2019暑期Stata现场班,7.17-26日,北京,连玉君+刘瑞明 主讲
作者:游万海 (福州大学)
Stata 连享会: 知乎 | | 码云
Stata连享会 精品专题 || 精彩推文
连享会 Stata 爬虫和文本分析系列推文:
- Stata: 正则表达式和文本分析
背景
爬虫之工具:R,Stata 和 Python
统计计量软件众多,例如 R,Stata 和 python 等,每个软件都有自己的优点和缺点。
就爬虫而言,python 和 R 软件的功能已较为成熟,拥有一系列实现各类功能的包 (package)。比如 R 中的 rvest 包在爬取静态网站数据方面功能很强大,此外,还有 RCurl 和 XML 包等。
相比而言,Stata 虽然在格式化数据处理和计量分析方面非常高效,但在爬虫方面可能还处于 爬行 阶段。曾经有人调侃道:利用 Stata 软件来爬虫的都是比较文艺的 ^-^。
事实并非如此。自 Stata 发布 14.0 版本以来,其字符处理功能已大幅改善,再配合 copy 和 curl 等命令,Stata 的爬虫能力日渐强大。curl (https://curl.haxx.se/) 是一个在命令行下工作的文件传输工具,支持文件的上传和下载,可发送各种 http 请求 给网站,进而抓取网站内容保存到本地。
本文要干的事儿
本文将利用实例来对比 R,Stata 和 python 在爬虫方面的功能。「 100 行代码爬取全国所有必胜客餐厅信息」 一文中,作者利用 python 爬取了全国所有 必胜客餐厅信息 ,包括:餐厅名,地址和电话号码。借鉴该文的分析思路,本文利用 Stata 和 R 软件对其结果进行重现,爬取全国必胜客餐厅相关信息,以此说明使用 Stata 和 R 爬取数据的步骤和流程。
爬虫的第一步是分析网址,找出其中的规律,以便写循环实现自动爬取;接下来就是把网页信息复制 ( copy ) 下来,保存为 .txt 或其他便于读入统计或计量分析软件的数据文件。
copy 命令是 Stata 中常用的一个爬虫命令,但是在本例中却无法使用。分析必胜客官网网址可以发现,当切换城市时,网址不会随之改变,这时就不能构造有效的地址对其进行循环爬取。为此,我们使用外部命令 curl 命令来实现。
数据的爬取主要包括两部分:第一,从网站上将包含数据信息的源代码下载到本地。这里就涉及到需要对爬取的网站进行详细分析,对于这个网站更加详细的分析,大家可以看之前作者写的推文;第二,利用字符函数或正则表达式对下载的文本文件进行处理,这部分可以详细看之前的一个推文(https://blog.csdn.net/arlionn/article/details/85156842)。
本文分如下部分进行说明:第一,对网页结构进行分析;第二,讲解正则表达式中的零宽断言;第三,对必胜客餐厅分布信息进行抓取;第四,对文章内容进行总结;第五,参考资料说明。
一. 网页结构图解分析
1. 分析网页结构
打开(http://www.pizzahut.com.cn/StoreList) 可以发现下图,当我们切换城市时,相应城市网址不会改变。此时利用 copy 命令,那只能下载其中某个城市一页的数据。

为了进一步了解网站信息,可以利用 google 浏览器,按 F12 会跳出一个页面,再按 F5 刷新 (注意:如果是 win 10 系统,要按 ctrl + R),可以看到如下页面:
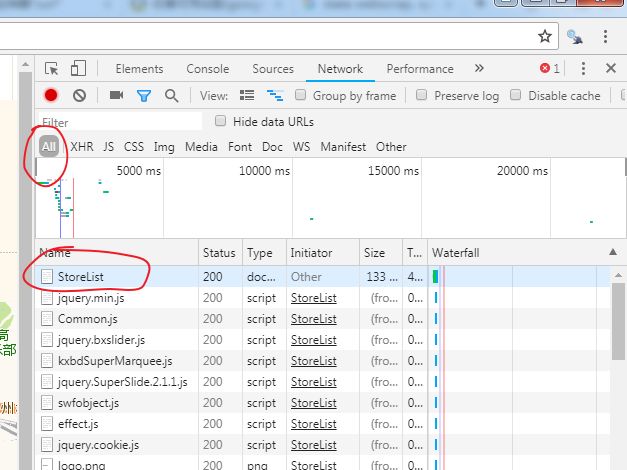
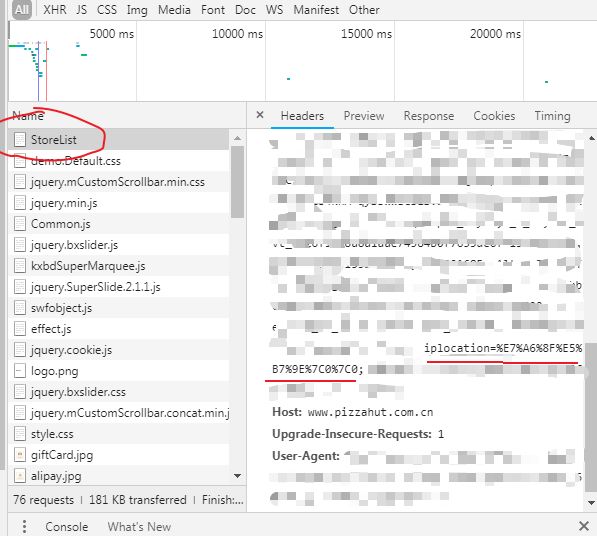
我们点击 StoreList,然后出现页面如下,我们可以看到网页的一些 cookie 信息,其中 iplocation 其实就是城市的转码,也就是说,变换这个字段,其实就是切换城市。
2. 编码转换
为了进一步验证,我们利用 R 中 curl 包的 curl_escape 函数将字符进行URL转码。例如
library(curl)
x = "福州"
curl_escape(x) ## 输出 %E7%A6%8F%E5%B7%9E
对比上述输出结果与 iplocation 的并不相同,根据开始介绍那篇推文作者,我们可知其实是 福州|0|0 的转码,
x="福州|0|0"
curl_escape(x) ## 输出 %E7%A6%8F%E5%B7%9E%7C0%7C0
当然,这里主题是讲 Stata 软件,我们若想所有程序都在 Stata 环境中运行,那么可以通过 rcall 命令在 Stata 中调用 R 程序。详细的用法可以查看 (https://github.com/haghish/rcall), 这个命令已经在 Stata Journal 2019年第1期正式刊登出来。
github install haghish/rcall /**利用github安装rcall**/
rcall:print("Hello world")
rcall:library(curl)
rcall:x="北京市|0|0"
rcall:print(curl_escape(x))
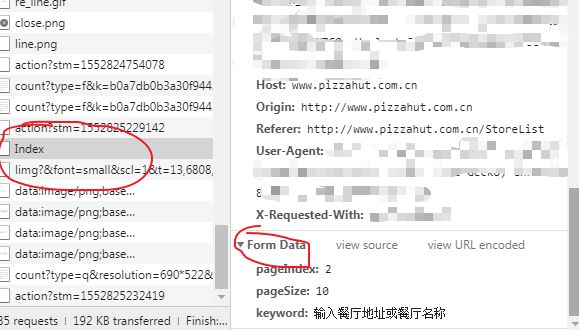
大家可以发现,这正是 城市|0|0 的 URL 转码恰好是 iplocation 所表示的,通过改变这个字段就可以实现城市的切换。但是,对于同一城市不同页码切换,还需要进一步发现。当我们点击左边的下一页时,可以发现在列表会多一个 Index 选项,点进去发现 From Data 下面有 pageIndex和 pageSize 两个字段,至此我们知道了如何定义页码,以便进行循环。
二. 正则表达式--零宽断言
1. 基本函数
Stata 14 版本主要的正则表达式函数有:ustrregexm,ustrregexrf,ustrregexra 和 ustrregexs,ustr 代表 unicode string 。
ustrregexm : 匹配
ustrregexrf : f 代表 first ,表示只替代第一次出现的匹配字符。
ustrregexra : a 代表 all ,表示替代全部匹配到的字符。
ustrregexs : 截取
2. 零宽断言
正则表达式中有许多的匹配规则,这里不在一一说明,请大家花几分钟看 (https://blog.csdn.net/arlionn/article/details/85156842), 这里再给大家介绍一种用法,即 零宽断言,主要有如下四种类型:
(?=exp): 零宽度正预测先行断言,它断言自身出现位置的后面能匹配表达式 exp
(?<=exp): 零宽度正回顾后发断言,它断言自身出现位置的前面能匹配表达式 exp
(?!exp): 零宽度负预测先行断言,断言此位置的后面不能匹配表达式 exp
(?: 零宽度负回顾后发断言来断言此位置的前面不能匹配表达式 exp
3. 应用实例
例如,如下数据为 6 位同学的各科成绩,我们想计算每位同学的总成绩,那么需要把数字部分提取出来
clear
input str64 x
"math:96 chinese:85 english:92 physical:90"
"math:91 chinese:82 english:88 physical:98"
"math:86 chinese:85 english:81 physical:90"
"math:93 chinese:85 english:88 physical:90"
"math:70 chinese:85 english:83 physical:91"
"math:80 chinese:85 english:81 physical:92"
end
方法一 :可以利用 moss (Find multiple occurrences of substrings) 命令,代码如下:
moss x, match("([0-9]+|[a-z]+)") regex
list _match*
方法二:利用零宽断言方法进行提取,我们观察到这些数字都是位于 : 符号之后,那么我们想是否可以通过如下提取:
local regex "(?<=\:)([0-9]{2})"
gen grade1 = ustrregexs(1) if ustrregexm(x, "`regex'")
list, clean noobs
可以发现结果并不完整,只取了第一部分的数字。这里需要注意,因为我们只匹配一次(说明:每个软件的规则有点不一样,R 中这样写就可以),下面我们把代码进行稍微修改:
local regex = "(?<=\:)([0-9]{2}).*" * 4
gen grade1 = ustrregexs(1) if ustrregexm(x, "`regex'")
gen grade2 = ustrregexs(2) if ustrregexm(x, "`regex'")
gen grade3 = ustrregexs(3) if ustrregexm(x, "`regex'")
gen grade4 = ustrregexs(4) if ustrregexm(x, "`regex'")
list, clean noobs
匹配结果如下,发现已匹配成功。
list, clean noobs
x grade1 grade2 grade3 grade4
math:96 chinese:85 english:92 physical:90 96 85 92 90
math:91 chinese:82 english:88 physical:98 91 82 88 98
math:86 chinese:85 english:81 physical:90 86 85 81 90
math:93 chinese:85 english:88 physical:90 93 85 88 90
math:70 chinese:85 english:83 physical:91 70 85 83 91
math:80 chinese:85 english:81 physical:92 80 85 81 92
上述代码中 (?<=\:) 表示我们想取出的字符前面需为 : 号,我们再来看下面例子:
clear
input str12 x
"ABAC"
"AAC"
"123AC"
"ABAC"
"1ABAC"
end
gen code=ustrregexs(1) if ustrregexm(x, "(?<=AB)(AC)")
list
上面的例子中,我们想取出 AC,一个条件是该字符前面应该为 AB 。匹配结果为:
list
+--------------+
| x code |
|--------------|
1. | ABAC AC |
2. | AAC |
3. | 123AC |
4. | ABAC AC |
5. | 1ABAC AC |
+--------------+
三.必胜客餐厅分布信息爬取
1. 下载 curl
curl 是一个在命令行下工作的文件传输工具,不是 Stata 中的命令,所以不能通过 ssc install 或者 **findit ** 进行安装。利用 curl 之前需要到其官网下载(https://curl.haxx.se/download.html) ,大家根据自己电脑系统去下载对应的版本,比如我这里下载的是64位的

然后,解压后将 exe 文件放到 C:\Windows\System32,或者放在其他目录,设置好环境变量,就可以接着运行下一步。
2. 数据爬取
(1). 利用 Stata 爬取数据
通过对必胜客网站的结构分析,下面就看如何具体的实现,这里主要有两点:第一,要对所有城市进行循环,即利用 curl_escape 所得到的 URL 码,通过对 iplocation 进行循环;第二,对每个城市的不同页码进行循环,这里利用 pageSize 和 pageIndex 进行循环。
clear
import delimited using "D:\我的文档\citylist.csv",clear encoding("GBK") /*第一列为城市名称,第二列为URL码*/
drop in 1
keep in 1/10 /*定义需要爬取的城市*/
rename v1 cityname
rename v2 citycode
levelsof citycode, local(citylevs) /*对城市进行循环*/
di `citylevs'
local nfile 0
foreach f of local citylevs {
local nfile = `nfile' + 1
!curl -H "Cookie: **iplocation** =`f'" ///
--data "pageIndex= 1 &pageSize= 10 " -o "D:/stata15/ado/personal/data/`nfile'.txt" http://www.pizzahut.com.cn/StoreList
*shell `nfile'.txt
}
上述程序爬取了前 10 个城市某一页的数据,利用 levelsof 命令将观察值转换为 local macro,并对 macro 进行循环。这里只爬取了某一页的数据,未对 pageIndex 进行循环。运行上述程序后,可以在 "D:/stata15/ado/personal/data 目录下生成包含数据信息的临时问题,以便后面进行合并。
*对保存的网页数据txt文档进行合并
local files: dir "D:/stata15/ado/personal/data" files "*.txt"
di `"`files'"'
tempfile appendfiles
foreach f of local files {
qui import delimited using "`f'", clear encoding("UTF-8")
qui capture append using `appendfiles'
qui save `appendfiles', replace
}
tempfile temp1 temp2 temp3
use `appendfiles',clear
keep v1
**爬取餐厅名字
gen index1 = ustrregexm(v1,"(re_NameNew)")
gen bsk_name = ustrregexs(1) if ustrregexm(v1,"(?<=>)(.+)(?=<)") & index1==1 /*OK*/
preserve
keep if bsk_name!=""
save `temp1',replace
restore
**爬取餐厅地址和电话号码-第一行地址,第二行电话,递推
gen index2 = ustrregexm(v1,"re_addr")
gen bsk_phone_name= ustrregexs(1) if ustrregexm(v1,"(?<=>)(.+)(?=<)") /*OK*/
keep if index2==1
**电话号码
preserve
keep if mod(_n,2)==0
rename bsk_phone_name bsk_phone
keep bsk_phone
save `temp2',replace
restore
**餐厅地址
preserve
keep if mod(_n,2)==1
rename bsk_phone_name bsk_address
keep bsk_address
save `temp3',replace
restore
**将餐厅名字,电话号码和餐厅地址合并在一个数据集中
use `temp1',clear
drop index1
forv i = 2/3{
qui merge 1:1 _n using `temp`i''
qui keep if _merge==3
drop _merge
}
drop v1
list in 1/10
结果如下:
list in 1/10
+------------------------------------------------------------------------------------------------+
| bsk_name bsk_phone bsk_address |
|------------------------------------------------------------------------------------------------|
1. | 元洪餐厅 0591-83277835 元洪城商场一层 |
2. | 台江万达餐厅 0591-87899675 鳌江路8号福州金融街万达广场二层01商铺 |
3. | 省府餐厅 0591-87571033 八一七北路68号供销大厦二层 |
4. | 浦上万达餐厅 0591-87933619 金山街道浦上大道272号仓山万达广场A5号一层 |
5. | 永嘉餐厅 0591-23507836 上街镇永嘉城市广场16号楼永嘉天地2号门一层 |
|------------------------------------------------------------------------------------------------|
6. | 远洋餐厅 0591-7389205 远洋路423号 |
7. | 十洋餐厅 0591-28783099 吴航街道郑和中路十洋商务广场(第一期)1-1号铺 |
8. | 五四HS餐厅 0591-87713937 鼓东街道五四路162号新华福1#、2#连体楼1层08商场和2层02商场 |
9. | 东二环泰禾餐厅 0591-88510675 岳峰镇竹屿路6号东二环泰禾城市广场三期地下室1层01商业铺位号B13 |
10. | 杉杉奥莱餐厅 0371-55387121 郑开大道与雁鸣大道交叉口杉杉奥特莱斯购物广场一层A12600 |
+------------------------------------------------------------------------------------------------+
(2). 利用 R 爬取数据
说好的对比呢,说好的 R 程序呢,现在我们来看如何在 R 中实现相同的功能,对比下在爬虫方面的功能:
rm(list=ls())
web="http://www.pizzahut.com.cn/StoreList"
result = readLines(web,encoding="UTF-8")
cities_list = grep('% html_nodes('.re_RNew')
postdata <- xml %>% html_text()
pdata <- gsub('\r\n'," ",postdata)
pdata=str_trim(pdata)
fdata = strsplit(pdata,split=" ")
bsk_name <- unlist(lapply(fdata,function(x) x[1]))
bsk_address <- unlist(lapply(fdata,function(x) x[2]))
bsk_telephone <- unlist(lapply(fdata,function(x) x[3]))
bsk_region <- rep(regex_cities[i],times=length(bsk_name))
namelist[[k]] = cbind(bsk_region,bsk_name,bsk_address,bsk_telephone)
k = k + 1
}
}
result_data = noquote(do.call(rbind,namelist))
result_data = data.frame(餐厅名字=result_data[,2],地址=result_data[,3],电话号码=result_data[,4])
head(result_data,10)
tail(result_data,10)
部分结果如下
> head(result_data,10)
餐厅名字 地址
1 天北路餐厅 天竺镇天北路水木兰亭1号楼底商
2 甜水园餐厅 万科公园5号楼7号101
3 慈云寺餐厅 八里庄苏宁广场一层
4 红桥餐厅 天坛东路46号红桥市场
5 亦庄力宝餐厅 亦庄荣华中路8号院1号楼一层F1-36及二层F2-26铺位
6 王府井淘汇餐厅 王府井大街219号-4至9层101的二层2008号商铺
7 西红门餐厅 欣宁街15号
8 东坝餐厅 东坝中路金隅嘉品mall二层
9 宋家庄餐厅 宋家庄路26号院11号楼1层114/115-2
10 理想城餐厅 西红门镇宏福路洪坤广场1层
电话号码
1 010-50933941
2 010-5535431
3 010-85725206
4 010-67111853
5 010-52594995
6 010-65228561
7 010-60221990
8 010-85095069
9 010-67904805
10 010-51077619
> tail(result_data,10)
餐厅名字 地址 电话号码
91 福泉路HS餐厅 福泉北路511-18A号一层 021-52650093
92 海悦餐厅 曲阜西路398号 021-61235119
93 星游城新HS餐厅 天钥桥路580号 021-61619851
94 凯旋南路HS餐厅 龙吴路51弄1号楼一层101室 021-54610675
95 黄兴宅急送餐厅 国科路80号一层80-1、80-2单元 021-31194881
96 海上海宅急送餐厅 飞虹路568弄46号一、二层 021-35305602
97 威宁路餐厅 威宁路55号 021-52395265
98 团结餐厅 团结路6号居民生活中心二楼 021-56041252
99 龙胜路餐厅 龙胜路404部分及406号一层 021-57870156
100 博兴餐厅 凌河路757-759号一层 021-50264386
四.总结
本文主要阐述如何利用 Stata 爬取网页数据,curl 作为 copy 命令的一个补充,使 Stata 在数据爬取方面进一步完善,特别是Stata 14 以后,字符函数有了很大的改进。通过阅读本文,可以掌握如下信息:
1. 了解 Stata 爬取数据的一般流程和套路,掌握 curl 的用法。
2. 了解正则表达式中零宽断言的用法。
3. 掌握 Stata 中调用R的方法,利用 rcall 函数可以实现交互模式。
五.参考资料
1. 正则表达式在线测试网站(https://regex101.com).
2. curl 网站(https://curl.haxx.se/)
3. 极客猴:100 行代码爬取全国所有必胜客餐厅信息(https://blog.csdn.net/zhusongziye/article/details/84310490).
4. RStata (https://fsolt.org/blog/2018/08/15/switch-to-r.html)
关于我们
- 【Stata 连享会(公众号:StataChina)】由中山大学连玉君老师团队创办,旨在定期与大家分享 Stata 应用的各种经验和技巧。
- 公众号推文同步发布于 CSDN-Stata连享会 、-Stata连享会 和 知乎-连玉君Stata专栏。可以在上述网站中搜索关键词
Stata或Stata连享会后关注我们。 - 点击推文底部【阅读原文】可以查看推文中的链接并下载相关资料。
- Stata连享会 精彩推文1 || 精彩推文2
联系我们
- 欢迎赐稿: 欢迎将您的文章或笔记投稿至
Stata连享会(公众号: StataChina),我们会保留您的署名;录用稿件达五篇以上,即可免费获得 Stata 现场培训 (初级或高级选其一) 资格。 - 意见和资料: 欢迎您的宝贵意见,您也可以来信索取推文中提及的程序和数据。
- 招募英才: 欢迎加入我们的团队,一起学习 Stata。合作编辑或撰写稿件五篇以上,即可免费获得 Stata 现场培训 (初级或高级选其一) 资格。
- 联系邮件: [email protected]
往期精彩推文
- Stata连享会推文列表
- Stata连享会 精品课程 || 精彩推文


