一、Okhttp的使用
1、创建一个OKHttpClient对象
2、创建一个request对象,通过内部类Builder调用生成Request对象
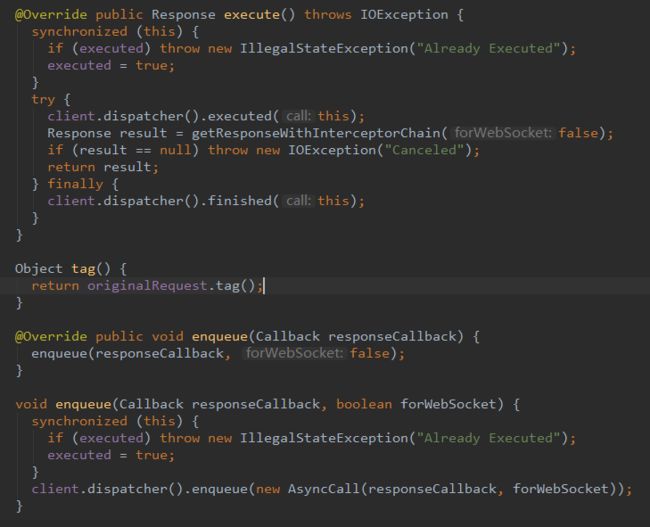
3、创建一个Call对象,调用execute/enqueue。
这个使用不在叙述,详情请参考Android网络编程(六)OkHttp3用法全解析
OkHttp3源码分析
OkHttp是一个高效的Http客户端,有如下的特点:
支持HTTP2/SPDY黑科技
socket自动选择最好路线,并支持自动重连
拥有自动维护的socket连接池,减少握手次数
拥有队列线程池,轻松写并发
拥有Interceptors轻松处理请求与响应(比如透明GZIP压缩,LOGGING)
基于Headers的缓存策略
二、Okhttp源码剖析
主要对象
Connections: 对JDK中的物理socket进行了引用计数封装,用来控制socket连接
Streams: 维护HTTP的流,用来对Requset/Response进行IO操作
Calls: HTTP请求任务封装
StreamAllocation: 用来控制Connections/Streams的资源分配与释放
第一部分 工作流程的概述
RealCall.java
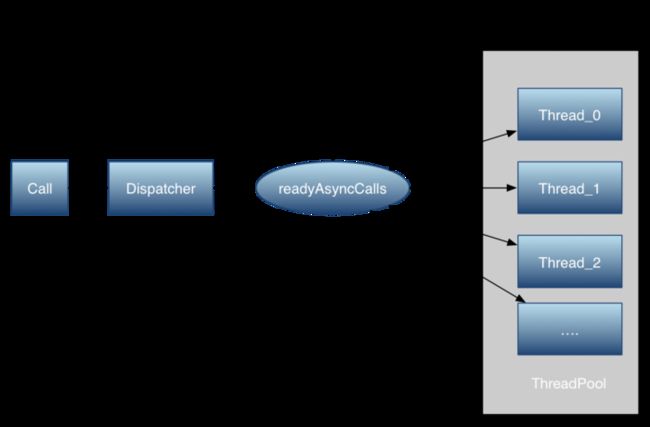
当我们用OkHttpClient .newCall(request)进行execute/enenqueue时,实际是将请求Call放到了Dispatcher中,okhttp使用Dispatcher进行线程分发,它有两种方法,一个是普通的同步单线程;另一种是使用了队列进行并发任务的分发(Dispatch)与回调,我们下面主要分析第二种,也就是队列这种情况,这也是okhttp能够竞争过其它库的核心功能之一。
Dispatcher的结构
Dispatcher维护了如下变量,用于控制并发的请求
private intmaxRequests=64;// 最大并发请求数为64
private intmaxRequestsPerHost=5;// 每个主机最大请求数为5
/** 消费者池(也就是线程池) */
private ExecutorServiceexecutorService;
/** 正在准备的异步请求 */
private final Deque readyAsyncCalls=newArrayDeque<>();
/**正在运行的异步请求*/
private final DequerunningAsyncCalls=newArrayDeque<>();
/** 正在运行的同步请求. */
private finalDequerunningSyncCalls=newArrayDeque<>();
在异步enqueue()请求中,如果满足(runningRequests<64 && runningRequestsPerHost<5),那么就直接把AsyncCall直接加到runningCalls的队列中,并在线程池中执行。如果消费者缓存满了,就放入readyAsyncCalls进行缓存等待。如图。

Socket管理(StreamAllocation)
这个环节主要讲了http的握手过程与连接池的管理,分析的对象主要是StreamAllocation。
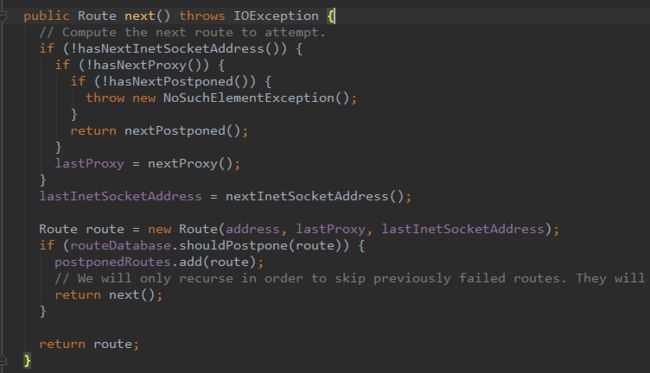
1. 选择路线与自动重连(RouteSelector)
此步骤用于获取socket的ip与端口,各位请欣赏 源码中next()的迷之缩进与递归,代码如下:
2. 连接socket链路(RealConnection)
当地址,端口准备好了,就可以进行TCP链接了(也就是我们常说的TCP三次握手)。

最终调用了socket.connect(address,connectTimeout)

3、释放socket链路(release) StreamAllocation.java
尝试从缓存的连接池中删除(remove)
如果没有命中缓存,就直接调用jdk的socket关闭

第二部分 复用连接池 连接池的使用与分析
Call: 对http的请求封装,属于程序员能够接触的上层高级代码
Connection: 对jdk的socket物理连接的包装,它内部有List>的引用
StreamAllocation: 表示Connection被上层高级代码的引用次数
ConnectionPool: Socket连接池,对连接缓存进行回收与管理,与CommonPool有类似的设计
Deque: Deque也就是双端队列,双端队列同时具有队列和栈性质,经常在缓存中被使用,这个是java基础
2.1. 实例化
在源码中,我们先找ConnectionPool实例化的位置,它是直接new出来的,而它的各种操作却在OkHttpClient的static区实现了Internal.instance接口作为ConnectionPool的包装。

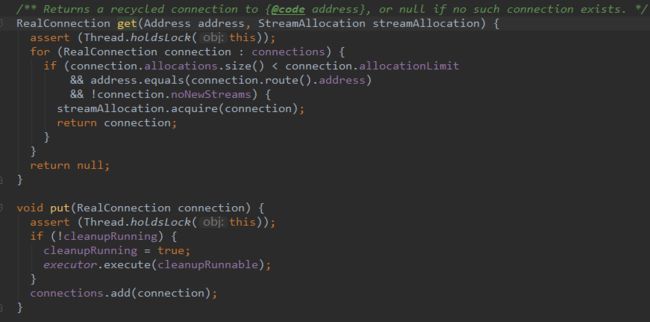
2.3 put/get操作
第三部分 [缓存策略]
HTTP缓存基础知识
1. Expires
表示到期时间,一般用在response报文中,当超过此事件后响应将被认为是无效的而需要网络连接,反之而是直接使用缓存
Expires: Thu, 12 Jan 2017 11:01:33 GMT
2. Cache-Control
相对值,单位是秒,指定某个文件被续多少秒的时间,从而避免额外的网络请求。比expired更好的选择,它不用要求服务器与客户端的时间同步,也不用服务器时刻同步修改配置Expired中的绝对时间,而且它的优先级比Expires更高。比如静态资源有如下的header,表示可以续31536000秒,也就是一年。
Cache-Control: max-age=31536000, public
3. 修订文件名(Reving Filenames)
如果我们通过设置header保证了客户端可以缓存的,而此时远程服务器更新了文件如何解决呢?我们这时可以通过修改url中的文件名版本后缀进行缓存,比如下文是又拍云的公共CDN就提供了多个版本的JQuery。
upcdn.b0.upaiyun.com/libs/jquery/jquery-2.0.3.min.js
4. 条件GET请求(Conditional GET Requests)与304
如缓存果过期或者强制放弃缓存,在此情况下,缓存策略全部交给服务器判断,客户端只用发送条件get请求即可,如果缓存是有效的,则返回304 Not Modifiled,否则直接返回body。
以上内容是作为一个服务器开发或者客户端的常识,下图是网上找的总结,注意图中的 ETag 和 Last-Modified 可能有优先级的歧义,你只需要记住它们是没有优先级的。
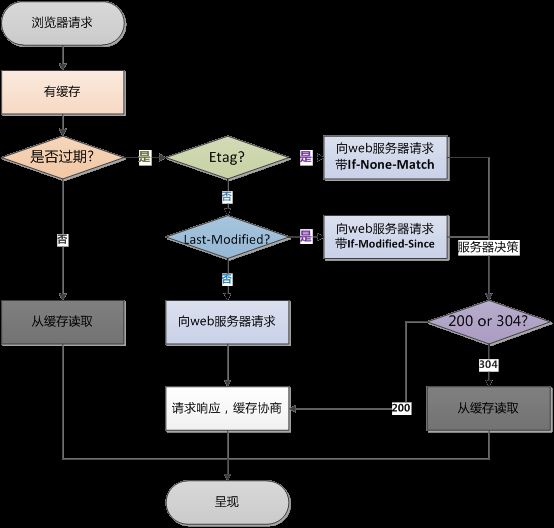
源码分析
OkHttp中使用了CacheStrategy实现了上文的流程图,它根据之前的缓存结果与当前将要发送Request的header进行策略分析,并得出是否进行请求的结论。

第四部分 OkHttp3 [DiskLruCache]
1. Cache的简介
缓存,顾名思义,也就是方便用户快速的获取值的一种储存方式。
缓存载体与持久载体总是相对的,容量远远小于持久容量,成本高于持久容量,速度高于持久容量。
需要实现排序依据,在java中,可以使用Comparable作为排序的的接口
需要一种页面置换算法(page replacement algorithm)将旧页面去掉换成新的页面,如最久未使用算法(LFU)、先进先出算法(FIFO)、最近最少使用算法(LFU)、非最近使用算法(NMRU)等
如果没有命中缓存,就需要从原始地址获取,这个步骤叫做“回源”,CDN厂商会标注“回源率”作为卖点。
在OkHttp中,使用FileSystem作为缓存载体(磁盘相对于网络的缓存),使用LRU作为页面置换算法(封装了LinkedHashMap)。
2. LinkedHashMap原理
待续。。。
总结
OkHttp通过对文件进行了多次封装,实现了非常简单的I/O操作
OkHttp通过对请求url进行md5实现了与文件的映射,实现写入,删除等操作
OkHttp内部维护着清理线程池,实现对缓存文件的自动清理
第五部分 OkHttp3源码分析[任务队列]
1. 线程池基础
在初学Java的时候,各位可能会用new Thread + Handler来写异步任务,它的坑网上已经烂大街了,比如不能自动关闭,迷之缩进难以维护,导致目前开发者几乎不怎么用它。而现在很多框架,比如Picasso,Rxjava等,都帮我们写好了对应场景的线程池,但是线程池到底有什么好呢?
线程池好处都有啥?
线程池的关键在于线程复用以减少非核心任务的损耗。
多线程技术主要解决处理器单元内多个线程执行的问题,它可以显著减少处理器单元的闲置时间,增加处理器单元的吞吐能力。但如果对多线程应用不当,会增加对单个任务的处理时间。
假设在一台服务器完成一项任务的时间为T。
T1 创建线程的时间
T2 在线程中执行任务的时间,包括线程间同步所需时间
T3 线程销毁的时间
显然T = T1+T2+T3。
可以看出T1,T3是多线程本身的带来的开销(在Java中,通过映射pThead,并进一步通过SystemCall实现native线程),我们渴望减少T1,T3所用的时间,从而减少T的时间。但一些线程的使用者并没有注意到这一点,所以在程序中频繁的创建或销毁线程,这导致T1和T3在T中占有相当比例。显然这是突出了线程的弱点(T1,T3),而不是优点(并发性)。
线程池技术正是关注如何缩短或调整T1,T3时间的技术,从而提高服务器程序性能的。
1. 通过对线程进行缓存,减少了创建销毁的时间损失。
2. 通过控制线程数量阀值,减少了当线程过少时带来的CPU闲置(比如说长时间卡在I/O上了)与线程过多时对JVM的内存与线程切换时系统调用的压力。
在OkHttp,使用如下构造了单例线程池

public synchronized ExecutorService executorService() {
if(executorService==null) {
executorService=new ThreadPoolExecutor(0,Integer.MAX_VALUE,60,TimeUnit.SECONDS,
newSynchronousQueue(),Util.threadFactory("OkHttp Dispatcher", false));
}
returnexecutorService;
}
参数说明如下:
int corePoolSize: 最小并发线程数,这里并发同时包括空闲与活动的线程,如果是0的话,空闲一段时间后所有线程将全部被销毁。
int maximumPoolSize: 最大线程数,当任务进来时可以扩充的线程最大值,当大于了这个值就会根据丢弃处理机制来处理
long keepAliveTime: 当线程数大于corePoolSize时,多余的空闲线程的最大存活时间,类似于HTTP中的Keep-alive
TimeUnit unit: 时间单位,一般用秒
BlockingQueue workQueue: 工作队列,先进先出,可以看出并不像Picasso那样设置优先队列。
ThreadFactory threadFactory: 单个线程的工厂,可以打Log,设置Daemon(即当JVM退出时,线程自动结束)等。设置为false说明是用户线程。。
现在简单介绍Thread.setDaemon方法。
java中线程分为两种类型:用户线程和守护线程。通过Thread.setDaemon(false)设置为用户线程;通过Thread.setDaemon(true)设置为守护线程。
所谓守护 线程,是指在程序运行的时候在后台提供一种通用服务的线程,比如垃圾回收线程就是一个很称职的守护者,并且这种线程并不属于程序中不可或缺的部分。因此,当所有的非守护线程结束时,程序也就终止了,同时会杀死进程中的所有守护线程。反过来说,只要任何非守护线程还在运行,程序就不会终止。
可以看出,在Okhttp中,构建了一个阀值为[0, Integer.MAX_VALUE]的线程池,它不保留任何最小线程数,随时创建更多的线程数,当线程空闲时只能活60秒,它使用了一个不存储元素的阻塞工作队列,一个叫做"OkHttp Dispatcher"的线程工厂。
也就是说,在实际运行中,当收到10个并发请求时,线程池会创建十个线程,当工作完成后,线程池会在60s后相继关闭所有线程。
在而在OkHttp中,它使用Dispatcher作为任务的派发器,线程池对应多台后置服务器,用AsyncCall对应Socket请求,用Deque对应Nginx的内部缓存。