目录
从零实现ImageLoader(一)—— 架构
从零实现ImageLoader(二)—— 基本实现
从零实现ImageLoader(三)—— 线程池详解
从零实现ImageLoader(四)—— Handler的内心独白
从零实现ImageLoader(五)—— 内存缓存LruCache
从零实现ImageLoader(六)—— 磁盘缓存DiskLruCache
前言
在上一篇文章里我们讲解了内存缓存的原理,今天我们就来讲讲磁盘缓存的实现。这里我们选择了Jake Wharton大神的开源项目DiskLruCache,这个项目现在已经成了所有需要磁盘缓存项目的第一选择。
怎么用
在阅读源码之前我们首先要做的还是把它加入我们的项目,下面是将对DiskLruCache进行封装的DiskCache类:
public class DiskCache {
private DiskLruCache mDiskLruCache;
public DiskCache(File directory,int appVersion, int maxSize) throws IOException {
mDiskLruCache = DiskLruCache.open(directory, appVersion, 1, maxSize);
}
public Bitmap get(String key) throws IOException {
try (DiskLruCache.Snapshot snapshot = mDiskLruCache.get(key)) {
if(snapshot != null) {
return BitmapFactory.decodeStream(snapshot.getInputStream(0));
} else {
return null;
}
}
}
public void put(String key, Bitmap bitmap) throws IOException {
DiskLruCache.Editor editor = mDiskLruCache.edit(key);
if(editor == null) return;
try (OutputStream out = editor.newOutputStream(0)) {
bitmap.compress(Bitmap.CompressFormat.JPEG, 100, out);
editor.commit();
}
}
}
创建
-
directory:缓存文件目录。 -
appVersion:缓存版本,应用版本变化后会重新创建缓存。 -
valueCount:DiskLruCache的键值与缓存文件是一对多的关系。这里传入1,即一个key对应一个缓存文件。 -
maxSize:缓存文件可以使用的最大容量。
获取
通过key获取到该键值所对应缓存文件的Snapshot对象,再通过Snapshot获取到对应缓存的InputStream,由于我们采用的是键值缓存一对一的关系,所以这里只需要取第0个输入流就可以了。
存储
和获取过程很类似,不过这里变成了用edit()方法得到Editor对象,需要注意的是,在写入操作完成后必须要调用Editor对象的commit()方法来结束对该缓存的访问。
现在在Dispatcher.get()方法中加入DiskCache的逻辑就可以了:
public class Dispatcher {
public Bitmap get() throws IOException {
//从内存获取
Bitmap image = mMemoryCache.get(mKey);
if(image == null) {
//从磁盘获取
image = mDiskCache.get(mKey);
if(image == null) {
//从网络获取
image = NetworkUtil.getBitmap(mUrl);
if(image == null) return null;
mDiskCache.put(mKey, image);
}
mMemoryCache.put(mKey, image);
}
return image;
}
}
双管齐下
在阅读DiskLruCache的源码之前,我们不妨先思考一下,如果让我们来实现一个磁盘缓存工具,我们会怎么做?
因为这里涉及到了大量缓存数据的记录,恐怕大多数人首先想到的就是数据库,但是数据库的效率其实是比较低的,所以Jake Wharton大神选择了使用一个独立的文件来进行缓存信息的记录,这也是我们后面将要提到的journal文件,至于journal文件是如何记录缓存信息的,咱们暂且按下不表。
实现了缓存信息的记录,接下来又要考虑另一个问题,怎么实现缓存的淘汰机制?有人就要说了,直接实现一个LRU算法不就行了?这也是DiskLruCache第二个高明的地方,还记得咱们上一篇讲的LruCache的实现吗?LruCache基本上将所有的实现LinkedHashMap类去完成,这里DiskLruCache也借助了它。DiskLruCache在初始化的时候会将journal文件里的数据通通读入LinkedHashMap,而在进行缓存文件存取的时候,DiskLruCache会同时更新LinkedHashMap和journal文件的信息。
就是利用journal文件的信息记录和LinkedHashMap的淘汰机制双管齐下,DiskLruCache仅仅用了不到1000行的代码就实现了如此强大又高效的磁盘缓存。
神奇的journal文件
在探究DiskLruCache的源码前,我们先来看一看journal文件的真实面目,这也是DiskLruCache的精髓所在:
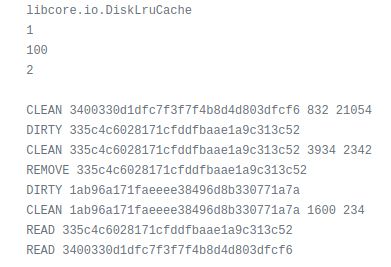
这就是journal文件的内部,我们先来看前5行:
- 第一行:
libcore.io.DiskLruCache代表这是一个DiskLruCache的journal文件。 - 第二行:表示磁盘缓存的版本,恒为1。
- 第三行:表示软件的版本,在版本变化后需要重建缓存。
- 第四行:
key值与缓存文件是一对多的关系,这里的2就表示一个key值对应两个缓存文件,我们一般使用1。 - 第五行:空行,为了和下面的缓存信息分隔开。
可以有人可能不明白这个key值缓存一对多的关系究竟是什么样的,这里我放一个截图大家就明白了:

可以看到缓存文件是以key.index的形式命名的,由于我们这里一个key值只对应了一个缓存文件,所以文件都是以.0结尾的。
我们接着看journal文件的构成,接下来的几行每一行都代表了一个操作,我将它们分为了两组,一组读,对应之前的get()方法,一组写,对应edit()方法。
读
- READ:后跟缓存的key值。代表一次读操作。
写
DIRTY: 后跟缓存的key值。代表缓存正在被编辑,也就是调用了
edit()方法,还没有commit()。它的下一条操作必定是CLEAN或REMOVE。CLEAN:后跟缓存的key值及对应文件的大小(由于这里一个key对应两个文件,所以会出现两个数值)。该操作代表缓存已经成功写入了,也就是已经调用了
commit()方法了。REMOVE: 后跟缓存的key值。表示写入失败并调用了
commit()方法,或者调用了remove()方法。
The Get, the Edit and the Remove
知道了journal文件的组成,接下来我们看一下DiskLruCache到底在读写时干了什么。
读
public synchronized Snapshot get(String key) throws IOException {
...
Entry entry = lruEntries.get(key);
if (entry == null) {
return null;
}
...
InputStream[] ins = new InputStream[valueCount];
try {
for (int i = 0; i < valueCount; i++) {
ins[i] = new FileInputStream(entry.getCleanFile(i));
}
} catch (FileNotFoundException e) {
// A file must have been deleted manually!
...
return null;
}
journalWriter.append(READ + ' ' + key + '\n');
...
return new Snapshot(key, entry.sequenceNumber, ins, entry.lengths);
}
这里的逻辑主要分四步:
- 首先,通过
key值获取到lruEntries也就是LinkedHashMap中的数据(lruEntries.get()操作也同时更新了数据在LinkedHashMap中的位置,这在上一篇文章里有讲过)。 - 接着,依次打开该
key值所对应的几个缓存文件的输入流。 - 之后,在
journal文件中加入一条READ操作。 - 最后,返回内部持有文件输入流的
Snapshot。
写
写操作比读操作稍微复杂一点,因为涉及两步,一步获取Editor,一步commit()提交,但整体的思路是没有变的。
private synchronized Editor edit(String key, long expectedSequenceNumber) throws IOException {
...
Entry entry = lruEntries.get(key);
...
if (entry == null) {
entry = new Entry(key);
lruEntries.put(key, entry);
} else if (entry.currentEditor != null) {
return null; // Another edit is in progress.
}
Editor editor = new Editor(entry);
entry.currentEditor = editor;
// Flush the journal before creating files to prevent file leaks.
journalWriter.write(DIRTY + ' ' + key + '\n');
journalWriter.flush();
return editor;
}
与get()方法相差无几,不过变成了三步:
- 首先,从
LinkedHashMap中获取缓存数据。 - 接着,在
journal文件中加入一条DIRTY记录。 - 最后,返回
Editor对象。
这里少的一步是打开文件流,DiskLruCache将这一步放到了Editor中去操作,也就是我们之前使用过的Editor.newOutputStream(0)方法,这里就不去细看了。
在我们完成写操作后需要调用commit()方法,它最终调用了completeEdit()方法:
private synchronized void completeEdit(Editor editor, boolean success) throws IOException {
Entry entry = editor.entry;
...
entry.currentEditor = null;
if (entry.readable | success) {
entry.readable = true;
journalWriter.write(CLEAN + ' ' + entry.key + entry.getLengths() + '\n');
...
} else {
lruEntries.remove(entry.key);
journalWriter.write(REMOVE + ' ' + entry.key + '\n');
}
journalWriter.flush();
...
}
如果写入成功,就在journal文件中插入一条CLEAN记录;如果失败,就插入一条REMOVE记录,同时移除LinkedHashMap中的数据。
删
public synchronized boolean remove(String key) throws IOException {
...
Entry entry = lruEntries.get(key);
if (entry == null || entry.currentEditor != null) {
return false;
}
for (int i = 0; i < valueCount; i++) {
File file = entry.getCleanFile(i);
if (file.exists() && !file.delete()) {
throw new IOException("failed to delete " + file);
}
...
}
...
journalWriter.append(REMOVE + ' ' + key + '\n');
lruEntries.remove(key);
...
return true;
}
- 首先,从
LinkedHashMap中获取该缓存数据。 - 接着,删除该缓存所对应的文件。
- 之后,在
journal文件中插入REMOVE记录。 - 最后,从
LinkedHashMap中移除缓存数据。
而淘汰机制只有短短四行代码,不断从LinkedHashMap中取出最旧的数据,并调用remove()方法,直到总体积小于指定的大小:
private void trimToSize() throws IOException {
while (size > maxSize) {
Map.Entry toEvict = lruEntries.entrySet().iterator().next();
remove(toEvict.getKey());
}
}
看了这几个操作之后,大家可能依然一头雾水,一会是对LinkedHashMap的操作,一会又是对journal文件的操作。其实理解起来很简单,DiskLruCache在初始化之后就已经跟journal文件一点关系都没有了,所有的读写操作以及淘汰机制都是基于LinkedHashMap的,可LinkedHashMap有一点不好就是它只能停留在内存里,应用一关闭就什么都没了,所以每次对LinkedHashMap进行操作的时候,同时将这一次的操作记录在journal文件里,这样,应用在下次启动的时候只需要把LinkedHashMap再从journal文件里恢复出来就行了。我们看看DiskLruCache是不是这样做的:
journal文件的读取
在DiskLruCache初始化的时候,会先读入前五行,大家可以理解为journal文件的属性,接下来DiskLruCache会将读取到的每一行都转化为一个对LinkedHashMap的操作:
private void readJournalLine(String line) throws IOException {
int firstSpace = line.indexOf(' ');
if (firstSpace == -1) {
throw new IOException("unexpected journal line: " + line);
}
int keyBegin = firstSpace + 1;
int secondSpace = line.indexOf(' ', keyBegin);
final String key;
if (secondSpace == -1) {
key = line.substring(keyBegin);
if (firstSpace == REMOVE.length() && line.startsWith(REMOVE)) {
lruEntries.remove(key);
return;
}
} else {
key = line.substring(keyBegin, secondSpace);
}
Entry entry = lruEntries.get(key);
if (entry == null) {
entry = new Entry(key);
lruEntries.put(key, entry);
}
if (secondSpace != -1 && firstSpace == CLEAN.length() && line.startsWith(CLEAN)) {
String[] parts = line.substring(secondSpace + 1).split(" ");
entry.readable = true;
entry.currentEditor = null;
entry.setLengths(parts);
} else if (secondSpace == -1 && firstSpace == DIRTY.length() && line.startsWith(DIRTY)) {
entry.currentEditor = new Editor(entry);
} else if (secondSpace == -1 && firstSpace == READ.length() && line.startsWith(READ)) {
// This work was already done by calling lruEntries.get().
} else {
throw new IOException("unexpected journal line: " + line);
}
}
代码有点长,不过大多数都是对字符串的处理,我们可以挑重点的看,在这里会根据不同的操作符分别进行处理:
- 如果是REMOVE,直接从
lruEntries中移除该缓存。 - 如果是DIRTY,则新建一个
Editor并设置为该缓存的currentEditor,表示正在编辑。 - 如果是CLEAN,将该缓存的
currentEditor设置为空表示编辑完成。 - 如果是READ,什么也不做,但其实前面调用的
lruEntries.get()方法已经完成READ的功能了。
大家从DiskLruCache读取journal文件的代码里也能看出来,它其实是把每一行都转换为一个对LinkedHashMap的操作,相当于把我们之前执行过的所有操作再重新执行一遍,通过这种方式将LinkedHashMap恢复到上次软件关闭前的状态。
写在最后的话
到这里我们的DiskLruCache就讲解完了,同时,我们的从零实现ImageLoader系列也要告一段落了,大家肯定也发现,这个系列中关于如何实现ImageLoader所占的篇幅并不多,大多数时候还是在讲一些底层的实现原理,所以也有点挂羊头卖狗肉的嫌疑,不过我觉得用一个系列单单只讲ImageLoader如何实现有点太可惜了,我们必须从中发现更深层的知识。
之前也一直没有放项目的源码,大家如果想看的话,可以在我的GavinLi369/Translator项目里找到。当然,如果喜欢的话也别忘了点个star。
之后我应该会写几篇分析目前几大开源图片加载项目的文章,不过相信大家在看完这个系列后,再去看这些项目的源码已经不会有太大的压力了,强烈建议大家自己先去看看,可以先从一些相对简单的开始,比如Android-Universal-Image-Loader,picasso等,glide的实现有点过于复杂,如果一上来就看,很可能看不清楚,建议放在最后。