在ES中的数据可以分为两类:精确值(exact values)以及全文(full text)。
- 精确值:例如日期类型date,若date其有两个值:2014-09-15与2014,那么这两个值不相等。又例如字符串类型foo与Foo不相等。
- 全文:通常是人类语言写的文本,例如一段tweet信息、email的内容等。
精确值很容易被索引:一个值要么相当要么不等。 索引全文值就需要很多功夫。例如我们不仅要想:这个文档符合我们的查询吗?还要想:这个文档有多符合我们的查询?换句话说就是:这个文档跟我们的查询关联大吗?我们很少精确的去匹配整个全文,我们最想要的是去匹配全文文本的内部信息。除此,我们还希望搜索能够理解我们的意图:例如
如果你搜索UK,我们需要包含United Kingdom的文本也会被匹配。 如果你搜索jump,那么包含jumped,jumps,jumping,更甚者leap的文本会被匹配。
为了更方便的进行全文索引,ES首先要先分析文本,然后使用分析过的文本去创建倒序索引。

举例
例如:如果我们有两个文档,每一个文档有一个content字段,包含的内容如下:
1.The quick brown fox jumped over the lazy dog
2.Quick brown foxes leap over lazy dogs in summer
CharcterFilters
字符过滤器能够去除HTML标记,或者转换"&"为"and"。没有特殊字符,因此不需要CharacterFilters特殊处理。
Tokenizer
Tokenizer将content分割成单独的词(称为terms or tokens),创建一个所有terms的列表,然后罗列每一个term出现的文档。此过程称为tokenization。如下图:

ES使用倒序索引来加速全文索引。一个倒序索引由两部分组成:
- 在文档中出现的所有不同的词;
- 对每个词,它所出现的文档的列表。
如果我们想要搜索 quick brown,我们仅仅只需要找每一个term出现的文档即可。如下图:
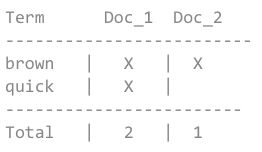
每一个文档都匹配到了,但是第一个比第二个要匹配的多。如果我们使用一个简单的相似性算法仅仅只计算匹配的数量,那么我们可以称第一个文档要比第二个匹配的好(与我们的查询更有关联)。
Token Filters
但是现在的倒序索引有一些问题:
Quick与quick是两个不同的term,但是搜索的用户会认为它们应该是一样的term才是合理的。
fox和foxes,dog和dogs是一样的词根,应该列为同一个term。 jumped和leap虽然词根不一样,但是意义却相同。
如果改善了上面的问题,那么倒序索引应该如下图:

每个词都通过所有标记过滤(token filters),它可以修改词(例如将"Quick"转为小写),去掉词(例如停用词像"a"、"and"、"the"等等),或者增加词(例如同义词像"jump"和"leap")
但是此时如果用户搜索Quick还会失败,因为term不含精确值Quick。但是,如果我们对QueryString使用与上述改善步骤相同的策略,那么用户搜索的Quick将会被转换为quick,此过程称为normalization。那么将会成功匹配。 对content的处理tokenization和normalization称为analysis过程。ES有很多种内置的analyzer处理这些。
参考
http://www.shaheng.me/blog/2015/06/elasticsearch--.html
http://mednoter.com/all-about-analyzer-part-one.html