因子分析概述:
因子分析分为Q型和R型,我们对R型进行如下研究:
一.因子分析步骤:
1.确认是是否适合做因子分析
2.构造因子变量
3.旋转方法解释
4.计算因子变量得分
二.因子分析的计算过程:
1.将原始数据标准化
目的:消除数量级量纲不同
2.求标准化数据的相关矩阵
3.求相关矩阵的特征值和特征向量
4.计算方差贡献率和累计方差贡献率
5.确定因子
F1,F2,F3...为前m个因子包含数据总量(累计贡献率)不低于80%。可取前m各因子来反映原评价
6.因子旋转
当所得因子不足以明显确定或不易理解时选择此方法
7.原指标的线性组合求各因子的得分
两种方法:回归估计和barlett估计法
8.综合得分:以各因子的方差贡献率为权,各因子的线性组合得到各综合评价指标函数
F=(λ1F1+…λmFm)/(λ1+…λm)
=W1F1+…WmFm
9.得分排序
因子分析详解:
因子分析模型,又名正交因子模型
X=AF+ɛ
其中:
X=[X1,X2,X3...XP]‘
A=

F=[F1,F2...Fm]'
ɛ=[ɛ1,ɛ2...ɛp]'
以上满足:
(1)m小于等于p
(2)cov(F,ɛ)=0
(3)Var(F)=Im
D(ɛ)=Var(ɛ)=
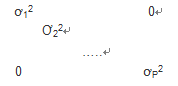
ɛ1,ɛ2...ɛp不相关,且方差不同
我们把F成为X公共因子,A为荷载矩阵,ɛ为X特殊因子
A=(aij)
数学上证明:aij就是i个变量与第j个因子的相关系数,参见层次分析法aij定义。
<1>荷载矩阵
就荷载矩阵的估计和解释方法有主因子和极大似然估计,我们就主因子分析而言:(是主因子不是主成份)
设随机向量X的协方差阵为Ʃ
λ1,λ2,λ3..>0为Ʃ的特征根
μ1,μ2,μ3...为对应的标准正交向量
我们大一学过线代或者高代,里面有个东西叫谱分析:
Ʃ=λ1μ1μ1’+......+λpμpμp’
=
当因子个数和变量个数一样多,特殊因子方差为0.
此时,模型为X=AF,其中Var(F)=Ip
于是,Var(X)=Var(AF)=AVar(F)A'=AA'
对照Ʃ分解式,A第j列应该是
也就是说,除了uj前面部分,第j列因子签好为第j个主成份的系数,所以为主成份法。
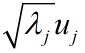
如果非要作死考虑ɛ
原来的协方差阵可以分解为:
Ʃ=AA'+D=
以上分析的目的;
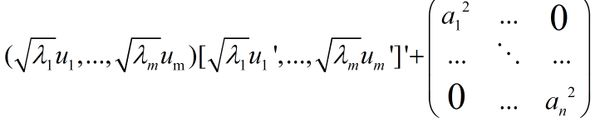
1.因子分析模型是描述原变量X的协方差阵Ʃ的一种模型
2.主成份分析中每个主成份相应系数是唯一确定的,然而因子分析中的每个因子的相应系数不是唯一的,因而我们的因子荷载矩阵不是唯一的
(主成分分析是因子分析的特例,非常类似,有兴趣的可以去看看,这两者非常容易混淆)
<2>共同度和方差贡献
无论是在spss或者R的因子分析中都围绕着贡献度,我们来看下,它到底是什么意思。
由因子分析模型,当仅有一个公因子F时,
Var(Xi)=Var(aiF)+Var(ɛi)
由于数据标准化,左端为1,右端分别为共性方差和个性方差
共性方差越大,说明共性因子作用越大。
因子载荷矩阵A中的第i行元素之平方和记为hi2
成为变量(Xi)共同度
它是公共因子对(Xi)的方差锁做出的贡献,反映了全部公共因子对变量(Xi)的影响。
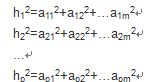
hi2大表明第i个分量对F的每一个分量F1,F2,...Fm的共同依赖程度大
将因子载荷矩阵A的第j列的各元素的平方和记为gj2
成为公共因子Fj对x的方差贡献。
gj2表示第j个公共因子Fj对x的每一个分量Xi所提供的方差的总和,他就是衡量公共因子的相对重要行的指标。gj2越大,表明公共因子Fj对x的贡献越大,或者说对x的影响和作用就越大。
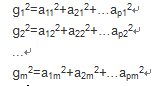
如果将载荷矩阵A的所有gj2都计算出来,按大小排列,就可以提炼最有影响力的公共因子。
<3>因子旋转
这方面涉及较为简单,我就简单提一下
目的:建立因子分析模型不是只要找主因子,更加重要的是意义,以便对实际进行分析,因子旋转就是使所得结论更加清晰的表示。
方法:正交旋转,斜交旋转两大类,常用正交。
便于理解,我解释下旋转的意义,以平面直角坐标系为例,我们想得到的数据正好为:y=x和y=-x上的点,我们能解释的却在x=0和y=0上,这时候我们就可以旋转坐标系,却不影响结果。