一、HDFS概述及设计目标
1.是什么:Hadoop实现了一个分布式文件系统,源自于Google的GFS的论文,是其克隆版。
2.目标:
非常巨大的分布式文件系统;
运行在普通的廉价的硬件上(普通PC机组成一个集群即可使用);
易扩展、为用户提供性能不错的文件存储服务。(文件分块部署在不同节点上)
二、HDFS架构
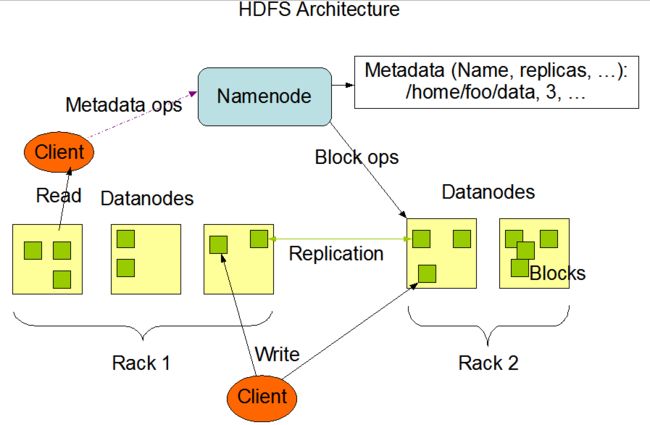
HDFS架构:
1 Master(NameNode/NN) ,N个Slaves(DataNode/DN)
NN:
负责客户端请求的响应;负责元数据的管理(文件名称、副本系数、Block存放的DN)
DN:
存储用户的文件对应的数据块(Block);要定期向NN发送心跳信息,汇报本身及其所有的Block信息,健康状况
A typical deployment has a dedicated machine that runs only the NameNode software. Each of the other machines in the cluster runs one instance of the DataNode software. The architecture does not preclude running multiple DataNodes on the same machine but in a real deployment that is rarely the case.
NameNode+N个DataNode,NN和DN部署在不同节点上
三、HDFS副本机制
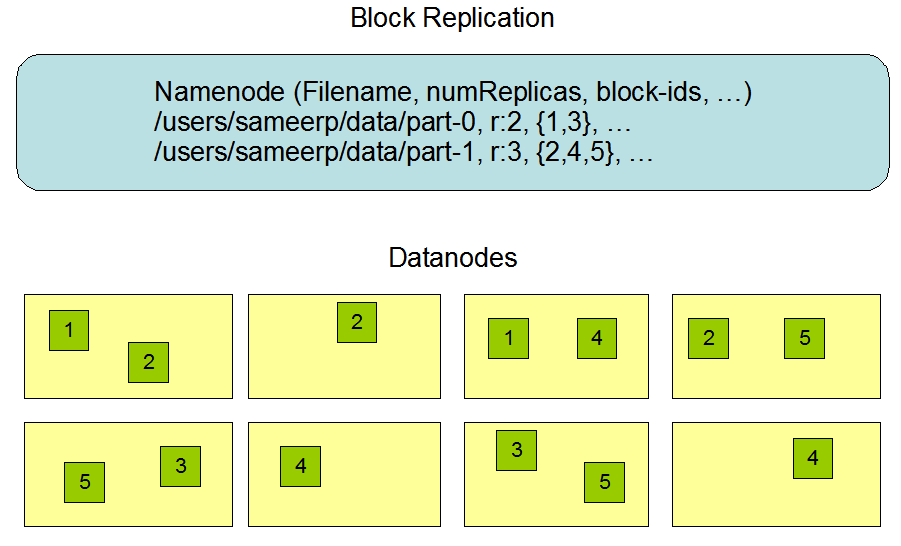
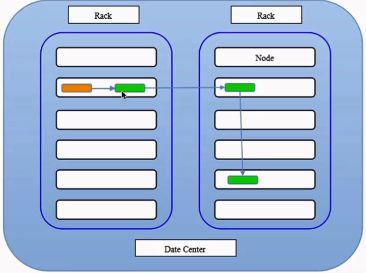
HDFS副本存放策略:分机架部署存放
一个文件被拆分成多个block,然后每个block存多份,默认是3份。
褐色所在节点是client ,在同一节点存放第一个副本;然后在第二个机架上存放副本;第三个副本存储在与第二个副本相同机架上不同节点上。分机架存放!
四、HDFS环境搭建
1.Hadoop伪分布式安装:
jdk安装,配置环境变量;
SSH安装配置:cp ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys
五、HDFS shell
与centos下的命令差不多,前面增加hadoop fs +命令
hadoop fs [generic options][-appendToFile...]
[-cat [-ignoreCrc]...][-checksum...][-chgrp [-R] GROUP PATH...][-chmod [-R]PATH...][-chown [-R] [OWNER][:[GROUP]] PATH...][-copyFromLocal [-f] [-p] [-l]...][-copyToLocal [-p] [-ignoreCrc] [-crc]...][-count [-q] [-h] [-v]...][-cp [-f] [-p | -p[topax]]...][-createSnapshot[]][-deleteSnapshot][-df [-h] [...]][-du [-s] [-h]...][-expunge][-find......][-get [-p] [-ignoreCrc] [-crc]...][-getfacl [-R]][-getfattr [-R] {-n name | -d} [-e en]][-getmerge [-nl]][-help [cmd ...]][-ls [-d] [-h] [-R] [...]][-mkdir [-p]...][-moveFromLocal...][-moveToLocal][-mv...][-put [-f] [-p] [-l]...][-renameSnapshot][-rm [-f] [-r|-R] [-skipTrash]...][-rmdir [--ignore-fail-on-non-empty]...][-setfacl [-R] [{-b|-k} {-m|-x}]|[--set]][-setfattr {-n name [-v value] | -x name}][-setrep [-R] [-w]...][-stat [format]...][-tail [-f]][-test -[defsz]][-text [-ignoreCrc]...][-touchz...]
[-usage [cmd ...]]
六、Java API操作HDFS
七、HDFS文件读写流程


读:

八、HDFS优缺点
数据冗余、硬件容错;处理流式的数据访问,一次写入多次读取操作;适合存储大文件;构建在廉价机器上;
低延迟的数据访问;不适合小文件存储
HDFS的优点:
1、处理超大文件
这里的超大文件通常是指百MB、甚至数百TB大小的文件。目前在实际应用中,HDFS已经能用来存储管理PB级的数据了。
2、流式的访问数据
HDFS的设计建立在“一次写入、多次读写”任务的基础上。这意味着一个数据集一旦由数据源生成,就会被复制分发到不同的存储节点中,然后响应各种各样的数据分析任务请求。在多数情况下,分析任务都会涉及数据集中的大部分数据,也就是说,对HDFS来说,请求读取整个数据集要比读取一条记录更加高效。
3、运行于廉价的商用机器集群上
Hadoop设计对应急需求比较低,只须运行在低廉的商用硬件集群上,而无需在昂贵的高可用性机器上。廉价的商用机也就意味着大型集群中出现节点故障情况的概率非常高。HDFS遇到了上述故障时,被设计成能够继续运行且不让用户察觉到明显的中断。
HDFS的缺点:
1、不适合低延迟数据访问
如果要处理一些用户要求时间比较短的低延迟应用请求,则HDFS不适合。HDFS是为了处理大型数据集分析任务的,主要是为达到高的数据吞吐量而设计的,这就可能要求以高延迟作为代价。
改进策略:
对于那些有低延时要求的应用程序,HBase是一个更好的选择,通过上层数据管理项目尽可能地弥补这个不足。在性能上有了很大的提升,它的口号是goes real time。使用缓存或多个master设计可以降低Clinet的数据请求压力,以减少延时。
2、无法高效存储大量的小文件
因为NameNode把文件系统的元数据放置在内存中,所有文件系统所能容纳的文件数目是由NameNode的内存大小来决定。还有一个问题就是,因为MapTask的数量是由Splits来决定的,所以用MR处理大量的小文件时,就会产生过多的MapTask,线程管理开销将会增加作业时间。当Hadoop处理很多小文件(文件大小小于HDFS中Block大小)的时候,由于FileInputFormat不会对小文件进行划分,所以每一个小文件都会被当做一个Split并分配一个Map任务,导致效率底下。
例如:一个1G的文件,会被划分成16个64MB的Split,并分配16个Map任务处理,而10000个100Kb的文件会被10000个Map任务处理。
改进策略:
要想让HDFS能处理好小文件,有不少方法。利用SequenceFile、MapFile、Har等方式归档小文件,这个方法的原理就是把小文件归档起来管理,HBase就是基于此的。
3、不支持多用户写入及任意修改文件
在HDFS的一个文件中只有一个写入者,而且写操作只能在文件末尾完成,即只能执行追加操作,目前HDFS还不支持多个用户对同一文件的写操作,以及在文件任意位置进行修改。