好久没有更新博客,国庆7天,宿舍就我一个人,人生真的寂寞如雪啊。
想起我之前看过一本数据分析的书,今天想来实战一下。之前由于误删了网络爬虫爬下来的数据,所以只能重新爬取一次了,不过这次就抓取点好玩的东西,爬取淘宝淘女郎的信息来做一个简单的数据分析。
先上爬虫代码:
#coding:utf-8
import requests
import os
from multiprocessing.dummy import Pool as ThreadPool
import time
from bs4 import BeautifulSoup
import urllib2,urllib
import re
class MM:
def __init__(self):
self.baseurl='https://mm.taobao.com/json/request_top_list.htm?page='
self.pool = ThreadPool(10) #初始化线程池
self.headers={'Accept-Language':'zh-CN,zh;q=0.8','User-Agent':'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.116 Safari/537.36','Connection':'close','Referer': 'https://www.baidu.com/'}
def indexPage(self,index):
indexpage=requests.get(self.baseurl+str(index),headers=self.headers)
return indexpage.content.decode('GBK')
def getAlldetail(self,index):
indexpage=self.indexPage(index)
p=re.compile(r'class="lady-avatar".*?) (.*?).*?(.*?).*?(.*?)',re.S)
alldetail=re.findall(p,indexpage)
eachdetail=[]
for eachmm in alldetail:
eachdetail.append(['http:'+eachmm[0],eachmm[1],eachmm[2]+'years old',eachmm[3]])
return eachdetail
def getImg(self,filename,imgaddr):
f=open('mm/'+filename+'/'+filename+'.jpg','wb+')
f.write(requests.get(imgaddr,headers=self.headers).content)
f.close()
def getContent(self,filename,content):
with open('mm/'+filename+'/'+filename+'.txt','w+') as f:
for each in content:
f.write((each.encode('utf-8'))+'\n')
def mkdir(self,path):
path = path.strip()
isExists=os.path.exists(path)
if not isExists:
# 如果不存在则创建目录
print u"新建了名字叫做",path,u'的文件夹'
# 创建目录操作函数
os.makedirs(path)
return True
else:
# 如果目录存在则不创建,并提示目录已存在
print u"名为",path,'的文件夹已经创建'
return False
def savePageInfo(self,index):
alldetail=self.getAlldetail(index)
for eachdetail in alldetail:
self.mkdir('mm/'+eachdetail[1])
#self.mkdir('mm/')
self.getImg(eachdetail[1],eachdetail[0])
self.getContent(eachdetail[1],eachdetail[1:])
def start(self):
while 1:
try:
start=int(raw_input('开始查询的页数(整数):'))
end=int(raw_input('结束的页数(整数):'))
except Exception,e:
print e
else:
break
index=range(start,end+1)
begin=time.time()
try:
results = self.pool.map(self.savePageInfo,index)
self.pool.close()
self.pool.join()
except Exception as e:
print e
pass
end=time.time()
total=end-begin
print '总耗时:',total
if __name__=='__main__':
mm=MM()
mm.start()
(.*?).*?(.*?).*?(.*?)',re.S)
alldetail=re.findall(p,indexpage)
eachdetail=[]
for eachmm in alldetail:
eachdetail.append(['http:'+eachmm[0],eachmm[1],eachmm[2]+'years old',eachmm[3]])
return eachdetail
def getImg(self,filename,imgaddr):
f=open('mm/'+filename+'/'+filename+'.jpg','wb+')
f.write(requests.get(imgaddr,headers=self.headers).content)
f.close()
def getContent(self,filename,content):
with open('mm/'+filename+'/'+filename+'.txt','w+') as f:
for each in content:
f.write((each.encode('utf-8'))+'\n')
def mkdir(self,path):
path = path.strip()
isExists=os.path.exists(path)
if not isExists:
# 如果不存在则创建目录
print u"新建了名字叫做",path,u'的文件夹'
# 创建目录操作函数
os.makedirs(path)
return True
else:
# 如果目录存在则不创建,并提示目录已存在
print u"名为",path,'的文件夹已经创建'
return False
def savePageInfo(self,index):
alldetail=self.getAlldetail(index)
for eachdetail in alldetail:
self.mkdir('mm/'+eachdetail[1])
#self.mkdir('mm/')
self.getImg(eachdetail[1],eachdetail[0])
self.getContent(eachdetail[1],eachdetail[1:])
def start(self):
while 1:
try:
start=int(raw_input('开始查询的页数(整数):'))
end=int(raw_input('结束的页数(整数):'))
except Exception,e:
print e
else:
break
index=range(start,end+1)
begin=time.time()
try:
results = self.pool.map(self.savePageInfo,index)
self.pool.close()
self.pool.join()
except Exception as e:
print e
pass
end=time.time()
total=end-begin
print '总耗时:',total
if __name__=='__main__':
mm=MM()
mm.start()
运行后输入你要爬取的页面,就能把淘女郎的年龄,居住地,名字和照片给爬取下来。一共有4万多个淘女郎信息,你可以全部爬取下来做数据分析用。
我只爬了几十页,运行后截图:

1.png
随便打开一个目录,可以看到图片和信息。
由于代码是很久之前写的,当时并没有想到做数据分析,因此我对每个人都创建了一个目录,每个目录存放个人信息,这样再单独写个脚本进入每个文件获取信息效率不高,我就直接在原脚本中获取并直接进行数据的图像可视化,代码如下:
#coding:utf-8
import matplotlib
import requests
import numpy as np
from matplotlib.font_manager import *
import matplotlib.pyplot as plt
import os
from multiprocessing.dummy import Pool as ThreadPool
import time
from bs4 import BeautifulSoup
import urllib2,urllib
import re
'''
#解决负号'-'显示为方块的问题
matplotlib.rcParams['axes.unicode_minus']=False
'''
myfont = FontProperties(fname='/usr/share/fonts/truetype/droid/DroidSansFallbackFull.ttf')
class MM:
def __init__(self):
self.bing={}
self.bing1=[]
self.zhu={}
self.zhu1=[]
self.baseurl='https://mm.taobao.com/json/request_top_list.htm?page='
self.pool = ThreadPool(10)
self.headers={'Accept-Language':'zh-CN,zh;q=0.8','User-Agent':'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.116 Safari/537.36','Connection':'close','Referer': 'https://www.baidu.com/'}
def indexPage(self,index):
try:
indexpage=requests.get(self.baseurl+str(index),headers=self.headers)
except Exception as e:
print e
return indexpage.content.decode('GBK')
def getAlldetail(self,index):
indexpage=self.indexPage(index)
p=re.compile(r'class="lady-avatar".*?(.*?).*?(.*?).*?(.*?)',re.S)
alldetail=re.findall(p,indexpage)
eachdetail=[]
for eachmm in alldetail:
eachdetail.append(['http:'+eachmm[0],eachmm[1],eachmm[2]+'years old',eachmm[3]])
return eachdetail
def getImg(self,filename,imgaddr):
#f=open('mm/'+filename+'/'+filename+'.jpg','wb+')
urllib.urlretrieve(imgaddr,'mm/'+filename+'/'+filename+'.jpg')
#f.write(requests.get(imgaddr,headers=self.headers).content)
#f.close()
def getContent(self,filename,content):
with open('mm/'+filename+'/'+filename+'.txt','w+') as f:
for each in content:
f.write((each.encode('utf-8'))+'\n')
def mkdir(self,path):
path = path.strip()
isExists=os.path.exists(path)
if not isExists:
# 如果不存在则创建目录
print u"新建了名字叫做",path,u'的文件夹'
# 创建目录操作函数
os.makedirs(path)
return True
else:
# 如果目录存在则不创建,并提示目录已存在
print u"名为",path,'的文件夹已经创建'
return False
def savePageInfo(self,index):
alldetail=self.getAlldetail(index)
for eachdetail in alldetail:
self.mkdir('mm/'+eachdetail[1])
#self.mkdir('mm/')
self.getImg(eachdetail[1],eachdetail[0])
self.getContent(eachdetail[1],eachdetail[1:])
def bing_pic(self,index):
alldetail=self.getAlldetail(index)
for eachdetail in alldetail:
if eachdetail[3] not in self.bing:
self.bing[eachdetail[3]]=1
else:
self.bing[eachdetail[3]]+=1
def zhu_pic(self,index):
alldetail=self.getAlldetail(index)
for eachdetail in alldetail:
eachdetail=eachdetail[2].replace('years old','')
if eachdetail not in self.zhu:
self.zhu[eachdetail]=1
else:
self.zhu[eachdetail]+=1
def start(self):
while 1:
try:
startpage=int(raw_input('开始查询的页数(整数):'))
endpage=int(raw_input('结束的页数(整数):'))
except Exception,e:
print e
else:
break
index=range(startpage,endpage+1)
begin=time.time()
try:
results = self.pool.map(self.savePageInfo,index)
self.pool.close()
self.pool.join()
except Exception as e:
print e
pass
end=time.time()
total=end-begin
print '总共耗时:',total
for i in range(startpage,endpage+1):
self.zhu_pic(i)
self.bing_pic(i)
#柱状图
for i in self.zhu:
self.zhu1.append(self.zhu[i])
sorted(self.zhu)
year=[]
for i in self.zhu:
year.append(i)
#print year,self.zhu1
plt.title(u'淘女郎年龄分布图',fontproperties=myfont,size=20)
plt.xlabel(u'年龄',fontproperties=myfont,size=20)
plt.ylabel(u'人数',fontproperties=myfont,size=20)
plt.bar(year, self.zhu1)
plt.show()
#饼状图
for i in self.bing:
self.bing1.append(self.bing[i])
group=[]
for i in self.bing:
group.append(i)
plt.figure(num=1, figsize=(12, 12))
plt.axes(aspect=1)
plt.title(u'淘女郎居住地分布图',fontproperties=myfont,size=20)
patches,l_text,p_text=plt.pie(self.bing1,labels=group,autopct = '%3.1f%%',shadow=True, startangle=90)
for t in l_text:
t.set_fontproperties(matplotlib.font_manager.FontProperties(fname="/usr/share/fonts/truetype/droid/DroidSansFallbackFull.ttf")) # 把每个文本设成中文字体
plt.show()
if __name__=='__main__':
mm=MM()
mm.start()
matplotlib这个中文不能显示这块有点恼火,它必须要指向一个可以显示中文的ttf文件才能显示中文,本脚本用的matplotlib是1.5版本的,如果是其他的版本可能会出现因为参数的不同而出错。
最后经过数据分析后的图片(以下是遍历了1到8页的信息后得到的图片,你们可以继续遍历......)
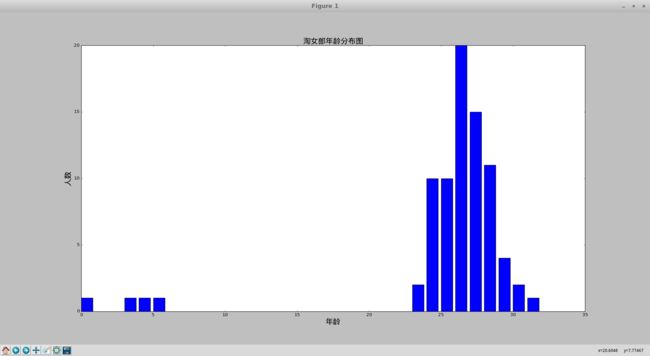
2016-10-08 19-38-09 的屏幕截图.png
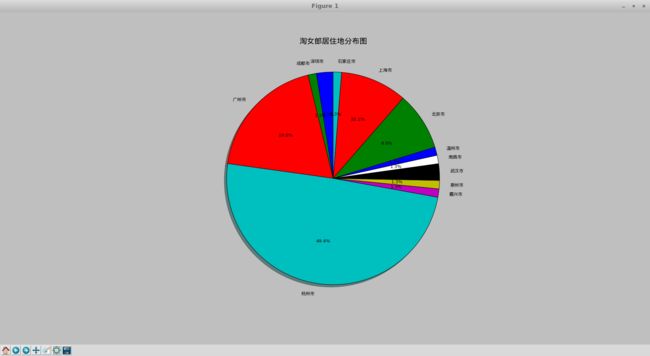
2016-10-08 19-38-40 的屏幕截图.png
这是数据分析的一点点皮毛,深入之后再继续玩儿......
欢迎大牛指正.......