介绍
Depthwise Convolution应该首创于Google的MobileNet网络。自此后渐渐它已经被用于了越来越多的移动端CNN网络当中。MobileNet v2相对于MobileNet v1而言没有新的计算单元的改变,有的只是结构的微调。它将Depthwise Convolution用于Residual module当中,并试着用理论与试验证明了直接在thinner的bottleneck层上进行skip learning连接以及对bottleneck layer不进行ReLu非线性处理可取得共好的结果。这么说来相对于之前的MobileNet v1而言还是有进步的。
当然它还对标了下Face++的ShuffleNet v1,在内存/计算效率上都实现了对此一对手的反超。
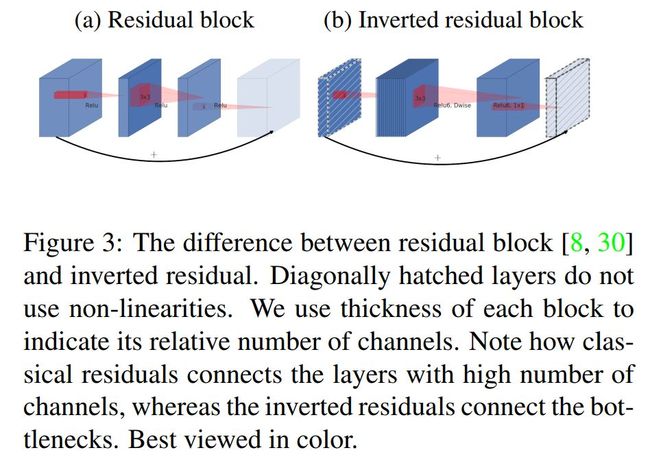
MobileNet v2的基础元素
Depthwise Convolution
构成MobileNet v2的主要module是基于一个带bottleneck的residual module而设计的。其上最大的一个变化(此变化亦可从MobileNet v1中follow而来)即是其上的3x3 conv使用了效率更高的Depthwise Conv(当然是由Depthiwise conv + pointwise conv组成)。它可有效地节省所需的真正计算。
线性的bottlenecks使用
通常我们使用1x1 conv的bottleneck在residual module当中(或其它像Inception module等)都是借鉴了之前在Network in Network中的想法即通过它来降低feature maps的channel数目以使得真正计算密集的3x3 conv计算量不那么大。
本篇paper中,作者们从理论上表明本质上ReLu对于feature maps之上的那些非零正数并不构成影响,而只是对它们进行线性变换。它们提出了如下两条ReLu使用的指导法则。
- 如果一个tensor(一般为feature map)在经ReLu非线性变换处理后如果非零的量并没有变化,那么它本质上相当于是经过了一个线性变换;
- 只有当输入的feature maps恰能被表示于输入整体空间的一个底维度组合当中时,使用ReLu在其后才能完整保留所有的信息量(坦白说,理解的亦很模糊,不多说了)。
相反的residual连接
与通用的residual module在bottleneck之前的较宽层上进行skip learning连接不同,mobilenet v2中的module直接在bottleneck layer上进行skip learning连接。理论上bottleneck layer作为module中串行管道的一个环节,它已经容纳了所有通过的信息,所以直接对其进行连接还可节省所需的internal tensor数量,从而减少内存需求。

可以看出residual module内部上来先是一个bottleneck layer,它不像之前意义上的bottleneck那样寻求减少输入channels数目(因为它输入feature maps的channel数目已经很少了,算是较thinner的tensor),而是对feature maps进行channels扩展,这里扩展系数为t,最后3x3 conv(Depthwise conv)再对它进行表达式的转换等操作,然后再以一个1x1 conv的缩减输出。整体而言它的输入channels数目为k,输出则为k'。
MobileNet v2结构
下表中可见MobileNet v2的整体网络结构。

它同我们之前见识过的许多CNN网络有许多一脉相承的地方,比如上来先使用普通的conv进行基础特征提取,然后再使用新颖的residual module一级级处理,feature map size越来越小,但其channels数目则不断增加。另外每个residual module内部使用的扩展因子都为6(作者在5-10范围上作了实验,最终选用6)。
此外,我们亦可像MobileNet v1中做的那样,使用width multiplier通过对输入图片大小进行调整以控制整体需要的计算与模型大小。
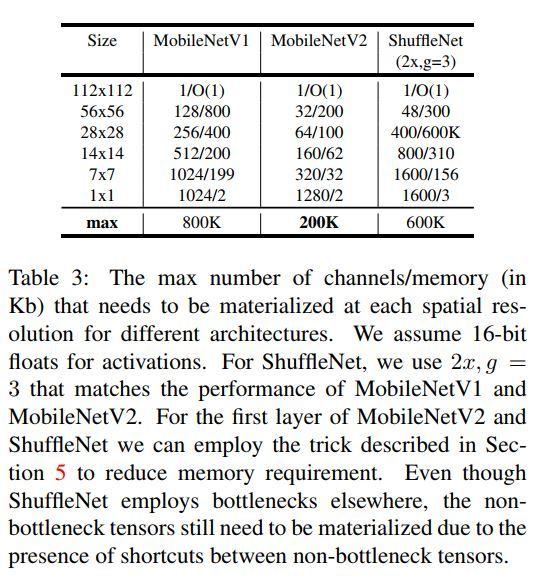
下表为MobileNet v2与MobileNet v1及ShuffleNet在模型体积大小上的比较。
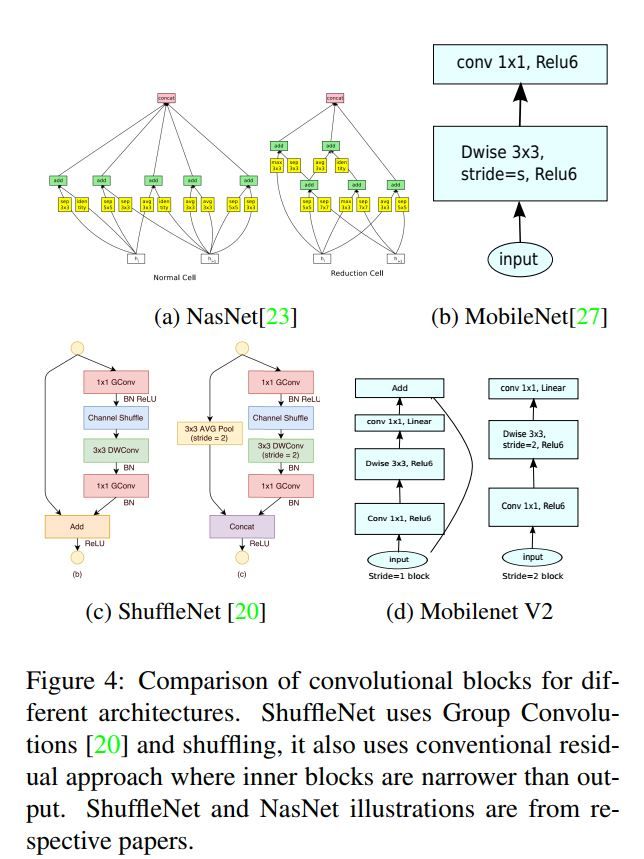
下图为MobileNet v2与其它较新的移动端CNN网络结构比较。NasNet显得够复杂的。
实验结果
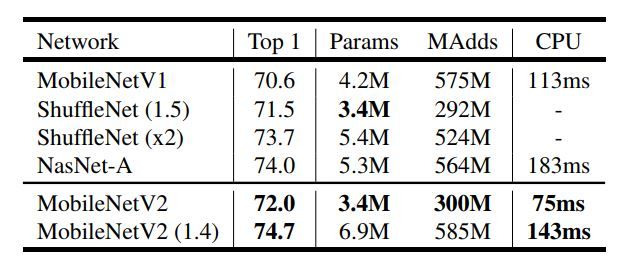
下表为MobileNet v2与其它移动端CNN网络在ImageNet上的精度及模型大小、计算量等比较。再次发现人家Google这次又是使用16个GPUs以async的方式来训练的,真是技艺高超啊。
代码分析
下面为具体的实现的网络结构的层次描述。相对于Pytorch, Tensorflow不大好的一个地方是有太多的参数与APIs了。或者它用起来很强大,但学习成本却太高。。对于Data scientist而言,pytorch的code写起来可真是容易太多。
V2_DEF = dict(
defaults={
# Note: these parameters of batch norm affect the architecture
# that's why they are here and not in training_scope.
(slim.batch_norm,): {'center': True, 'scale': True},
(slim.conv2d, slim.fully_connected, slim.separable_conv2d): {
'normalizer_fn': slim.batch_norm, 'activation_fn': tf.nn.relu6
},
(ops.expanded_conv,): {
'expansion_size': expand_input(6),
'split_expansion': 1,
'normalizer_fn': slim.batch_norm,
'residual': True
},
(slim.conv2d, slim.separable_conv2d): {'padding': 'SAME'}
},
spec=[
op(slim.conv2d, stride=2, num_outputs=32, kernel_size=[3, 3]),
op(ops.expanded_conv,
expansion_size=expand_input(1, divisible_by=1),
num_outputs=16),
op(ops.expanded_conv, stride=2, num_outputs=24),
op(ops.expanded_conv, stride=1, num_outputs=24),
op(ops.expanded_conv, stride=2, num_outputs=32),
op(ops.expanded_conv, stride=1, num_outputs=32),
op(ops.expanded_conv, stride=1, num_outputs=32),
op(ops.expanded_conv, stride=2, num_outputs=64),
op(ops.expanded_conv, stride=1, num_outputs=64),
op(ops.expanded_conv, stride=1, num_outputs=64),
op(ops.expanded_conv, stride=1, num_outputs=64),
op(ops.expanded_conv, stride=1, num_outputs=96),
op(ops.expanded_conv, stride=1, num_outputs=96),
op(ops.expanded_conv, stride=1, num_outputs=96),
op(ops.expanded_conv, stride=2, num_outputs=160),
op(ops.expanded_conv, stride=1, num_outputs=160),
op(ops.expanded_conv, stride=1, num_outputs=160),
op(ops.expanded_conv, stride=1, num_outputs=320),
op(slim.conv2d, stride=1, kernel_size=[1, 1], num_outputs=1280)
],
)
下面为slim库中生成mobilenet model的函数。它的骨干又要调用另外一个mobilenetbase函数来完成,见后面。
@slim.add_arg_scope
def mobilenet(inputs,
num_classes=1001,
prediction_fn=slim.softmax,
reuse=None,
scope='Mobilenet',
base_only=False,
**mobilenet_args):
"""Mobilenet model for classification, supports both V1 and V2.
Note: default mode is inference, use mobilenet.training_scope to create
training network.
Args:
inputs: a tensor of shape [batch_size, height, width, channels].
num_classes: number of predicted classes. If 0 or None, the logits layer
is omitted and the input features to the logits layer (before dropout)
are returned instead.
prediction_fn: a function to get predictions out of logits
(default softmax).
reuse: whether or not the network and its variables should be reused. To be
able to reuse 'scope' must be given.
scope: Optional variable_scope.
base_only: if True will only create the base of the network (no pooling
and no logits).
**mobilenet_args: passed to mobilenet_base verbatim.
- conv_defs: list of conv defs
- multiplier: Float multiplier for the depth (number of channels)
for all convolution ops. The value must be greater than zero. Typical
usage will be to set this value in (0, 1) to reduce the number of
parameters or computation cost of the model.
- output_stride: will ensure that the last layer has at most total stride.
If the architecture calls for more stride than that provided
(e.g. output_stride=16, but the architecture has 5 stride=2 operators),
it will replace output_stride with fractional convolutions using Atrous
Convolutions.
Returns:
logits: the pre-softmax activations, a tensor of size
[batch_size, num_classes]
end_points: a dictionary from components of the network to the corresponding
activation tensor.
Raises:
ValueError: Input rank is invalid.
"""
is_training = mobilenet_args.get('is_training', False)
input_shape = inputs.get_shape().as_list()
if len(input_shape) != 4:
raise ValueError('Expected rank 4 input, was: %d' % len(input_shape))
with tf.variable_scope(scope, 'Mobilenet', reuse=reuse) as scope:
inputs = tf.identity(inputs, 'input')
net, end_points = mobilenet_base(inputs, scope=scope, **mobilenet_args)
if base_only:
return net, end_points
net = tf.identity(net, name='embedding')
with tf.variable_scope('Logits'):
net = global_pool(net)
end_points['global_pool'] = net
if not num_classes:
return net, end_points
net = slim.dropout(net, scope='Dropout', is_training=is_training)
# 1 x 1 x num_classes
# Note: legacy scope name.
logits = slim.conv2d(
net,
num_classes, [1, 1],
activation_fn=None,
normalizer_fn=None,
biases_initializer=tf.zeros_initializer(),
scope='Conv2d_1c_1x1')
logits = tf.squeeze(logits, [1, 2])
logits = tf.identity(logits, name='output')
end_points['Logits'] = logits
if prediction_fn:
end_points['Predictions'] = prediction_fn(logits, 'Predictions')
return logits, end_points
下面是择要的mobilenetbase函数的主干。。已经无力吐槽。。怀疑这么一个CNN就写成这样多层次,有必要吗?很是好奇是否真的有人会像笔者一样有耐心将它看完。绝不会再看第二遍了。。
if multiplier <= 0:
raise ValueError('multiplier is not greater than zero.')
# Set conv defs defaults and overrides.
conv_defs_defaults = conv_defs.get('defaults', {})
conv_defs_overrides = conv_defs.get('overrides', {})
if use_explicit_padding:
conv_defs_overrides = copy.deepcopy(conv_defs_overrides)
conv_defs_overrides[
(slim.conv2d, slim.separable_conv2d)] = {'padding': 'VALID'}
if output_stride is not None:
if output_stride == 0 or (output_stride > 1 and output_stride % 2):
raise ValueError('Output stride must be None, 1 or a multiple of 2.')
# a) Set the tensorflow scope
# b) set padding to default: note we might consider removing this
# since it is also set by mobilenet_scope
# c) set all defaults
# d) set all extra overrides.
with _scope_all(scope, default_scope='Mobilenet'), \
safe_arg_scope([slim.batch_norm], is_training=is_training), \
_set_arg_scope_defaults(conv_defs_defaults), \
_set_arg_scope_defaults(conv_defs_overrides):
# The current_stride variable keeps track of the output stride of the
# activations, i.e., the running product of convolution strides up to the
# current network layer. This allows us to invoke atrous convolution
# whenever applying the next convolution would result in the activations
# having output stride larger than the target output_stride.
current_stride = 1
# The atrous convolution rate parameter.
rate = 1
net = inputs
# Insert default parameters before the base scope which includes
# any custom overrides set in mobilenet.
end_points = {}
scopes = {}
for i, opdef in enumerate(conv_defs['spec']):
params = dict(opdef.params)
opdef.multiplier_func(params, multiplier)
stride = params.get('stride', 1)
if output_stride is not None and current_stride == output_stride:
# If we have reached the target output_stride, then we need to employ
# atrous convolution with stride=1 and multiply the atrous rate by the
# current unit's stride for use in subsequent layers.
layer_stride = 1
layer_rate = rate
rate *= stride
else:
layer_stride = stride
layer_rate = 1
current_stride *= stride
# Update params.
params['stride'] = layer_stride
# Only insert rate to params if rate > 1.
if layer_rate > 1:
params['rate'] = layer_rate
# Set padding
if use_explicit_padding:
if 'kernel_size' in params:
net = _fixed_padding(net, params['kernel_size'], layer_rate)
else:
params['use_explicit_padding'] = True
end_point = 'layer_%d' % (i + 1)
try:
net = opdef.op(net, **params)
except Exception:
print('Failed to create op %i: %r params: %r' % (i, opdef, params))
raise
end_points[end_point] = net
scope = os.path.dirname(net.name)
scopes[scope] = end_point
if final_endpoint is not None and end_point == final_endpoint:
break
# Add all tensors that end with 'output' to
# endpoints
for t in net.graph.get_operations():
scope = os.path.dirname(t.name)
bn = os.path.basename(t.name)
if scope in scopes and t.name.endswith('output'):
end_points[scopes[scope] + '/' + bn] = t.outputs[0]
return net, end_points
参考文献
- MobileNetV2: Inverted Residuals and Linear Bottlenecks, Mark-Sandler, 2018
- https://github.com/tensorflow/models/tree/master/research/slim/nets/mobilenet