CALCULATE之庖丁解牛系列 -- CALCULATE专解(2)
友情提示:108式并不是全部为理论,最后一半是定义DAX公式解决业务场景的话题。
前面我们挺啰嗦地介绍了CALCUALTE构成我们计算需要的最重要的元度量。今后几乎所有的度量都将基于元度量为基础进行变化而来。
接着还介绍了隐式行筛选与显式列表筛选的行为在计算列、度量情形下的使用。通过学习两个最基本的元度量,说明你已经可以写出最初的两个公式:
[元度量_隐式]:= SUM(Sales[sale])
[元度量_显式]:= CALCULATE(SUM(Sales[sale]))
其实到这里,是DAX的一个分水岭,即使是现在还只是创建元度量,但你也可以只运用它就能解决大多数业务问题了。虽然很基础,让我们摸拟一下DAX运用的经典三部曲:
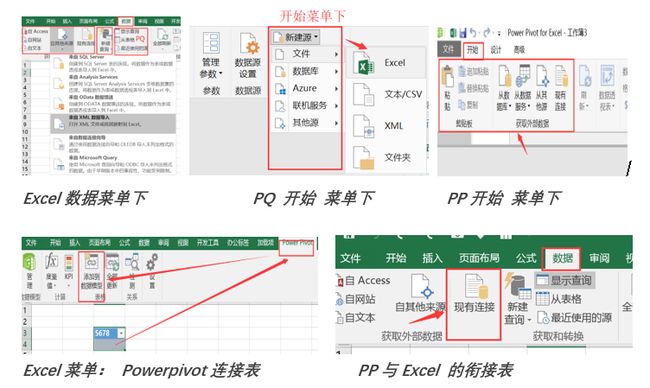
第一步:将需要的数据加载到Powerpivot或PowerBI里,成为特定的某个业务数据模型(单元性或系统性,将根据模型的扩展性而定)。当然,有这些导入数据的入口选择(可以导入几乎任何类型的数据):
第二步:在模型表的计算区域(数据区域下方的空白单元格区域,也可以使用Excel的PowerPivot菜单下的新建度量)。创建需要的最简单的元度量。这里,你可以直接选中某个需要计算的列:比如[销售额],然后选择自动汇总的方式(总和、计数、平均值等),如图:
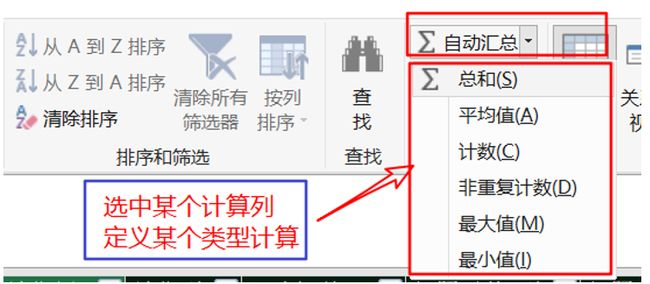
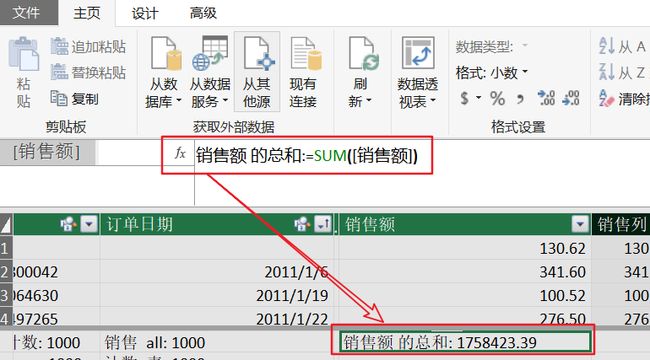
结果会直接在该列的下方单元格里生成一个度量,如果对默认的名称不满意,你可以修改它。
如果该表包含的列表,不能满足你的计算(筛选列表等),那就需要简单的建模(其实就是拖拽列表连线列表间的关系),如图:可参与计算的列表变得很多很多(例如老生常谈的透视表里的行、列、切片器用到的维度列表,DAX计算式里的参数列表等)。
第三步:拖拽出一个透视表,针对该度量:[销售额_的总和],给定一组列表筛选它,或者运用查询输出为链接回表……。以及其他的任何数据输出。
故事当然不会到此结束。让我们继续前行?
第7式:CALCULATE中的过程与结果都是列表
无需质疑:所有DAX数据模型都以列式存储,并以列式参与计算,并没有行的概念。所有DAX(即CALCULATE)都是关于列表的。
这是由DAX内部引擎原理决定的。任何关于DAX的理解都需要回到该定义。这可以认为是DAX中的一条语录。别忙着否定它,认识它比否定它更让你了解DAX。
那么,我们围绕这句DAX语录,总之是不会错的。让我们一步一步来。
先说下学习DAX中遇到的另一个问题:(以下所说的列表指代一个列或多个列,多个组合在一起的属性列表指代为表)。 由CALCULATE定义的DAX计算中操纵的永远是列表。依据是,DAX存在于数据模型中,而数据模型里的数据是以列式存储、列式执行的。重要的东西需要不止说三遍!
所以,DAX能识别的、能操作的永远只有列表(除非改变引擎存储方式),我们前面提到的“显式列表”概念也基于此。我们不是想把DAX的概念弄得“多多的复杂式”,而是“少少的简单式”。前提是有一个痛苦的啰嗦过程。
关于DAX(CALCULATE)的一切,甚至最后只剩下两个字:列表,或者最多四个字:列表+筛选。
为照顾到一些心急的读者,我们先列举个1、2、3、4。可能会一次性串烧到多个概念。
1、第一个问题。其实是不得不说的、关于“当前行”的问题,也就是“行上下文”。这其实不是对错的问题,而是中西方语境差异的问题,是最后没有回到DAX内部引擎的问题……。它像是“美丽的谎言”、难懂的“甲骨文”、“迷惑人的坑”,总之是“皇帝的新装”。注意,都是些带引号的。
(1)第一个问题与DAX技术无关,是想问:行上下文究竟是个什么鬼?能明明白白的告诉我们么?
因为自信多少对语文里的上下文理解一点,如是百度了一下编程中提到的上下文是个什么样子的,还真是有大神的回答:
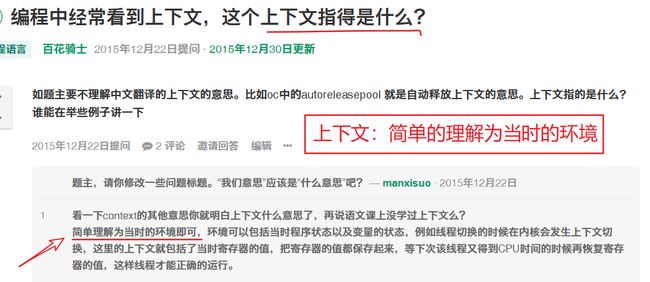

终于明白,编程的上下文指的就是:当时计算所在的环境。对于DAX当然是比较熟悉的:CALCULATE定义的行上下文和列表上下文所在的当前计算环境。如是,也有了:行上下文 =“当前行”。
问题是, DAX的函数语言要更强大一些,最终目的最好是变得像Excel的单元格一样最好,写一个函数公式,不用考虑一丁点、一丝丝的编程,就知道这个函数公式能计算出正确的结果(这么多年我们都是这么干的。写个Excel函数公式,我们也并没有观察过、或者想过它的“当前行”行为)。
现在可好,搞个抽象的编程语言,这对于毫无编程经验、手无寸铁的非IT人员来说,也应该是更不好理解。
你也许会说,Excel与DAX是两回事好不好。那好,我们就说DAX:
(2)就算是为了从编程语言上理解DAX的需要,可这还是有点“牛头不对马嘴”的味道?原谅我语气太重,我是被“上下文”搞晕了这么多年,已经忍无可忍,忍无可忍那就无须再忍!哈哈。说好的DAX注重业务逻辑(更像函数式语言),这可能会不算数?不能吧?
(3)为了更官方一点(以便你相信我一次),我只能请出大家还算信服的《DAX圣经》的一句结论:VertiPaq (DAX工作的数据模型里的引擎)是一个列式数据库。我们应该抛弃表的思考方式转而以列表的概念来理解它。
这应该是很清楚、很明白的一句话了,我们稍微变动一下,也就是说,其实 CALCULATE(DAX)的一切都是关于列表的。
这也是很多IT(搞编程的)人不一定学得好DAX的原因,因为他们习惯于总用表的概念来理解和运用DAX。
很显然,DAX的数据模型里本没有行,有的只是列表(哪怕只有一个数据行,那也是列表),没有行,哪来的行上下文?它其实就是:皇帝的新装,本来就没有嘛!
(4)问题来了,你先别急着骂我,我并没有说“行上下文”不好,而且现有的官方都采用这种方式来理解DAX,用哪一个词,并不重要,关键是能理解它,运用它就行。
感谢你耐着性子能看到这里,我是非官方,我想很平静的再接着聊一下为什么会使用“行筛选”而不是“行上下文”的原因。并不是想标新立异、独具一格。而是非得花多点文字才能搞清(即使暂时还不能太清晰,还需要后期的无数DAX案例检验)。
1)从字面上看,有“行上下文”就对应有“列表上下文”,前面已经说过,这比较偏重于编程(写DAX的、以及编辑学习DAX官方知识文档的,应该也大都是IT编程人员),这其实还是表的概念,它太注重于表的运行机制或者执行方式(即定义表的计算环境:定义表的关系主键、定义表的连接、定义查询条件等等)。
但是,如果以DAX的列表概念来理解,那就简单得多。首先找到要计算的列表,然后针对整列或该列的部分(列表筛选),最后可能需要按某个逻辑条件改变计算(行筛选)。这就是我们说的DAX的:筛选+计算。
这时候,我们不需要过多的考虑那么多的定义,也不需要太考虑列表关系:因为关系要不就是事先连接好的物理关系,只要不删除它,它总是存在的,要不就是由公式定义的关系等等。
总习惯纠虑关系,这可能是:前期建模架构不清晰、或对自己的数据模型包含哪些内容并不熟悉和不自信、亦或者是并不了解业务场景(对业务需要的度量、维度列表不熟)等等。所以,我们有:“业务逻辑高于分析工具本身"的说法。
2)关键的一点,也是绕不开的一点。我们太熟悉和关心的“行的行为”--所谓的一行一行的找出来,再一行一行的计算,编程一点的说法叫“遍历”表。
如是,我们给出了第一个“当前筛选”的定义,即当前列表计算环境的定义:“一组筛选器应用到模型列表中,从而改变整个数据列表集的当前可见的行(列值)”。
即使这是一个正确的定义,但它仍然很幼稚。我相信很多希望学习DAX的人都不愿意停留在这里。可事实上,理解到这一步,已经能解决大多数的业务问题了。
为了理解到更高一个层次,需要记住前面的那句《DAX圣经》里的话:
我们应该抛弃表格的思考方式转而以列表的概念来理解DAX,因为,CALCULATE(DAX)的一切都是关于列表的。这是之前的一段理解(懒得打字,截图如下):

数据模型里的表的样子(常规表的样子):
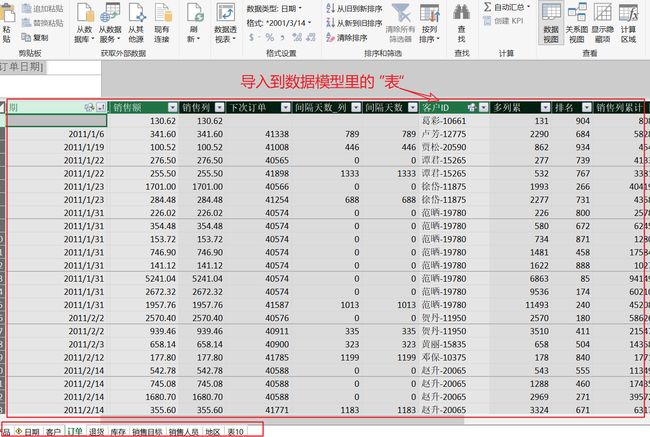
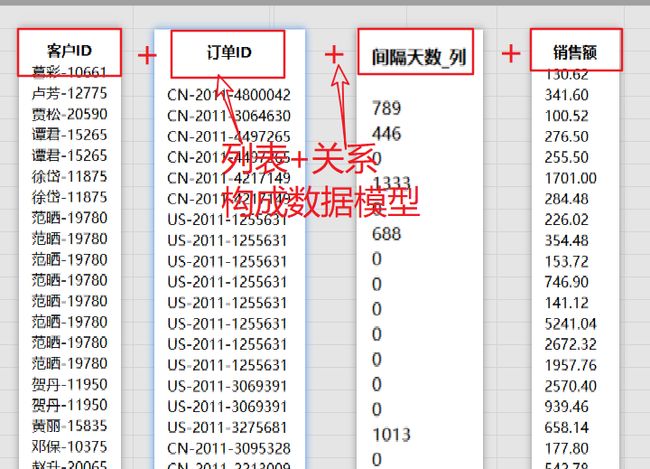
可是。我们更希望你将它想像成这个样子(实际上也应该是这个样子):
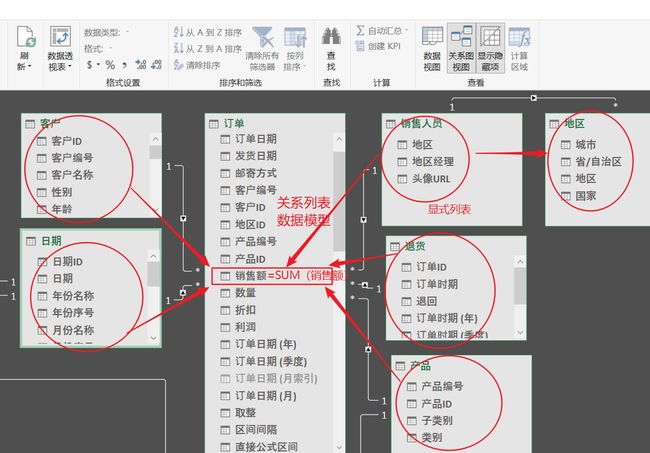
我们还可以到数据模型关系视图里体验一下:(为了节省截图时间,采用一个原来使用过的图示)。
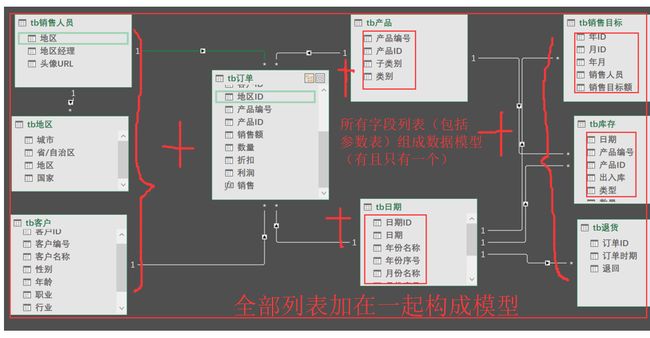
这是我们创建的一个关系型物理列表的数据模型(关键的构成要素是关系+列表),只要你不更新数据,它总是一个最大的数据模型(即工作表模型)。它当然包含所有计算需要的列表(更包括由它产生的列表—无论扩展表、新表、参数表等)。
上图的方式表明:表的正确表示将是一组列表(一个或多个单列表构成,并不考虑行-哪怕某个列只有一行,某个列有干万行)。
我们可能还记得:ExceI表格里没有值的单元格通常会以0或空值代替,在数据模型里,引擎将为只有一行的列表自动生成一个Null值来映射对应另一个千万行的列的干万行-1的所有行。很显然,对那个只有一行的列计数,结果可能是2而不是1(当然,你可定义非空值处理)。在透视结果里所有Null值将筛选对应的另一列的所有行计值,你知道这将是:空白值汇总。
如图所示:NULL映射的行值对比。
还有一个证明模型里单列表参与计算的位置。我们在DAX公式编辑栏里随便起个度量名,然后接一个英文的:= (计算列公式或PowerBl里只有 = ),这时候,你只要输入一个 '(单引号),表示你要引用某个列表计算,智能提示会显示出所有可能会用到的列表。这时候的列表,是你可以在数据摸型里引用的、真正的、全部显式列表集。
如果你想要引用的列表没有出现,那么,可能的原因:没有这个物理列表(需要虚拟构建),或者还没有建立关系(重建关系)。依此,你还可以检查某些公式定义的参数,是否可以引用该列表(比如该位置没有出现度量值列表,说明该位置不能放置、引用度量等)。
而且,对于你更好的理解显式的列表概念有帮助。在公式编辑栏里的智能提示中显示的列表,你可以通过双击(直接引用的方式)放置在公式的适当位置。如图所示:
这里值得提示一下:可引用的列表可能包括当前公式中以VAR定义的变量,你可以使用RETURN函数将其取出,并放置在公式合适的位置;之外,可能还包括已定义的度量值在内,这并不奇怪,度量是Calculate定义的结果,本身就是一个列表。
你应该还记得前面列举的那个要显式列表筛选才能正确计算的公式,我们使用度量名称来替代CalcuIate(Sum(Sales[SaIe]))的显式列表筛选,也是可以的。如果使用智能提示,你当然可以在该位置直接双击引用该度量即可。如图左边公式是错误的,而右边的两个(使用CALCULATE()显式列表及度量列表是正确的):

更清楚一点的图示:

提示:其实,你有没有注意到,我们每涉及到列表时,使用的都是“引用”一词,而其他情况(比如行筛选、值列表、变量)使用的都是“定义”一词,“引用”的一般都是显而易见的、物理的、已存在的(显式的),需要“定义”的(比如逻辑条件,那是隐式的、内部的、我们看不见的,对于DAX而言,是那些需要引擎完成的部分。这就是中国汉字的奥妙。你不必纠结,略过这部分即可。
本来还想着提示一下列表的物化、虚拟概念,算了,已经够乱了。还是好好的研究一下DAX的使用说明书吧。
有点啰嗦了,接着说列表。与普通Excel单元格区域表不同, DAX中的VertiPaq可理解为:是一个列式数据库。因此,所谓表的正确表示将是一个或多个(一组)列表(后面谈到列表关系时,将进一步表述为一组关系列表,见上面的图示)。
将数据模型理解成一个个单列表组合在一起的样子,这种可视化效果会更好些,而且对于后面理解另一个重要的单级关系连接的扩展表概念有帮助(请参阅扩展表系列),以及最后要说的引擎的单线程(大多数情况下)执行单个列表操作的特点(比如多个筛选不能同时作用于同一个列上)。
DAX列表也与Excel、ACCESS、SQL不同,在PowerPivot当中,仅有一个全局性的数据集,称为“数据模型”(PivotModel)。一个Excel工作簿,有且只有一个数据模型(甚至没有Powerpivot,它也能称为一个数据模型)。
但是,大多数情况,我们用于计算的列表往往是模型列表的一个子集,而且这个子集不一定来自同一个表(使用整个数据模型计算的情况很少,除非模型只有一个没有关系的表)、也不一定是一个列的整列。这是我们学习DAX必须要明白的一个概念。
因为,我们在写DAX时,可能是在某个表区域(该表所在计算区域里),于是觉得DAX公式所在的数据模型就是这个表,这是不对的。你必须有一个全局性的关系型数据模型概念(请参阅扩展表系列)。
比如,你可以在任意一个表里(反正都是一个整体)写公式,甚至可以将度量单独放置在某个表里,并归类管理。唯一需要注意的是,你需将公式里的列表显式限定为表名称+列表:表名称[列表名]。
在平时运用中,由于列表特性:你可以不用理会列表的位置(其实是不存在),由于没有行的概念,你将很难处理诸如“行”的计算,以及对某列进行真正意义上的内部排序行为(虽然可以使用“按列排序”--请参阅《按列排序的坑》一文),甚至在具有粒度级别上的计算也是它的短板(这些需要通过技术性手段来处理)。
我们暂时用:“事物总是有好有坏”的辩证法来总结它吧。
第8式:CALCULATE的筛选是一个或多个列表
我们终于可以更好的表述当前列表筛选的定义:
每个列表筛选是一组列表,其中包含每一个单列表,并定义出该列的所有列值。而且,在列表筛选中,引擎始终认为列表是可见的、存在的、显式的。所以,当所有这些筛选器放入一个逻辑条件里时,则形成当前列表筛选。
例如:在一个透视表的单个单元中,都有来自切片器以及行、列表筛选。每个筛选器都在列表、或定义的列表集合上操作。因此,在我们的实际DAX例子中,筛选都会包含一个或多个独立的列表筛选,进而筛选出计算列表(后面更进一层的解释是,每个单线程的单列表筛选汇总后再执行筛选计算)。
综上啰嗦,我们更好地理解了当前列表筛选的含义。唯一的问题是,还是没有对行的行为(行上下文)做出结论。有了前面的铺垫,应该是时候来讨论了。
很多时候,仅仅元度量还是无法满足业务建模需要的。元度量在粗犷的列表筛选中虽然也拥有列表组合筛选的变化,但如果想要更新列表筛选(比如更改元度量的筛选),让列表筛选在更细腻的某些逻辑条件下改变计算,则需要为模型中的某些或全部到表筛选提供一个新的值列表。DAX将用新的值列表替换该列上的列表筛选器,并以此方式生成一个新的列表筛选。
你可以简单地、暂时地将这理解为:列表的列值(范围)的变化。
这里第一次提到了"值列表"这个概念。它在DAX计算中也是一个绕不开的关键话题。
首先,DAX引擎只接受显式的列表。如是,你总是会在定义DAX公式时,绝对离不开思考如何用“列表筛选列表”(任何人都不例外,而且这种能力并不是IT高手或引擎的发明者就厉害一些,就像造飞机的并不一定是驾驶飞机的、母鸡下蛋并不需要知道蛋用来干什么去了,是一样的道理)。
无须质疑,这问题总会让人费解与纠结:
什么是列表筛选列表?这样能筛选吗?
这样筛选对吗?这样筛选的依据是什么?
这样筛选的结果是什么?为什么同样的列表筛选结果怎么不一样了?等等。
我们后面大部分的时间是用来研究这些问题的(当然,有时候这需要站在巨人的肩膀上)
我们前面已提示过,本系列知识可能比较跳跃。这里需要提前串烧一下DAX引擎的压缩特征,以帮助我们理解上述几个纠结不完的概念。内部引擎是DAX的根与魂(虽然不要求理解内部原理,但至少需要知道一点点大概的原理以及如何工作),即先简单知道VertiPa引擎的以下两点知识:
(1)VertiPa引擎有三大压缩算法:值、字典、行距压缩(它会依列表类型自动压缩处理);
(2)DAX内部三种引擎运行的过程:压缩引擎的VertiPaq压缩-->存储引擎的存储数据(内存里缓存)-->公式引擎的数据引用。其中公式引擎的典型运算符包括:
1)列表之间的联接(请参阅:联接表系列);
2)具有复杂条件的筛选、聚合和查询等。 这些运算符通常就是依据数据模型里的列表结构(列表、关系、列类型。再没有其他了)。
为了讲清列表的概念,我们几乎动用了所有能动用的资源(后面需要扩展它们),你不需要一下子理解,知道有这回事就行。
我们继续,先具体的谈几点能帮助我们理解的、涉及引擎的那些:
(1)决定列大小(存储与执行消耗)的主要因素不是数据类型,也不是列值多少,而是列的唯一值(基数)的数量。
因为,内部引擎会将重复的相同列值视为一个值处理,举个例说明:一个唯一值为3个值的50万行列值的列(引擎可能只需要处理3次),比一个唯一值为30个的只有500个行列值的列(引擎可能需要处理30次),在非常大的数据里将要快不只一个量级。你如果习惯于理解为遍历或迭代,那就是3次与30次的区别!
我们能想到的是,引擎肯定是以列表来处理的,上面这个无论是否合适的举例,也能确定引擎并不是一次性处理整列(1次,处理的不是一行!)。
假如说,引擎处理了3次。那么,这个列表至少被引擎"四分五裂“过3次!无论中间的过程多么弯转曲折(经历了多少个筛选、多少个逻辑条件限定,比如那些看起来高大威猛的长长的DAX公式),目标都是某个源数据模型里被定义用来计算的那个单列表(比如Calculate()的第一个参数,后面会详说)。
问题来了,我轻轻地、小心地问一下:
1)你知道这3次或30次,引擎先处理哪一次?
2)事实上不仅如此,那3万或30万个行,是从上而下,依次进行吗?
3)可能,运用已有的知识,你知道能处理或定义“当前行”的行,或“当前行”的前多少行或后多少行......。问题是这是你定义的(你可能需要额外引用一个序号或者编号列通过“&&”定义、或者使用变量、或者专门函数定义等),它并不是内部引擎的执行行为。
4)有太多的次数、太多的行时,每次对应处理的行数量相同吗?等等
换句话说,你无法控制引擎的所谓行的行为(你却总想去搞懂它),它始终是列表行为。你要它理解你,只有通过列表这个唯一的方式告诉它,而不能一厢情愿。否则,结论是,你的公式将会错误(因为你并没有了解它,如何让它正确地工作?)。
这里,我们至少已经知道了:引擎每一次处理的不一定是一行!不是一行,当然不能说"一行一行“地遍历。而且,引擎还是在以"列表的方式“执行它(只是我们习惯了认为它是行),从这点上说:行上下文="当前行“,这里的行可不一定是我们认为的一行,而可以是许多的行。
第9式:CALCULATE的值列表与列表
可以肯定的是,行上下文是一种以行的方式运行的行为。但显然称之为“行”或"当前行“己不合适(90%的情形如此,不恰当)。更恰当的应该叫"值列表"。
值列表并不仅仅指代数值型列表,而是由列基数(唯一值)所定义。比如,通常我们筛选中使用的:某列="张三",指代的是列基数为"张三“的所有行的值列表。
那么,通常所说的列表是包含了该列全部基数(唯一值)的整列,而只包括某些(部分)基数的列表我们称之为"值列表"。
你可能会想到,求列表里的行(列值)的基数与计数是稍微不同的: 只有求一列中唯一值的计算才是基数计算,此类函数有DISTINCTCOUNT(非重复计数)、VALUES、 DISTINCT、COUNTROWS(FILTERS())等。它们之间在用法上有细微的差异。略。
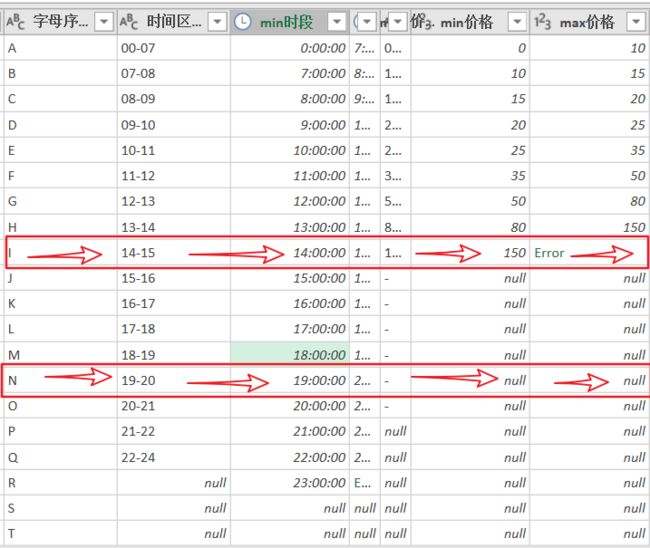
不管你是针对表或表里的某个列计数,你可以发现,基数值结果只与该列拥有的唯一值的数量有关。如图,在透视表里(以及数据模型里)显示出针对同一个表的整表或不同列表计算。你可以理解为:你筛选某列,其实筛选的是基数,你习惯了迭代的说法,那就先理解为,迭代了多少个基数,就执行了多少次。
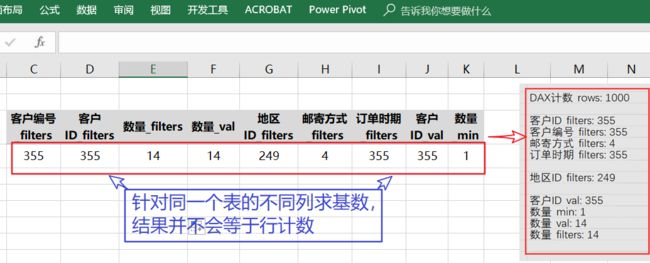
也就是说,列表始终是列表,不过为了方便,将它以两种方式存在而矣(就像水的三种状态不同,都由H2O构成)。
你应该能发现并明白,由于列表的基数不同,作为筛选时的筛选范围也会不同。通常,拥有最大基数的那个列表,依需要,是可以作为关系外键与其他表建立关系(因为该列表拥有的基数与整个模型表的基数相同)。
(2)我们还可以使用SSAS的线程段的执行来理解数据内部的运行。SSAS总是使用某个线程段来扫描包含800万行或更少行的计算表,在PowerPivot中也有100万行!对,你没有看错,一次性运行100万,100万会是一行一行吗?当然这其中可以说,它包含了多少次扫描运行。
结果可能只有一行(一行的列表)或多行。
这样想想,有时候你不能把处理几十万数据就卡顿的责任全扔给DAX引擎;
再如:2350000与2350001这两个看起来很大的数放在数据模型列表里,其实跟0与1没什么区别,因为VertiPaq内部可能会很聪明的使用值压缩算法将这两个数处理为:2350000-2350000=0、2350001-2350000=1的整数值0、1来代替(引擎找到该列中的最小值,然后其他列值跟它求差值比较),这是简单的理解,别纠结对错,总之有这种情况。
再比如,你的数据在某个千百万计的行之后,突然出现了一个离群点:一个超级大的数据、或超级小的数据、或某些异常数据(一个逗号?),引擎就会回过头去重新编码该列,虽然能计算出结果,也可能造成需要很长时间来运行!
所以,引擎处理的最大消耗往往来自人为的错误(比如改变整列构造的行为,或者定义了DAX无法理解的非列表行为)。
引用该定义,我们也可以说:学习DAX的最大障碍,可能会来自你对于列表行为的理解(比如总习惯于数据库、编程语言来与之沟通)。这也是我们说干了口水也要死磕它的原因。
(3)我们将数据模型的不存在的东西罗列一下:VertiPaq中没有多维数据集、也没有度量组、更没有行或维度的概念。它总以压缩数据来有利于快速分析计算为目的!(这也是今后优化数据或公式的依据)。
方法总是会有的,为了能使用列表的语言形式与VertiPaq沟通,或者有一种让它能听懂、能理解的方式,这就是前面我们前面提到的“值列表”。
它形式上是列表(能被引擎识别并理解),同时它也是某个列里的一个或多个列值的组合(具有列值的属性:例如可以使用加减运算符计算、布尔值条件、以及作为逻辑条件构建的参数等)。
通过前面的超级啰嗦,再说两个由此产生的实用而重要的方面:
1)筛选器:它是某个列上的一组活动列值(整个列值的列表或部分列值的值列表),并只适用于单个列。请记住,这并不是列表筛选的正确定义。不过,在学习完许多其他方面的DAX知识前。这个定义对于开始使用列表筛选已经非常有用了。
注意:完成了这个话题之后,接下来的部分,还将就如何更好地理解列表筛选是什么,并可以继续更好的运用它进行计算进行讨论。这里先略过。
我觉得我们已经在死磕“列表”了(当然,这会很值得)。最后,我们将前面的讨论归结成一个通用的结论,以方便今后在DAX的使用中运用它解决实际问题。这才是我们的目的。
因为,对于整个DAX的了解有两个重要的关于列表的概念:筛选与计算。根据DAX语录:所有DAX都是关于列表的。自然,我们分别在筛选与计算前加上列表的两个形态:值列表或列表作为限定,那就是说DAX包括两大部分:
(1)值列表或列表的筛选;// 对数据列表的筛选,即行筛选与列表筛选。
(2)值列表或列表的计算。// CALCULATE( )
所有DAX公式,都是基于列表的两种形态:列表类型(针对列表)或列值格式(针对列值、值列表)。你可以对某一个列表,分别设置列表的数据类型以及列值格式(你应该明白了,值列表是物理列表(元列表)的衍生或派生的列表。它的基数总是要比元列表少(这在实际的DAX运用中要注意,否则筛选将不起作用)。
其实,DAX对列类型并不敏感、也能良好处理列表类型,当你需要处理诸如在公式里使用某个特别的符号、时期转数值等,只要列表类型设置并确认一次就行。而且必须事先这样做,否则即便引擎能处理出结果,也会消耗内存、减低性能!
最后,如果你对于DAX列表已有一定的了解。那么,接下来还会就这个话题展开,希望它变得更易于理解和尽快投于运用。
未完待续