介绍
当前主流的CNN目标检测框架可分为两类:包含Region proposals提取阶段的两阶段目标检测框架如R-CNN系列像R-CNN/Fast-RCNN/Faster-FCNN/R-FCN等;端到端的单阶段目标检测框架如Yolo系列像Yolo-v1/Yolo-v2/Yolo-v3及SSD,和最近Facebook提出的RetinaNet等。简单说来两阶段的检测框架相对准确率(mAP值)更高,但其速度较慢,很难满足图片或视频实时性处理要求;单阶段的检测框架相对准确率较低,但却能在保证一定准确率的情况下,拥有更快、甚至实时的推理速度,因此在现实工程实践中也获得了较多的应用。
Yolo系列模型是比较典型的端到端的单阶段目标检测模型。凭着较快的速度及轻便的特性已经在端侧目标检测领域中得到了较大规模的应用。本系列文章里面我们将从最早的Yolo-v1开始,逐步分析下此系列模型是如何逐渐迭代发展的。
Yolo概述
如前文所讲,Yolo是一种端到端的目标检测网络。它以resize过后的图片为输入,经过前端的CNN特征提取网络后,在生成的feature maps之上再使用CNN/Average Pool等层对特征进一步融合、整理,然后由后接的两个fc层来直接生成图片上每个位置节点所涵盖的潜在目标的类别、位置及置信度等信息。最后再对这些潜在的目标以其置信度信息来进行过滤(即传说中的极大值抵制,non-maximum suppression,NMS),以减少重复、冗余的目标框数目进而加速并改良后须的loss值计算。总之它是一个由图片输入到图片之上目标输出的端到端回归模型。下图是Yolo目标检测框架的概括描述。

Yolo详解
- 模型流水过程
Yolo会将输入的图片划分为SxS的空间区域。然后模型会在每个空间节点(i,j; 0 <= i <= S, 0 <= j <= S)上检测固定大小/分辨率的B个boxes。检测的东西共有三样:1)此节点上每个box所可能包含潜在目标的概率大小即置信度(Pr(Object) ∗ IOUpredtruth);2)此节点上每个box所具有的位置(即中心点x,y与box的h,w);3)每个节点上潜在目标归属类别的概率分步(即Pi,0 <= i <= C,C为所有可能的类别数目)。
在部署训练好的模型时,结合网络前向推理后生成的每个节点上的此三样信息就能得到最终的检测目标。下图可看出此一详细流水过程。
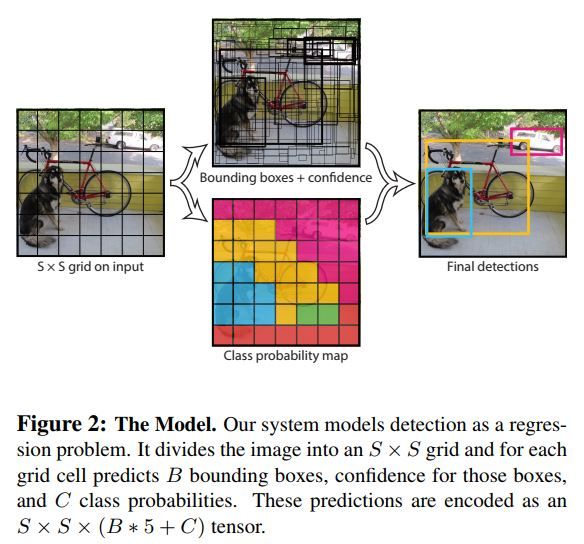
- 模型网络结构
在Yolo模型中,作者采用了自己创造的Darknet作为其图片特征处理主干网络。它的思想有些借鉴Googlenet,即通过使用1x1的Conv层来减少filters数目并整合各个输出channels的特征。下图为它的基本框架。此基本框架中共包含24个Conv层,其后又连接了两个FC层来生成上文所提到的基本信息。作者有试着减少Conv层的数目为9,并同时减少Conv层中所具有的filters的数目,最终生成了一个准度稍降但速度更快的fast-Yolo模型。

论文中作者使用了S=7,B=2,而PASCAL VOC数据集共有20类,所以最终预测的模型输出为(7x7x(2x5 + 20)的Tensor。
- 模型训练
训练与推理的最大区别,在于我们需要提出一个合理的loss,才能让模型得以按照我们的想法去进行迭代优化。如下为Yolo的loss计算公式。
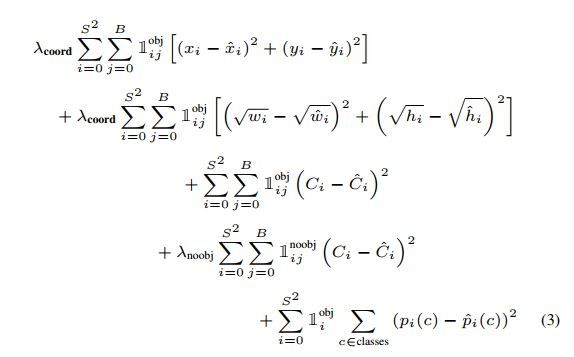
跟R-CNN一样,它主要由两部分组成即反映类别信息的Classification loss及反映目标检测框位置信息的localization loss。不过此外它还包含了反映目标框置信度信息的loss(此部分loss与RPN网络的confidential loss相似,其的作用也大致相同)。为了抵制过多的background目标框会使得那些真正有意义的、包含有明确物体的目标框信息被湮没,作者使用了外在的系数λcoord = 5 和 λnoobj = 0.5来人为对之做出纠正。这确实是它非常丑的地方,毕竟每一个需要手动调节的超参的加入都会直接导致一个模型的使用难度加大。
- 模型推理
Yolo这种单阶段目标检测模型的推理异常简单,只需要对train好的模型作一次前向推理即能得到输入图片之上的目标类别及其位置。
在VOC数据集上,一次前向推理每张图片可得到98个目标检测框及它们所对应的类别概率分布。在模型输出的最后一般我们会对生成的多个boxes进行NMS处理以减少重复、冗余的目标框数目。此方法在R-CNN系列模型中亦得到过检验,可以有效地提升模型性能及准确度。
- Yolo的缺陷
由于Yolo通过直接在image level上划分grid区域,然后每个区域指定固定数目的boxes,再对这些boxes作回归检测、分析,这可能会导致它不大能处理不同scales的目标。实验表明它在处理很小的群体目标时性能极差。同时它对那些固定数目boxes之外的其它新的分辨率模型检测效果也不好。显然加大每个Grid上不同size/aspect ratio的boxes数目可以比较有效地解决此一问题,但如此以来又会导致其引以为傲的速度性能大打折扣。
此外因为它仅使用最后一层的抽象CNN特征来得到目标框的位置、类别等信息,因此生成出的目标框不够细化。
最后它的training loss计算中对不同大小的目标框一视同仁,不加区分。这导致它不能较好的对待小尺度的目标框。实验表明localization error较大是它精度相对于Faster-FCNN模型不高的主要因素。
Yolo与其它检测模型的比较
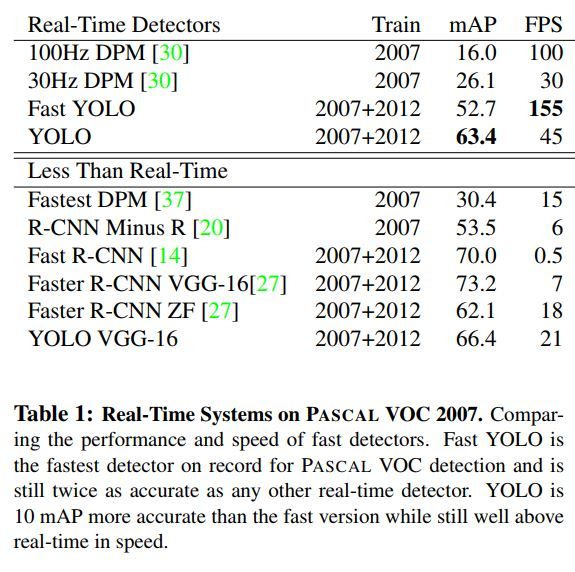
与Faster-RCNN等两阶段检测框架相比,Yolo检测性能不如,但胜在速度较快,可满足实时性要求。与其它的号称实时检测框架如DPM等相比,Yolo在速度不落下风的同时,性能又可保持较高。下表为Yolo与其它检测模型的实验结果比较。
代码分析
在cfg/yovov1.cfg里面作者定义了darknet及yovov1 network head的结构。若我们只关注模型本身,那么只看此配置文件即可,没必要去费精力了解darknet是如何解析其配置文件的。
如下为darknet在训练与推理时分别具有的输入配置及其它超参数。
[net]
# Testing
batch=1
subdivisions=1
# Training
# batch=64
# subdivisions=8
height=448
width=448
channels=3
momentum=0.9
decay=0.0005
saturation=1.5
exposure=1.5
hue=.1
learning_rate=0.0005
policy=steps
steps=200,400,600,20000,30000
scales=2.5,2,2,.1,.1
max_batches = 40000
以下为darknet特征提取网络中间的若干conv层。。可看出3x3与1x1网络相互穿插的结构特点。此外较为特殊的是它的activation函数用的都是leaky ReLu。另外1x1的conv也会使用pad(为1)。
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
darknet主干网络的最后又添加了几个Conv层,用于特征细化,这对于pre-trained后的网络进行迁移学习非常有必要。
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=1024
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=2
pad=1
filters=1024
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=1024
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=1024
activation=leaky
[local]
size=3
stride=1
pad=1
filters=256
activation=leaky
最后就是最终的fc层及后须的位置、类别、置信度等信息提取。
[dropout]
probability=.5
[connected]
output= 1715
activation=linear
[detection]
classes=20
coords=4
rescore=1
side=7
num=3
softmax=0
sqrt=1
jitter=.2
object_scale=1
noobject_scale=.5
class_scale=1
coord_scale=5
参考文献
- You Only Look Once: Unified, Real-Time Object Detection, Joseph-Redmon, 2015
- https://pjreddie.com/darknet/yolov1/