前几天,在一个群中和群友关于软件开发关于gitflow进行了讨论,其实也蛮有意思,所以特地也写一篇来记录和说明一下讨论的重点之所在。
讨论的起因是有两位小伙伴在朋友圈里转了《DevOps: 项目多环境配置和健康检查》一文,匆匆看完之后,我立即就震惊了。脑中立马响起了灵魂三问:
1. Merge后没测试的包可以上生产?
2. 靠merge能保证不同的代码一致么?
3. 到底应该在哪个分支上集成和测试?
争论点分析
在《DevOps: 项目多环境配置和健康检查》一文中,对于各个环境的叫法还是非常传统的,分别叫做dev(开发)、sit(system integration test 集成测试)、uat(user acceptance test, 用户接受测试)、prod(生产环境),而非现在DevOps的测试、预发布、灰度、生产等叫法。就我多年以来非常传统的软件开发的经验来看,在一个相对面向产品的软件开发过程中,软件配置管理的基线必须是产生在相对一致的过程中,即代码库的TAG ,代码的二进制包,测试和发布的二进制包,二进制包对应的文档必须保证一致性。一条相对稳定的基线的上的源代码,二进制包,文档(产品文档,测试报告,发布说明)必须是完全一致性的。
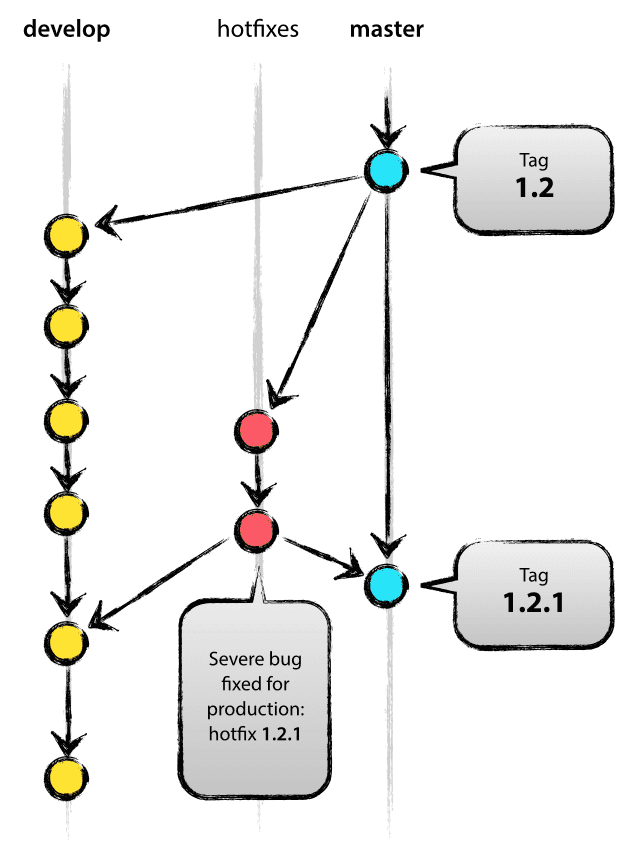
在特殊的情况下,针对于一些应急的临时的发布的二进制包(hotfix),可以在基线代码或上一个hotfix的代码基础上做少量的改动,做一些少量的回归甚至不回归而直接发布/ 上线。即使这样,这些应急的代码最后仍然要走正常的流程,回到相应的代码库里,并生成相应TAG和二进制包,并进行必要的回归测试,同时再发布到其他(客户)系统中。
于是我把这些问题带到了群里给小伙伴们,得到了转发者的回复。他给出经典的GitFlow《参考资料1》中的图片给我解释,开发一般是在Develop分支上工作,Master分支是已发功能的主干。

并说流程应该是测试通过-上线成功-最后merge到Master,这样才能保证master 不被污染。好吧,这又是打破我认知的一种说法。因为在CVS/SVN时代Head代表的是最新的代码,而我一直以来的工作方式是Head是不用受控的,可以放开让团队成提交代码,而发布分支,特别是已经有发布的分支是受控的,团队提交的代码必须经过Review,打包、打上TAG后提交测试。那难道是我对 GitLab和DevOps的认知出了问题,才导致有如此大的偏差?
关于GitFlow的再理解
在认真的读了《A successful Git branching model》一文的原文和相关的中文译文后,并且仔细看了一下GitLab Admin 的管理功能后,才发现了大家分歧的点在哪里。
1. "production ready" 的意义:如果我们是一个DevOps的团队,那么,我理解的是这个状态应该是准备好可以上生产环境了。但是,在Develop分支测试完成,merge完之后,是不是就production ready了呢?其实技术上来说,也未必。如果是一个相对大的系统,在这里测试完成,其实只是微服务里某个服务测试完成了,还需要上和生产环境更为接近的预发布系统进行测试。那在提交预发布前,应该是用master上出的包去提交。如果测试通过后续还有灰度流程,都应该只是部署过程。如果测试不通过,则应该还是修改代码,然后重走merge ,构建流程。
2. Release 分支的意义:在GtiFlow的定义里,真实的定义是准备Release的分支。如果你的团队在提交测试期间除修复 Bug外还有人力的话,那么在这个期间如果向Develop分支 push代码就会导致新的Feature 代码和Bug Fix的代码都被提交。这时我们就需要Release 分支了。在提测期间,新功能的代码将被提交到Develop分支,而修复Bug则在Release分支。
3. 缺失的维护分支:在Gitlab的建议里,如果是产品型,长期维护的产品,可以定义维护分支,对应于已经发布的版本。在这点上DevOps团队可能就比较少有这样的概念,因为正常情况下就是开发一版上一版抛弃一版。每一个版本都不需要长期维护。但如果是一个产品型的团队,就需要真正的定义维护分支了。举个例子说,微软同会维护着Win Xp, Win 7,Win 10等若干个Windows的版本,需要不同的维护分支对应不同的windows版本,然后在这些维护分支上出hotfix。
4. Feature分支的意义:仅为某个功能的开发而打的分支。宏观的来看,我更关心在服务器上对哪些分支做CI/CD,而非每一个人工作在哪个分支上,如果团队或者某几个开发者在开发过程中临时打了分支,而这些分支在合并回Develop时已经被删除,其实在CI/CD的过程甚至应该是忽略这些分支,或者要避免这些分支在CI/CD过程中打出的包对相应系统的影响。
个人的几点看法
说完了分歧点,其实归根到底这还是一个软件配置管理的问题,而现在各互联网公司的实践中,软件配置管理往往又和CI/CD等紧紧的绑定在一起。那究竟应该怎么做,才是对的呢?说到此,我想起了一位特别能侃的项目管理界的教授的话,在工程领域,对、错并不是最重要的,而要把项目完成了才行。其实就我个人的经验来看
1. 上线的包,是必须经过测试的。功能回归,安装测试等等都必须在尽可能与生产一致的环境中经过测试才能上线。master上的包,直接上预生产再经过一轮测是可以的,但直接上生产是一般是难以接受的。
2. 一致性是必须保持的,即源代码,二进制包,TAG/Branch以及在后续的测试、发布的工作中大家说的必须是同一个事情。如果说,测试上报问题,说出来的类似 我测的是你昨天给的包啊;开发又问,我几点给的啊。这样的沟通其实是很低效而且很容易出错的。正确的方式就是测试上报 0.2.x版本,任意一个开发都可以通过 这个版本号找到对应的源代码。
3. 团队手工操作的一致性其实是很难保证的,甚至在TAG/Branch的机制的理解上产生偏差也很正常。Git flow 其实是对此提供了一系列的IDE插件来做的。
那吐槽完了,究竟应该如何做呢?其实对于不同性质的项目和产品,不同成熟度的开发团队,我觉得做法也会略有不同。
1. 小型几乎无专职测试的项目团队:dev+master 分支,在dev上开发,merge 到master分支上tag后出包。因为这个状态的团队人员少,而且可能没有专门的测试时间窗口,开发完成后,少量的自测即可上线。所以一切以最小代码为目标。在极端情况下,例如团队只有2-3人,只有master分支也未尝不可。走的流程就是TAG,出包,测试,上线。
2. 有专职测试的项目团队:dev+ release +master分支,或者 feature + dev + master分支。在有专业测试的团队里,在项目的(或每个迭代的)后期大量的测试任务都是在测试团队完成,这时开发团队会进行新的功能的开发。如果我们只有dev+master模式,在测试的后期,如果把新功能提交到dev分支的话,就会对bug fix的merge造成污染。所以我们需要在这个阶段有三个分支,除了dev 和master分支外,要增加 replease 分支来对应当前迭代/ 版本的bug fix。
3. 产品团队:master + 版本维护分支或者dev + master +版本维护分支。
客户化部署的多版本产品维护:
为什么要这么分呢?如下图所示,Git flow里其实是假设2.0永远比1.X的版本要新。
但真实情况里并不是如此,举一个简单的例子, Python 2.7.16就是比绝大多数的3.X的版本要新。在这种情况下,我们就需要版本的维护分支了。整个情况如下图所示:

由上图可以看到,如果是个产品型的团队,其实情况反而要比DevOps的情况复杂的多的多。以上图为例,在1.0对外发布之前,一切都很简单。只有master和Develop,和DevOps也差不多。到了1.0甚至2.0发布之后,情况变的越来越复杂了:
1. Dev-1 merge到Master,经过测试之后,可以发布1.0 版本,在Master上打上Tag
2. 可以在Develop上继续开发,前进到Dev-2
3. 在1.0发布之后,如果用户报了问题,那么需要从1.0的TAG打出分支,进行修复,发布1.1。
4. 与此同时,这个bugfix的代码还要回到Dev分支,在Develop 分到上得到Dev-3
5. 开发人员继续开发,在Develop上得到Dev-4,经过测试,merge到主干,验证后可以对外发布2.0版本
6. 此时再报Bug,首先要判断是在1.0上的代码导致 的,还是仅影响2.0版本。假设仅影响2.0版本,那么需要从2.0 上分支,然后进行bug fix得到2.1版本。再merge回develop,得到Dev-5
7. 如果这个bug是由于1.0上的代码影响,那么需要从1.x进行修复。在图上这样的情况,从1.1修复,得到1.2版本。但此时要向Develop和2.x分支merge,在2.x分支上发布2.2版本;merge回developt得到Dev-6
从上面这些描述可以看到,如果是一个维护多分支多版本的产品,会面临更多更复杂的情况。例如,原则上维护分支是不接受新功能的开发的,新功能的开发必须在develop上分支进行。那如果在上图的结束时间点上,有一个重点客户还在使用1.2版本,而且他们也不愿意做大版本升级到2.2版本。但这个客户提了一个非常小的需求,如果不满足他就会投向友商。此时应该怎么做呢?似乎又来了一个灵魂之问,对于开发团队来说,Bug和需求真正的区别在哪里呢?
关于Protected分支:
在GitLab的项目设置里,有开放分支和保护分支的说法,保护分支是不允许提交/推送(commit/push)代码,只允许 merge代码,并可以通过Web界面来审核 merge request。在git flow 的建议里,一般像1.x和2.x 是设置成保护分支,需要再额外分支和增加merge request。产品型的团队可以根据自己的情况来设置是否需要在维护分支上设置protected 标志。
在Master上是否要测试?
答案是肯定的。在《Kubernetes如何加速UCloud内部代码部署的CI/CD流程》一文也提到了相应的过程

则开发流程为:
1. 首先,在 Gitlab 上创建了编号为80的Issue,跟进这个optimize-allocate的feature;
2. 从dev分支创建一个新分支,名为feature/80-optimize-allocate,在该分支上进行开发;
3. 在feature/80-optimize-allocate上开发完成,进行commit,此时会触发静态测试、单元测试、Review等Pipeline Job;
4. 测试通过后,创建一个从feature/80-optimize-allocate到dev的merge request,由负责人进行审核。审核通过并且merge成功后,触发静态测试、单元测试、镜像构建、镜像部署、集成测试等Pipeline Job;
5. 测试通过后,创建一个从dev到master的mergerequest,由负责人进行审核。审核通过并且merge成功后,负责人创建tag v1.1.1,然后触发静态测试、单元测试、镜像构建、镜像部署、集成测试等Pipeline Job;
注:版本号tag是有命令规范的,v{x}.{y}.{z}代表着v{主版本}.{次版本}.{小修订版本}
最后,我想说的是,流程必须为自己团队/公司的工作而服务的。在实际的工作中,除了面临自己产品和公司的流程的问题外,可能还会面临诸如团队人员素质等更为复杂的情形。具体采取什么样的方式还是要根据团队的实际情况来制定相应的工作流程。流程无对错,适合最重要。
参考资料
1. https://nvie.com/posts/a-successful-git-branching-model/ 英文原文 2010-1-5
2. https://blog.csdn.net/shuzheng520/article/details/84906515 基于gitflow的开发上线流程
3. https://blog.csdn.net/liubenlong007/article/details/69372348 Git 在团队中的最佳实践--如何正确使用Git Flow
4.DevOps: 项目多环境配置和健康检查
5. https://blog.csdn.net/master_yao/article/details/78622648 使用gitlab做git flow及代码审查
6.Kubernetes如何加速UCloud内部代码部署的CI/CD流程UCloud技术