnabled = true
}
}
}
这个方法就是方便等会对图片分析完成后弹个框显示一下结果用的,因为我们等会的分析方法需要一点点耗时,所以我们会让他在后台线程去分析,完成后再调用这个方法回到主线程来显示提示。
另外再添加一个下面ViewController的extension到ViewController文件里,这个extension里有两个方法,也是我们等会要用到的辅助方法。
这两个方法很长,又是C的方法,你可以不用理解他们具体实现的原理,只要知道一会我们用这个方法是为了将一个UIImage类型的图片对象,转换成一个CVPixelBuffer类型的对象
extension ViewController {
func CreatePixelBufferFromImage(_ image: UIImage) -> CVPixelBuffer?{
let size = image.size
var pxbuffer : CVPixelBuffer?
let pixelBufferPool = createPixelBufferPool(Int32(size.width), Int32(size.height), FourCharCode(kCVPixelFormatType_32BGRA), 2056)
let status = CVPixelBufferPoolCreatePixelBuffer(kCFAllocatorDefault, pixelBufferPool!, &pxbuffer)
guard (status == kCVReturnSuccess) else{
return nil
}
CVPixelBufferLockBaseAddress(pxbuffer!, CVPixelBufferLockFlags(rawValue: 0))
let pxdata = CVPixelBufferGetBaseAddress(pxbuffer!)
let rgbColorSpace = CGColorSpaceCreateDeviceRGB()
let context = CGContext(data: pxdata,
width: Int(size.width),
height: Int(size.height),
bitsPerComponent: 8,
bytesPerRow: CVPixelBufferGetBytesPerRow(pxbuffer!),
space: rgbColorSpace,
bitmapInfo: CGImageAlphaInfo.premultipliedFirst.rawValue)
context?.translateBy(x: 0, y: image.size.height)
context?.scaleBy(x: 1.0, y: -1.0)
UIGraphicsPushContext(context!)
image.draw(in: CGRect(x: 0, y: 0, width: size.width, height: size.height))
UIGraphicsPopContext()
CVPixelBufferUnlockBaseAddress(pxbuffer!, CVPixelBufferLockFlags(rawValue: 0))
return pxbuffer
}
func createPixelBufferPool(_ width: Int32, _ height: Int32, _ pixelFormat: FourCharCode, _ maxBufferCount: Int32) -> CVPixelBufferPool? {
var outputPool: CVPixelBufferPool? = nil
let sourcePixelBufferOptions: NSDictionary = [kCVPixelBufferPixelFormatTypeKey: pixelFormat,
kCVPixelBufferWidthKey: width,
kCVPixelBufferHeightKey: height,
kCVPixelFormatOpenGLESCompatibility: true,
kCVPixelBufferIOSurfacePropertiesKey: NSDictionary()]
let pixelBufferPoolOptions: NSDictionary = [kCVPixelBufferPoolMinimumBufferCountKey: maxBufferCount]
CVPixelBufferPoolCreate(kCFAllocatorDefault, pixelBufferPoolOptions, sourcePixelBufferOptions, &outputPool)
return outputPool
}
}
4.使用纯CoreML进行图片分析
现在就在当前ViewController文件内给ViewController类添加一个extension,我们将分析方法都写在这个extension里,然后添加两个空方法
extension ViewController {
//只使用CoreML方法来分析
func analysisImageWithoutVision(image: UIImage) {
}
//使用CoreML+Vision方法来分析
func analysisImageWithVision(image: UIImage) {
}
}
我们就先只使用CoreML来实现,现在先在analysisImageWithoutVision(image:):方法里加上下面的代码
indicator.startAnimating()
view.isUserInteractionEnabled = false
我们先显示转圈,告诉用户当前在分析中,同时禁用了用户交互
接下来继续添加核心代码到方法里
//---------------- 1--------------------
DispatchQueue.global(qos: .userInteractive).async {
//---------------- 2----------------
let imageWidth:CGFloat = 224.0
let imageHeight:CGFloat = 224.0
UIGraphicsBeginImageContext(CGSize(width:imageWidth, height:imageHeight))
image.draw(in:CGRect(x:0, y:0, width:imageHeight, height:imageHeight))
let resizedImage = UIGraphicsGetImageFromCurrentImageContext()
UIGraphicsEndImageContext()
guard let newImage = resizedImage else {
fatalError("resized Image fail")
}
//---------------- 3----------------
guard let pixelBuffer = self.CreatePixelBufferFromImage(newImage) else {
fatalError("convert PixelBuffer fail")
}
// ----------------4----------------
guard let output = try? GoogLeNetPlaces().prediction(sceneImage: pixelBuffer) else {
fatalError("predict fail")
}
// ----------------5----------------
let result = "\(output.sceneLabel)(\(Int(output.sceneLabelProbs[output.sceneLabel]! * 100))%)"
// ----------------6----------------
self.showAnalysisResultOnMainQueue(with: result)
}
分析处理完成后的流程是这样
1.因为我们要将图片转换为224*224大小,还要将图片转成CVPixelBuffer格式,我们的模型才能对它进行分析,加上分析也比较耗时,所有我们先让这些所有的动作都在后台线程异步执行
2.将UIImage图片变成224*224大小
3.调用我们事先添加的辅助方法将UIImage对象转成CVPixelBuffer对象
4.正式调用GoogLeNetPlaces().prediction的方法进行图片分析
5.把分析输出的结果最有可能的那个描述 和 这个描述对应的准确率 作为显示的内容
6.调用我们最开始写的辅助方法,返回主线程显示分析结果
现在去只需要去imagePickerController获取到图片的代理方法里,在“imageView.image = image”这一句后面添加调用一下我们写好的分析方法即可
analysisImageWithoutVision(image: image)
现在运行一下程序看看是不是成功啦!
4.使用纯CoreML + Vision进行图片分析
再换种方法来做,结合Vision来做图片分析其实更直观,也不用再把图片转成合适大小的CVPixelBuffer那么费劲了
现在去到analysisImageWithVision(image:)方法里,将下面代码加入进入
indicator.startAnimating()
view.isUserInteractionEnabled = false
//转换图片类型
guard let ciImage = CIImage(image: image) else {
fatalError("convert CIImage error")
}
前两句还是一样先转个圈,让用户暂停交互
再将图片参数转换为CIImage格式,因为等会需要这个格式,而不是UIImage
接下来再添加下面代码
guard let model = try? VNCoreMLModel(for: GoogLeNetPlaces().model) else {
fatalError("load GoogLeNetPlaces model error")
}
我们通过GoogLeNetPlaces().model这个模型参数创建了一个Vision库里面的VNCoreMLModel类型的模型对象。
继续添加代码
let request = VNCoreMLRequest(model: model) { [weak self] (request, error) in
//---------------- 1----------------
guard let results = request.results as? [VNClassificationObservation] else {
fatalError("unexpected result type")
}
// ----------------2----------------
guard let topResult = results.first else {
fatalError("No result!")
}
// ----------------3----------------
let result = "\(topResult.identifier)(\(Int(topResult.confidence * 100))%)"
//---------------- 4----------------
self?.showAnalysisResultOnMainQueue(with: result)
}
这里我们使用了刚刚创建的model来创建一个VNCoreMLRequest请求,这个请求就会使用我们引入的模型来对图片进行分析,同时设置了分析完成后的处理流程。
分析处理完成后的流程是这样
1.判断request.results结果数组是否为VNClassificationObservation对象的数组,VNClassificationObservation是什么呢?它就是对分析结果的一种描述类,因为我们使用的模型就是用来识别不同类型的场景的,所以它是一个场景识别器,所以他的分析结果就会是ClassificationObservation类型,Vision库还有很多其他的分析结果类型,你有兴趣可以去看看,就能理解这个类型的含义了
2.从结果results结果数组里,拿出第一个结果,因为第一结果就是准确率最高的那个。
3.我们把刚刚取到的第一个结果的名字和准确率作为显示的内容,confidence就是准确率,大小为0-1,如果是1也就是百分之100肯定。
4.调用我们最开始写的辅助方法,返回主线程显示分析结果
现在去imagePickerController获取到图片的代理方法里,它分析方法调用替换为我们的新方法
analysisImageWithVision(image: image)
现在运行程序再试试看是不是也是可以的

问题
不知道你们是否发现了有个问题,仔细看看我发的这两个方法实现的运行结果gif图。
我们只使用CoreML和使用CoreML+Vision两种方法来做的图片类型分析的结果有小小出入,然而针对同一张图片,两种方法分析得到的最可能的图片类型都是pagoda(塔),但是准确率却不一样,第一种认为51%是塔而第二种44%是塔,这是为什么呢?
我猜可能是因为第一种方法对图片做了大小的转换导致的,两个方法分析的图片其实是有差别的了。另外也可能Vision使用MLModel做分析不止是简单的封装了一层,可能还有有一些自己特殊的处理。当然这只是我自己的猜想,如果有高人了解的具体原因的话也可以赐教一下