本文原文:JavaScript引擎基础:外形和内联缓存
推荐去本文原文看,丫的图片太小了,,emmm
本文介绍了所有JavaScript引擎通用的一些关键基础原理 - 而不仅仅是作者(Benedikt和Mathias)所使用的V8引擎。作为JavaScript开发人员,深入了解JavaScript引擎的工作原理可以帮助你了解代码的性能特征。
注意: 如果你更喜欢观看演示文稿而不是阅读文章,那么请欣赏下面的视频!如果没有,请跳过视频并继续阅读。
点击观看
JavaScript引擎管道(pipeline)
这一切都始于你编写的JavaScript代码。JavaScript引擎 解析 源代码并将其 转换为 抽象语法树(AST)。基于该AST,解释器可以开始做它的事情并 产生 字节码。很棒!此时引擎实际上正在运行JavaScript代码。

为了使它运行得更快,可以将字节码连同分析数据(profiling data)一起发送给优化编译器(optimizing compiler)。优化编译器根据它所拥有的分析数据做出一定的假设,然后生成高度优化的机器码。
如果在某一时刻其中一个假设被证明是不正确的,那么优化编译器就会去优化(deoptimizes)并返回到解释器。
JavaScript引擎中的解释器/编译器 管道(pipelines)
现在,让我们放大这个管道中实际运行JavaScript代码的部分,即代码得到解释和优化的部分,并讨论主要JavaScript引擎之间的一些差异。
一般来说,有一个包含解释器和优化编译器的管道。解释器快速生成未经过优化的字节码(bytecode),而优化编译器需要更长的时间,但最终生成高度优化的机器码。

这个通用管道几乎就是V8(Chrome和Node.js中使用的JavaScript引擎)的工作原理:

V8中的解释器称为 Ignition ,负责生成和执行字节码。当它运行字节码时,它收集分析数据,这些数据可用于稍后加速执行。当一个函数变得热(hot)时,例如当它经常运行时,生成的字节码和分析数据被传递给TurboFan ,我们的优化编译器,根据分析数据生成高度优化的机器码。

SpiderMonkey是Mozilla在Firefox和SpiderNode中使用的JavaScript引擎,它有点不同。它们有两个优化编译器,而不是一个。解释器优化到Baseline编译器,基线编译器会生成一些优化的代码。结合运行代码时收集的分析数据,IonMonkey编译器可以生成高度优化的代码。如果推测优化失败,IonMonkey将回退到Baseline代码。
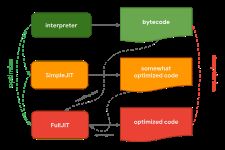
微软的JavaScript引擎Chakra在Edge和Node-ChakraCore中都使用了类似的设置,它有两个优化编译器。解释器优化为SimpleJIT (JIT代表即时编译器 -- Just-In-Time),后者生成一些优化的代码。结合分析数据,FullJIT可以生成更加优化的代码。

JavaScriptCore(缩写为JSC)是苹果在Safari和React Native中使用的JavaScript引擎,它使用了三种不同的优化编译器,将JavaScript发挥到了极致。底层解释器LLInt优化到Baseline编译器,然后Baseline编译器优化到DFG(数据流图)编译器,DFG又优化到FTL(比Light(光)更快)编译器。
为什么有些引擎比其他引擎有更多的优化编译器?一切都是为了权衡取舍。解释器可以快速生成字节码,但字节码通常效率不高。另一方面,优化编译器需要更长的时间,但最终会生成更高效的机器码。快速运行代码(解释器)或花费更多时间,但最终以最佳性能运行代码(优化编译器)之间存在权衡。一些引擎选择添加具有不同时间/效率特性的多个优化编译器,从而以额外的复杂性为代价对这些权衡进行更细粒度的控制。另一个权衡与内存使用有关;有关详细信息,请参阅我们的后续文章。
我们刚刚强调了解释器的主要区别,并优化了每个JavaScript引擎的编译器管道。但是除了这些差异之外,在高层次上,所有JavaScript引擎都具有相同的体系结构 :有一个解析器和某种解释器/编译器管道。
JavaScript的对象模型
让我们通过放大某些方面的实现来看看JavaScript引擎还有什么共同之处。
例如,JavaScript引擎如何实现JavaScript对象模型,以及它们使用哪些技巧来加速访问JavaScript对象上的属性?事实证明,所有主要引擎都实现了非常类似的功能。
ECMAScript规范本质上将所有对象定义为字典,字符串键映射到property attributes。
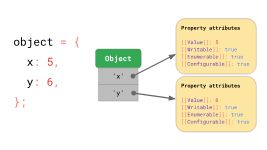
除了[[Value]]本身,规范还定义了以下属性:
-
[[Writable]]确定是否可以重新分配属性, -
[[Enumerable]]它决定了属性是否出现在for-in循环中, -
[[Configurable]]它决定了是否可以删除该属性。
[[双方括号]]表示法看起来很时髦,但这就是规范表示不直接暴露给JavaScript的属性的方式。你仍然可以使用Object.getOwnPropertyDescriptor API获取JavaScript中任何给定对象和属性的这些属性:
const object = { foo: 42 };
Object.getOwnPropertyDescriptor(object, "foo");
// → { value: 42, writable: true, enumerable: true, configurable: true }
好的,这就是JavaScript定义对象的方式。那么数组是怎么样的?
你可以将数组视为对象的特殊情况。一个区别是数组对数组索引有特殊的处理。这里数组索引(array index)是ECMAScript规范中的一个特殊术语。JavaScript中的数组仅限于2³²-1项。数组索引是该限制内的任何有效索引,即0到2³²-2之间的任何整数。
另一个不同之处在于数组还有一个神奇的length属性。
const array = ["a", "b"];
array.length; // → 2
array[2] = "c";
array.length; // → 3
在此示例中,数组在创建时的length为2。然后我们将另一个元素分配给索引2,并且length自动更新。
JavaScript定义数组类似于对象。例如,包括数组索引在内的所有键都显式地表示为字符串。数组中的第一个元素存储在键"0"下。

'length'属性只是另一个属性,它恰好是不可枚举且不可配置的。
一旦元素被添加到数组中,JavaScript将自动更新'length'属性的[[Value]]属性。
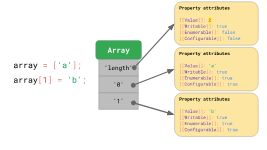
一般来说,数组的行为与对象非常相似。
优化属性访问
现在我们已经知道了对象是如何在JavaScript中定义的,接下来让我们深入了解JavaScript引擎如何有效地使用对象。
纵观JavaScript程序,访问属性是目前最常见的操作。对于JavaScript引擎来说,快速访问属性是至关重要的。
const object = {
foo: "bar",
baz: "qux"
};
// Here, we’re accessing the property `foo` on `object`:
doSomething(object.foo);
// ^^^^^^^^^^
形状(Shapes)
在JavaScript程序中,多个对象具有相同的属性键是很常见的。这样对象有相同形状(shape)。
const object1 = { x: 1, y: 2 };
const object2 = { x: 3, y: 4 };
// `object1` and `object2` have the same shape.
在具有相同形状的对象上访问相同属性也很常见:
function logX(object) {
console.log(object.x);
// ^^^^^^^^
}
const object1 = { x: 1, y: 2 };
const object2 = { x: 3, y: 4 };
logX(object1);
logX(object2);
考虑到这一点,JavaScript引擎可以根据对象的形状优化对象属性访问。这就是它的工作原理。
假设我们有一个具有x和y属性的对象,它使用我们前面讨论过的字典数据结构:它以字符串的形式包含键,这些键指向各自的属性。

如果你访问某个属性,例如object.y,JavaScript引擎在JSObject中查找键'y',然后加载相应的属性,最后返回[[Value]]。
但是这些属性存储在内存中的什么地方呢? 我们应该将它们存储为JSObject的一部分吗? 如果我们假设我们稍后会看到更多具有此形状的对象,那么将包含属性名称和属性的完整字典存储在JSObject本身上是很浪费的,因为具有相同形状的所有对象重复属性名称。这是大量的重复和不必要的内存使用。作为一种优化,引擎分别存储对象的Shape。
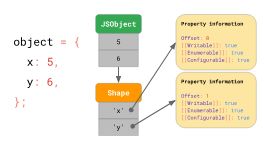
这个Shape包含所有的属性名和属性,除了它们的[[Value]]。相反,该Shape包含JSObject内部值的偏移量,以便JavaScript引擎知道在哪里可以找到这些值。每个具有相同形状的JSObject都指向这个Shape实例。现在,每个JSObject只需要存储这个对象特有的值。
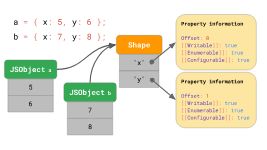
当我们有多个对象时,好处就很明显了。无论有多少对象,只要它们具有相同的形状,我们只需存储一次形状和属性信息!
所有的javascript引擎都使用形状作为优化,但它们并不都称之为形状:
- 学术论文称它们为 隐藏类 (混淆了的w.r.t. JavaScript类)。
- V8称他们为Maps (混淆了w.r.t. JavaScript
Map) - Chakra称它们为类型(混淆了w.r.t.JavaScript的动态类型和
typeof) - JavaScriptCore称它们为 Structures
- SpiderMonkey将它们称为 Shapes
在整篇文章中,我们将继续使用术语 形状(shapes)。
Transition chains and trees(过渡(转换)链和树)
如果你有一个具有特定形状的对象,但是你给它添加了一个属性,会发生什么? JavaScript引擎如何找到新形状?
const object = {};
object.x = 5;
object.y = 6;
这些形状在JavaScript引擎中形成所谓的 过渡链 。这里有一个例子:

该对象在没有任何属性的情况下开始,因此它指向空的形状。下一条语句向该对象添加一个值为5的属性'x',因此JavaScript引擎转换为一个包含属性'x'的形状,并在第一个偏移量为0时将值5添加到JSObject。下一行添加一个属性'y',因此引擎转换为另一个包含'x'和'y'的形状,并将值6附加到JSObject(偏移量为1)。
注意: 添加属性的顺序会影响形状。例如,{x: 4, y: 5}导致与{y: 5, x: 4}不同的形状。
我们甚至不需要为每个Shape存储完整的属性表。相反,每个Shape只需要知道它引入的新属性。例如,在本例中,我们不必在最后一个形状中存储有关'x'的信息,因为它可以在链的前面找到。为了使这个工作,每个Shape链接回到之前的形状:
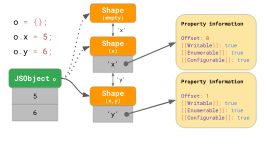
如果在JavaScript代码中编写o.x,JavaScript引擎会通过沿转换链向上查找属性'x',直到找到引入属性'x'的Shape。
但是如果没有办法创建一个过渡链,会发生什么? 例如,如果你有两个空对象,并为每个对象添加不同的属性,该怎么办?
const object1 = {};
object1.x = 5;
const object2 = {};
object2.y = 6;
在这种情况下,我们必须要一个分支,而不是链,我们最终得到一个过渡树(transition tree):

在这里,我们创建一个空对象a,然后向其中添加属性'x'。我们最终得到一个包含单个值的JSObject和两个Shapes:空的形状,以及只有x属性的形状。
第二个示例也以空对象b开头,但随后添加了不同的属性'y'。我们得到两个形状链,总共三个形状。(译者: 三个就是一个空的以及包含x和y的两个)。
这是否意味着我们总是从空的形状开始?不必要。引擎对已经包含属性的对象字面量应用了一些优化。假设我们要么从空对象字面量开始添加x,要么有一个已经包含x的对象字面量:
const object1 = {};
object1.x = 5;
const object2 = { x: 6 };
在第一个例子中,我们从空的形状开始并转换到也包含x的形状,就像我们之前看到的那样。
在object2的情况下,直接生成从头开始已经有x属性而不是从空对象开始并转换的对象是有意义的。
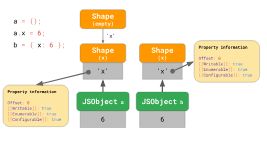
包含属性'x'的对象字面量从包含'x'的形状开始,有效地跳过了空形状。这就是V8和SpiderMonkey所做的(至少)。这种优化缩短了转换链,使从字面构造对象更加有效。
我之前关于React应用程序中令人惊讶的多态性的博客文章讨论了这些微妙之处如何影响实际性能。
下面是一个具有属性'x'、'y'和'z'的3D 对象的示例。
const point = {};
point.x = 4;
point.y = 5;
point.z = 6;
如前所述,这将创建一个内存中有3个形状的对象(不包括空形状)。要访问该对象上的属性'x',例如如果你在程序中编写point.x,JavaScript引擎需要遵循链表:它从底部的Shape开始,然后向上移动到顶部引入'x'的Shape。
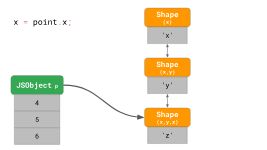
如果我们经常这样做,那将会非常慢,尤其是当对象有很多属性的时候。找到该属性的时间是O(n),即对象上的属性数量是线性的。为了加快搜索属性,JavaScript引擎添加了一个ShapeTable数据结构。此ShapeTable是一个字典,将属性键映射到引入给定属性的相应形状。
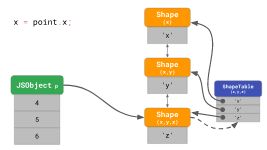
等一下,现在我们回到了字典查找……这是我们开始添加Shape之前的位置! 那么为什么我们要为形状烦恼呢?
原因是,形状支持另一种称为内联缓存( Inline Caches)的优化。
Inline Caches (ICs)
形状背后的主要动机是内联缓存或IC的概念。IC是使JavaScript快速运行的关键因素!JavaScript引擎使用IC来记忆关于在何处查找对象属性的信息,从而减少昂贵的查找次数。
这是一个函数getX,它接受一个对象并从中加载属性x:
function getX(o) {
return o.x;
}
如果我们在JSC中运行此函数,它会生成以下字节码:
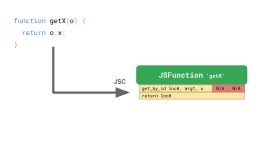
第一个get_by_id指令从第一个参数(arg1)加载属性'x',并将结果存储到loc0中。JSC还将内联缓存嵌入get_by_id指令,该指令由两个未初始化的槽组成。
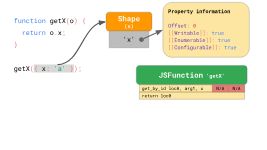
在让我们假设我们用一个对象{x: 'a'}作为参数调用getX。据我们了解,此对象具有属性为'x'的形状,而Shape存储该属性x的偏移量和属性。当你第一次执行该函数时,get_by_id指令会查找属性'x'并发现该值存储在偏移量0处。

嵌入到get_by_id指令中的IC会记住找到属性的形状和偏移量:

对于后续运行,IC只需要比较形状,如果它与以前相同,只需加载记忆偏移量的值。具体地说,如果JavaScript引擎看到的对象具有IC之前记录的形状,那么它就根本不需要访问属性信息——相反,可以完全跳过昂贵的属性信息查找。这比每次查看属性要快得多。
有效地存储数组
对于数组,通常存储属性为数组索引 。这些属性的值称为数组元素。为每个数组中的每个数组元素存储属性在内存上是很浪费的。相反,JavaScript引擎使用的事实是,默认情况下,数组索引的属性是可写的、可枚举的和可配置的,并且将数组元素与其他命名属性分开存储。
考虑这个数组:
const array = ["#jsconfeu"];
引擎存储数组长度(1),并指向包含偏移量的形状和'length'属性。

这与我们之前看到的类似......但数据值存储在哪里?

每个数组都有一个单独的元素支持存储,其中包含所有数组索引的属性值。JavaScript引擎不必存储数组元素的任何属性,因为它们通常都是可写,可枚举和可配置的。
但是在不寻常的情况下会发生什么?如果更改数组元素的属性怎么办?
// Please don’t ever do this!
const array = Object.defineProperty([], "0", {
value: "Oh noes!!1",
writable: false,
enumerable: false,
configurable: false
});
上面的代码片段定义了一个名为'0'的属性(恰好是一个数组索引),但将其属性设置为非默认值。
在这种情况下,JavaScript引擎将整个支持存储的元素表示为字典,将数组索引映射到属性。

即使只有一个数组元素具有非默认属性,整个数组的后备存储也会进入这种缓慢且低效的模式。在数组索引上避免Object.defineProperty ! (我不知道你为什么要这么做。这似乎是一件奇怪而无用的事情。)
结论
我们已经了解了JavaScript引擎如何存储对象和数组,以及形状和IC如何帮助优化它们的常见操作。基于这些知识,我们确定了一些有助于提高性能的实用JavaScript编码技巧:
- 始终以相同的方式初始化对象,这样它们就不会有不同的形状。
- 不要打乱数组元素的属性,这样可以有效地存储和操作它们。
想寻找更多?如果你对JavaScript引擎如何加速对原型属性的访问感兴趣,请阅读本系列的下一篇文章 “JavaScript引擎基础:优化原型”。
译:结束语
V8的解释器叫做 Ignition ,负责生成和执行字节码。
JSObject是什么?点击查看
可以看下这个React应用程序中的影响
本文原文: JavaScript engine fundamentals: Shapes and Inline Caches