作者:陈勇吏 (上海交通大学安泰经济与管理学院)
Stata 连享会: 知乎 | | 码云 | CSDN
Stata连享会 计量专题 || 精品课程 || 推文 || 公众号合集

连享会计量方法专题……
这一部分我们将讨论随机数的产生原理,以及随机数的代码实现方式。在介绍随机数之前,我们先简单介绍一下蒙特卡洛模拟和随机数的概念。
假设是一个随机变量,其分布函数为,概率密度函数为。我们可能会对感兴趣(是一个给定的函数)。比如,若随机变量代表产品的销量,则销售利润可以表示为,这也是一个随机变量。在已知随机变量概率分布的情况下,我们希望知道销售利润的期望值是多少。带入随机变量的期望公式得到:,可以很容易求出积分结果。
但现实生活中,我们感兴趣的中的往往不是单一的随机变量,而是由多个随机变量组成的随机向量。若已知随机向量的联合概率密度函数,则:。多数情况下,这个多重积分很难求解。此时,我们考虑另一种方式来近似计算的值。
近似计算方法:
:产生一个联合概率密度函数为的随机向量,并计算。
:重复次的过程,得到独立同分布的。
:使用的平均值(样本均值)来近似(总体均值)。
上述近似计算方法称为蒙特卡洛模拟方法。即通过从相同的概率分布中多次抽取独立同分布的样本,使用 样本平均值 近似 总体平均值。将每一次抽取到的独立同分布的样本记为,则样本中的每一个元素都是一个随机变量。我们将这种从给定的概率分布中抽取出来的独立的随机变量,称为随机数。
1.如何产生随机数
随机变量的分布形式多种多样,包括连续性随机变量、离散型随机变量。其中连续性随机变量包括均匀分布、指数分布等可以写出分布函数形式的随机变量,以及正态分布、卡方分布等只存在概率密度函数形式的随机变量。针对不同的概率分布形式,生成随机数的方式有所不同。但生成任意分布的随机数的基础,是生成服从均匀分布的随机数,其他分布的随机数是在随机数的基础上产生。
1.1 均匀分布的随机数
1.1.1 产生过程
产生分布的一种方式是:将写有的完全相同的 10 个纸条放在一个盒子中,每次从中有放回地抽取一张纸条,连续抽取次。将抽取到的个数字按 抽取顺序 排列在小数点的后面,得到的数字即为服从均匀分布的随机数。例如:如果抽取的数字序列是,则得到的服从分布的随机数是。
然而,数字计算机通常不使用这种方式来产生随机数,而是使用伪随机数来代替随机数。伪随机数的产生原理是取模。即给定一个初始值,通过递归公式可以得到一个序列,其中是设定的正整数。该等式表示将除以的余数赋值给,因此序列中的每个都只能在中取值。是一个在之间取值的数,可以看做近似服从均匀分布。可以看出,当设定合适的值后,得到的伪随机数序列完全取决于给定的序列初始值,这个初始值称为种子。设定相同的种子,可以得到完全相同的随机序列。这也是伪随机数的优点之一:可以重复相同的模拟过程。
1.1.2 stata代码实现
Stata有很多用来产生随机数的内置函数,其中生成均匀分布随机数的函数为runiform()。在生成随机数前,可以通过set seed #命令设定随机数的初始值(种子)。具体代码如下:
- 生成 3 个的随机数序列,每个序列包含 10 个随机数。
*===== 代码 =====
clear
set obs 10
forvalues i = 1/3 {
gen unif`i' = runiform()
}
*===== 生成结果 =====
unif1 unif2 unif3
.1387824 .56928813 .32682486
.92432766 .7060023 .30766002
.3676381 .81376687 .21982671
.11971952 .06189653 .69186391
.91902139 .27757641 .04663675
.60349285 .41005086 .60378652
.89752506 .22520046 .52267927
.48974351 .34788238 .23261151
.21933775 .17111017 .92006581
.88946164 .72442917 .39863705
/* 三次模拟,产生三个不同的随机数序列 */
- 生成 3 个的随机数序列,每个随机数序列都设定相同的种子。
*===== 代码 =====
clear
set obs 10
forvalues i = 1/3 {
set seed 10
gen unif`i' = runiform()
}
*===== 生成结果 =====
unif1 unif2 unif3
.60128311 .60128311 .60128311
.91370436 .91370436 .91370436
.26673195 .26673195 .26673195
.60736577 .60736577 .60736577
.03607367 .03607367 .03607367
.75318004 .75318004 .75318004
.45917266 .45917266 .45917266
.90569935 .90569935 .90569935
.31343658 .31343658 .31343658
.3755541 .3755541 .3755541
/* 设定相同的随机数,三次模拟都产生相同的随机数序列。*/
连享会计量方法专题……
1.2 连续型随机变量的随机数
对于任意给定的连续型随机变量,若分布函数已知,则该随机变量的随机数可以通过获得,其中为的随机数。换言之,连续型随机变量的随机数,可以通过对求分布函数的逆运算获得。
证明:记,则的分布函数满足
证得,通过得到的随机数服从分布。
Stata代码实现
生成连续型随机变量的随机数函数包括:均匀分布 runiform(a,b)、正态分布 rnormal(m,s)、指数分布 rexponential(b)、卡方分布 rchi2(df)、t 分布 rt(df) 等。详细内容可以通过 help random 命令查看。
生成随机数的具体代码如下所示:
- 使用 Stata 的内置函数生成随机数
*========== 代码:生成随机数序列 ==========
* 1.生成随机数序列
clear
set obs 1000
*1.1 U(1,5)均匀分布的随机数序列
gen runif = runiform()
*1.2 指数分布 Exp(5) 的随机数序列
gen exp = rexponential(5)
*1.3 标准正态分布的随机数序列
gen rnormal = rnormal()
*1.4 N(3,2)正态分布的随机数序列
gen rnormal_3_2 = rnormal(3, 2)
*1.5 自由度为 3 的 t 分布的随机数序列
gen rt = rt(3)
*1.6 自由度为 43 的卡方分布的随机数序列
gen rchi2 = rchi2(43)
* 2.随机数序列的分布图
foreach dist in runif exp rnormal rnormal_3_2 rt rchi2 {
histogram `dist', name(`dist', replace) nodraw //kdensity
}
graph combine runif exp rnormal rnormal_3_2 rt rchi2
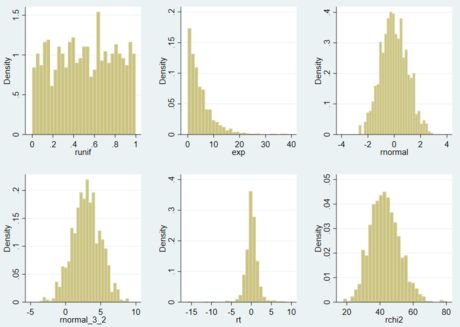
- 使用分布函数求逆的方式生成随机数
指数分布的分布函数为:,反函数为
均匀分布的分布函数为:,反函数为
由于,故。所以,指数分布的随机数可以通过得到,均匀分布的随机数可以通过得到。
*========== 代码 ==========
clear
set obs 10
* 1.指数分布 Exp(5) 的随机数序列
set seed 20
gen exp_f = -5 * log(runiform()) //分布函数求逆的方式
set seed 20
gen exp = rexponential(5) //使用内置函数的方式
* 2.均匀分布 U(1,5) 的随机数序列
set seed 20
gen unif_f = 1 + (5-1)*runiform() //分布函数求逆的方式
set seed 20
gen unif = runiform(1,5) //使用内置函数的方式
*========== 生成结果 ==========
exp_f exp unif_f unif
1.6727648 1.6727648 3.8626318 3.8626318
.47869168 .47869168 4.634807 4.634807
1.1330894 1.1330894 4.1889014 4.1889014
7.785189 7.785189 1.8430378 1.8430378
1.0036905 1.0036905 4.2725067 4.2725067
.02883674 .02883674 4.976997 4.976997
4.806301 4.806301 2.5296427 2.5296427
8.2741926 8.2741926 1.7644917 1.7644917
7.1020147 7.1020147 1.9664666 1.9664666
10.250074 10.250074 1.514932 1.514932
/* 可以看出,两种方式得到的随机数序列相同。 */
当感兴趣的随机变量在 Stata 中没有相应的内置函数来生成随机数时,可以通过分布函数求逆的方式计算。
1.3 离散型随机变量的随机数
对于任意给定的离散型随机变量,若概率分布为,则该随机变量的随机数同样可以通过对求分布函数的逆运算获得。具体方式为:令,
可以看出的概率分布为。
Stata代码实现
生成离散型随机变量的随机数函数包括:二项分布 rbinomial(n,p)、超几何分布 rhypergeometric(N,K,n)、泊松分布 rpoisson(m)、负二项分布 rnbinomial(n,p) 等。详细内容可以通过 help random 命令查看。
生成随机数的具体代码如下所示:
*========== 代码:生成随机数序列 ==========
* 1.生成随机数序列
clear
set obs 1000
*1.1 二项分布 B(10,0.5) 的随机数序列
gen rbinomial = rbinomial(10,0.5)
*1.2 超几何分布 H(20,4,10) 的随机数序列
/*
其中:20 代表总体数量
4 代表总体中指定种类的数量
10 代表抽取的样本数量
*/
gen rhypergeometric = rhypergeometric(20,4,10)
*1.3 泊松分布 Poisson(20) 的随机数序列
gen rpoisson = rpoisson(20)
*1.4 负二项分布 NB(123,0.2) 的随机数序列
gen rnbinomial = rnbinomial(123,0.2)
* 2.随机数序列的分布图
foreach dist in rbinomial rhypergeometric rpoisson rnbinomial {
histogram `dist', name(`dist', replace) nodraw //kdensity
}
graph combine rbinomial rhypergeometric rpoisson rnbinomial
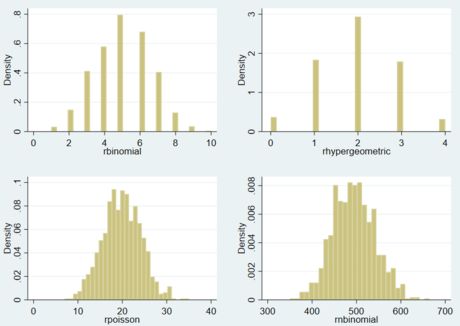
连享会计量方法专题……
2. 如何产生具有相关性的随机数
Stata 提供了 drawnorm 命令,可以从多元正态分布中生成随机数序列。具体语法为
drawnorm newvarlist [, options],常用的 option 选项包括:
-
corr(matrix):设定多元正态分布的协方差矩阵 -
mean(vector):设定多元正态分布的均值向量,默认为mean(0)。
具体规则可以查看help drawnorm。
2.1 相关性
Pearson 相关系数和 Spearman 相关系数是衡量变量相关性最常用的两个指标。
- Pearson相关系数
用来衡量变量间的线性关系。计算公式为 - Spearman相关系数
等级变量的 Pearson 相关系数。将两个变量分别排序以后生成相应的等级数据,使用两个变量对应的等级数据计算 Pearson 相关系数。
Stata 举例如下:
clear
set obs 1000
* 1.生成相关系数矩阵
/*
相关系数矩阵是对称矩阵,矩阵“维数”与待生成的“随机序列个数”一致。
其中:
(第i个)主对角元素:代表(第i个)随机变量的【方差】,
(第 i行j列 的)非主对角元素:代表(第i,j)两个随机变量间的【协方差】
*/
matrix C = (1, 0.5 \ 0.5, 1)
matrix list C
*======= Stata 结果 ========
symmetric C[2,2]
c1 c2
r1 1
r2 .5 1
*===========================
* 2.生成二元正态分布样本(生成两个随机数序列:均值为 0,协方差矩阵为 C)
drawnorm x y, corr(C) //means(0,0)选项设定均值向量为(0,0),可省略不写
* 3.查看两个随机序列的相关性
*3.1 Pearson相关系数
corr x y
*========== Stata 结果 ===========
(obs=1,000)
| x y
-------------+------------------
x | 1.0000
y | 0.5218 1.0000
*=================================
*3.2 Spearman相关系数
*3.2.1 使用 Pearson系数 计算 Spearman相关系数
sort x
gen rank_x = _n
sort y
gen rank_y = _n
corr rank_x rank_y
*========== Stata 结果 ===========
(obs=1,000)
| rank_x rank_y
-------------+------------------
rank_x | 1.0000
rank_y | 0.5011 1.0000
*=================================
*3.2.2 使用 内置函数 计算 Spearman相关系数
spearman x y
*========== Stata 结果 ===========
Number of obs = 1000
Spearman's rho = 0.5011
Test of Ho: x and y are independent
Prob > |t| = 0.0000
*=================================*
/* 两种方式得到的 Spearman相关系数 相等,都等于 0.5011。*/
从 Pearson 和 Spearman 两个相关系数的定义及计算公式可以看出:对变量做正的线性变换,变量间的 Pearson 相关系数不变;对变量做非负的函数变换, 变量间的 Spearman 相关系数保持不变。
2.2 产生具有相关性的随机序列
产生具有相关性的正态分布随机序列,可以使用 Stata 的 drawnorm 命令。产生具有相关性的其他分布的随机数序列没有现成的 Stata 命令,可以先将 drawnorm 得到的正态随机序列转换为均匀分布,然后通过分布函数求逆的方式得到想要的随机数序列。原理如下:
- 分布函数服从均匀分布
若是正态分布的随机序列,是正态分布的分布函数,则是均匀分布的随机序列。
* 1.生成均匀分布随机序列
clear
set obs 10000
*1.1 生成两个相关的正态随机序列:x,y
matrix C = (1, 0.5 \ 0.5, 1)
drawnorm x y, corr(C)
*1.2 根据正态分布函数,生成与 x,y 对应的均匀分布序列:x_unif,y_unif
gen x_unif = normal(x)
gen y_unif = normal(y)
*1.3 作图展示生成的随机数序列的分布情况
foreach dist in x y x_unif y_unif {
hist `dist', name(`dist', replace) nodraw
}
graph combine x y x_unif y_unif
/* 可以看出,生成的 x_unif y_unif 两个随机序列在 (0,1) 上均匀分布 */
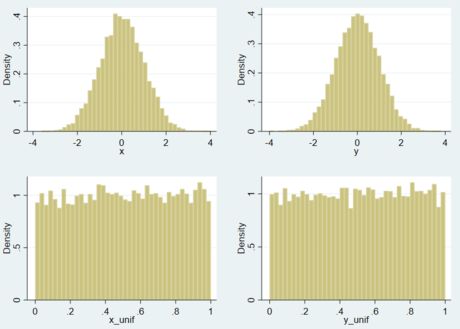
- 分布函数是单调不减函数,故与具有相同的 Spearman 系数
可以验证,上面代码中生成的x_unif和y_unif之间的 Spearman 相关系数,与正态序列x和y之间的 Spearman 相关系数是一样的。
* 1.1 正态序列的 Spearman值
spearman x y
/*============= Stata 结果 =============
Number of obs = 10000
Spearman's rho = 0.4917
Test of Ho: x and y are independent
Prob > |t| = 0.0000
*======================================*/
* 1.2 生成的均匀分布序列的 Spearman值
spearman x_unif y_unif
/*============= Stata 结果 =============
Number of obs = 10000
Spearman's rho = 0.4917
Test of Ho: x_unif and y_unif are independent
Prob > |t| = 0.0000
*======================================*/
但 Pearson 相关系数有所不同:
* 2.1 正态序列的 Pearson值
corr x y
/*============= Stata 结果 =============
(obs=10,000)
| x y
-------------+------------------
x | 1.0000
y | 0.5046 1.0000
*======================================*/
* 2.2 生成的均匀分布序列的 Pearson值
corr x_unif y_unif
/*============= Stata 结果 =============
(obs=10,000)
| x_unif y_unif
-------------+------------------
x_unif | 1.0000
y_unif | 0.4912 1.0000
*======================================*/
/* 可以看出,两组变量的 Spearson 系数值完全一样,
两组变量的 Pearson 系数值有些微不同 */
- 任意分布的随机序列都可以通过的方式得到
使用 Stata 内置的逆分布函数invgamma()和invexponential(),带入正态分布产生的均匀分布,生成伽马 Gamma随机序列和指数 Exponential随机序列:
* 1.生成 Gamma 随机序列和 Exponential 随机序列
gen x_gamma = invgammap(4, x_unif)
gen y_exponential = invexponential(1, y_unif)
* 2.做序列的分布图
hist x_gamma, name(x_gamma, replace)
hist y_exponential , name(y_exponential , replace)

- 分布函数的反函数是单调不减函数,故与具有相同的 Spearman 系数
可以验证,上面代码中生成的伽马随机序列x_gamma和指数随机序列y_exponential之间的 Spearman 相关系数,与正态序列x和y之间的 Spearman 相关系数是一样的。
spearman x y
/*============= Stata 结果 =============
Number of obs = 10000
Spearman's rho = 0.4758
Test of Ho: x and y are independent
Prob > |t| = 0.0000
*======================================*/
spearman x_gamma y_exponential
/*============= Stata 结果 =============
Number of obs = 10000
Spearman's rho = 0.4758
Test of Ho: x_gamma and y_exponential are independent
Prob > |t| = 0.0000
*======================================*/
但 Pearson 相关系数有所不同:
spearman x y
/*============= Stata 结果 =============
(obs=10,000)
| x y
-------------+------------------
x | 1.0000
y | 0.4894 1.0000
*======================================*/
spearman x_gamma y_exponential
/*============= Stata 结果 =============
(obs=10,000)
| x_gamma y_expo~l
-------------+------------------
x_gamma | 1.0000
y_exponent~l | 0.4515 1.0000
*======================================*/
如此,drawnorm 命令不仅可以生成 正态 随机序列,也可以进一步通过分布函数求逆的方式得到相关性相同的 其他分布 的随机序列。使用 drawnorm 命令生成具有相关性的 非正态分布 随机序列的 Stata 完整代码如下所示:
clear
set obs 10000
* 1.定义相关系数矩阵
matrix C = ( 1, 0.7, -0.3, 0.2 \ ///
0.7, 1, 0.2, -0.1 \ ///
-0.3, 0.2, 1, 0.3 \ ///
0.2, -0.1, 0.3, 1)
* 2.生成 4 个相关系数矩阵为 C 的正态随机向量
drawnorm x1 x2 x3 x4, corr(C)
* 3.根据 逆分布函数 方法生成四个其他分布的随机序列
/*
四个分布包括:
自由度为5的卡方分布:chi2(5),
均值为5的泊松分布:poisson(5),
自由度为 5,5 的F分布:F(5,5)
在(-5,5)之间的均匀分布:uniform(-5,5)
*/
gen x_chi2 = invchi2(5, normal(x1))
gen x_poisson = invpoisson(5, 1-normal(x2)) // normal(x2) 和 1-normal(x2) 都是U(0,1)均匀分布的随机序列
gen x_F = invF(5, 5, normal(x3))
gen x_uniform = -5 + normal(x4)*10
* 4.查看四个生成序列的分布图
foreach dist in x_chi2 x_poisson x_F x_uniform {
hist `dist', name(`dist', replace) nodraw
}
graph combine x_chi2 x_poisson x_F x_uniform, imargin(large)
* 5.查看相关系数
mat list C
spearman x?
spearman x_*
corr x?
corr x_*

连享会计量方法专题……
3. 应用举例
在计量模型中,随机数可以很好的模拟扰动项的随机性,以及我们对数据特征的高质量要求。这有助于我们按照预计的分布特征去抽样,进而验证计量模型的有效性,比较计量模型的优劣。我们将引入一个简单的例子,介绍随机数如何应用于 似不相关回归(SUR) 和 OLS 的模型比较。
例子
我们考虑应用 似不相关回归(SUR) 方法来决定是否开发小行星铂金矿物资源的例子,具体内容参见 Pricing an Asteroid。
在本例中,我们尝试估计三个存在相关性的模型。三个模型具有相同的解释变量: 市场现有铂金数量 (X1),投资者们的平均年龄 (X2),宇宙飞船的新闻报道数量(X3)。被解释变量分别为:铂金价格 (Y1),宇宙飞船的投资金额 (Y2),宇宙飞船的新闻报道数量 (Y3)。
模型设定如下:
- 先生成三个解释变量:
. clear
. set obs 10000
. gen x1 = 10 + rnormal()
. gen x2 = 50 + rnormal()
. gen x3 = rpoisson(10)
- 生成三个线性相关的扰动项
. matrix C = (12, -5, 5 \ -5, 12, -3 \ 5, -3, 6 )
. drawnorm u1 u2 u3, cov(C)
- 生成三个被解释变量
若模型中的系数矩阵为
则生成被解释变量的 Stata 命令如下:
. gen y1 = 20 + 3*x1 + 0*x2 - 0.1*x3 + u1
. gen y2 = 5 + 3*x1 + 3.5*x2 + 5.2*x3 + u2
. gen y3 = 10 + 3*x1 + 5.3*x2 - 10*x3 + u3
- OLS 回归
. reg y1 x1 x2 x3
. reg y2 x1 x2 x3
. reg y3 x1 x2 x3
- SUR 回归
*-不加约束:
. sureg (y1 = x1 x2 x3) (y2 = x1 x2 x3) (y3 = x1 x2 x3)
*-加约束:三个模型的 x1 系数相等
. constraint 1 [y1]x1 = [y2]x1
. constraint 2 [y1]x1 = [y3]x1
. sureg (y1 = x1 x2 x3) (y2 = x1 x2 x3) (y3 = x1 x2 x3), const(1 2)
OLS 估计结果:
SUR 估计结果(不加约束):
SUR 估计结果(加约束):
用于生成的数据:
可以看出,当三个模型的解释变量完全相同时,若不加约束,则 SUR 与 OLS 的回归结果完全相同;若加约束,SUR 的回归结果比 OLS 更好一些。解释变量不同的情形可以参考 Seemingly Unrelated Regression-with Correlated Errors。
完整的 Stata 代码及回归结果如下:
clear
set obs 10000
gen x1 = 10 + rnormal()
gen x2 = 50 + rnormal()
gen x3 = rpoisson(10)
matrix C = (12, -5, 5 \ -5, 12, -3 \ 5, -3, 6 )
drawnorm u1 u2 u3, cov(C)
gen y1 = 20 + 3*x1 + 0*x2 - 0.1*x3 + u1
gen y2 = 5 + 3*x1 + 3.5*x2 + 5.2*x3 + u2
gen y3 = 10 + 3*x1 + 5.3*x2 - 10*x3 + u3
// OLS回归
reg y1 x1 x2 x3
reg y2 x1 x2 x3
reg y3 x1 x2 x3
// SUR回归
*-不加约束
sureg (y1 = x1 x2 x3) (y2 = x1 x2 x3) (y3 = x1 x2 x3)
*-加约束
constraint 1 [y1]x1 = [y2]x1
constraint 2 [y1]x1 = [y3]x1
sureg (y1 = x1 x2 x3) (y2 = x1 x2 x3) (y3 = x1 x2 x3), const(1 2)
*========================= OLS 回归结果 =======================
. reg y1 x1 x2 x3
Source | SS df MS Number of obs = 10,000
---------+---------------------------------- F(3, 9996) = 2627.73
Model | 95478.2491 3 31826.083 Prob > F = 0.0000
Residual | 121067.806 9,996 12.1116252 R-squared = 0.4409
---------+---------------------------------- Adj R-squared = 0.4407
Total | 216546.055 9,999 21.6567711 Root MSE = 3.4802
----------------------------------------------------------------------
y1 | Coef. Std. Err. t P>|t| [95% Conf. Interval]
---------+------------------------------------------------------------
x1 | 3.043426 .0346424 87.85 0.000 2.97552 3.111332
x2 | -.0491475 .034845 -1.41 0.158 -.1174508 .0191557
x3 | -.1155822 .010902 -10.60 0.000 -.1369523 -.0942122
_cons | 22.22404 1.782452 12.47 0.000 18.73008 25.71801
----------------------------------------------------------------------
. reg y2 x1 x2 x3
Source | SS df MS Number of obs = 10,000
---------+---------------------------------- F(3, 9996) = 80558.04
Model | 2948482.24 3 982827.414 Prob > F = 0.0000
Residual | 121953.602 9,996 12.2002403 R-squared = 0.9603
---------+---------------------------------- Adj R-squared = 0.9603
Total | 3070435.85 9,999 307.074292 Root MSE = 3.4929
-----------------------------------------------------------------------
y2 | Coef. Std. Err. t P>|t| [95% Conf. Interval]
---------+-------------------------------------------------------------
x1 | 2.943839 .0347689 84.67 0.000 2.875685 3.011993
x2 | 3.565666 .0349722 101.96 0.000 3.497114 3.634219
x3 | 5.202808 .0109418 475.50 0.000 5.18136 5.224256
_cons | 2.263563 1.78896 1.27 0.206 -1.243159 5.770286
-----------------------------------------------------------------------
. reg y3 x1 x2 x3
Source | SS df MS Number of obs = 10,000
---------+---------------------------------- F(3, 9996) > 99999.00
Model | 10622883.6 3 3540961.19 Prob > F = 0.0000
Residual | 61363 9,996 6.13875551 R-squared = 0.9943
---------+---------------------------------- Adj R-squared = 0.9943
Total | 10684246.6 9,999 1068.53151 Root MSE = 2.4777
-----------------------------------------------------------------------
y3 | Coef. Std. Err. t P>|t| [95% Conf. Interval]
---------+-------------------------------------------------------------
x1 | 2.996978 .0246631 121.52 0.000 2.948633 3.045322
x2 | 5.278252 .0248073 212.77 0.000 5.229624 5.326879
x3 | -10.00558 .0077615 -1289.13 0.000 -10.02079 -9.990367
_cons | 11.2074 1.268986 8.83 0.000 8.719934 13.69487
-----------------------------------------------------------------------
*===================== SUR 回归结果:不加约束 ====================
. sureg (y1 = x1 x2 x3) (y2 = x1 x2 x3) (y3 = x1 x2 x3)
Seemingly unrelated regression
-------------------------------------------------------------------
Equation Obs Parms RMSE "R-sq" chi2 P
-------------------------------------------------------------------
y1 10,000 3 3.47948 0.4409 7886.35 0.0000
y2 10,000 3 3.492186 0.9603 241770.82 0.0000
y3 10,000 3 2.477156 0.9943 1.73e+06 0.0000
-------------------------------------------------------------------
------------------------------------------------------------------------
| Coef. Std. Err. z P>|z| [95% Conf. Interval]
----------+-------------------------------------------------------------
y1 |
x1 | 3.043426 .0346355 87.87 0.000 2.975541 3.11131
x2 | -.0491475 .034838 -1.41 0.158 -.1174288 .0191337
x3 | -.1155822 .0108998 -10.60 0.000 -.1369454 -.094219
_cons | 22.22404 1.782095 12.47 0.000 18.7312 25.71688
----------+-------------------------------------------------------------
y2 |
x1 | 2.943839 .034762 84.69 0.000 2.875707 3.011971
x2 | 3.565666 .0349652 101.98 0.000 3.497136 3.634197
x3 | 5.202808 .0109396 475.59 0.000 5.181366 5.224249
_cons | 2.263563 1.788603 1.27 0.206 -1.242033 5.76916
----------+-------------------------------------------------------------
y3 |
x1 | 2.996978 .0246581 121.54 0.000 2.948649 3.045307
x2 | 5.278252 .0248023 212.81 0.000 5.22964 5.326863
x3 | -10.00558 .0077599 -1289.39 0.000 -10.02079 -9.990372
_cons | 11.2074 1.268732 8.83 0.000 8.720733 13.69407
------------------------------------------------------------------------
*===================== SUR 回归结果:加约束 ====================
. constraint 1 [y1]x1 = [y2]x1
. constraint 2 [y1]x1 = [y3]x1
. sureg (y1 = x1 x2 x3) (y2 = x1 x2 x3) (y3 = x1 x2 x3), const(1 2)
Seemingly unrelated regression
-------------------------------------------------------------------
Equation Obs Parms RMSE "R-sq" chi2 P
-------------------------------------------------------------------
y1 10,000 3 3.479975 0.4408 36858.93 0.0000
y2 10,000 3 3.492431 0.9603 271242.65 0.0000
y3 10,000 3 2.477185 0.9943 1.75e+06 0.0000
-------------------------------------------------------------------
( 1) [y1]x1 - [y2]x1 = 0
( 2) [y1]x1 - [y3]x1 = 0
-------------------------------------------------------------------------
| Coef. Std. Err. z P>|z| [95% Conf. Interval]
----------+--------------------------------------------------------------
y1 |
x1 | 2.985018 .015583 191.56 0.000 2.954476 3.01556
x2 | -.0495507 .0348408 -1.42 0.155 -.1178374 .018736
x3 | -.1160189 .0108984 -10.65 0.000 -.1373794 -.0946584
_cons | 22.83197 1.752945 13.02 0.000 19.39626 26.26768
----------+--------------------------------------------------------------
y2 |
x1 | 2.985018 .015583 191.56 0.000 2.954476 3.01556
x2 | 3.565951 .0349683 101.98 0.000 3.497414 3.634487
x3 | 5.203116 .0109383 475.68 0.000 5.181677 5.224554
_cons | 1.834963 1.759306 1.04 0.297 -1.613212 5.283139
----------+--------------------------------------------------------------
y3 |
x1 | 2.985018 .015583 191.56 0.000 2.954476 3.01556
x2 | 5.278169 .024802 212.81 0.000 5.229558 5.32678
x3 | -10.00567 .0077586 -1289.62 0.000 -10.02088 -9.990464
_cons | 11.33189 1.253044 9.04 0.000 8.875964 13.78781
-------------------------------------------------------------------------
参考资料
- Introduction to Probability Models, Sheldon M.Ross 10th Edition.pdf
- Generating 'random' variables drawn from any distribution
- Drawing jointly distributed non-normal random variables
- Generate rank correlated variables
- Seemingly Unrelated Regression-with Correlated Errors
- Write your own System OLS in Mata
关于我们
- 【Stata 连享会(公众号:StataChina)】由中山大学连玉君老师团队创办,旨在定期与大家分享 Stata 应用的各种经验和技巧。
- 公众号推文同步发布于 CSDN-Stata连享会 、-Stata连享会 和 知乎-连玉君Stata专栏。可以在上述网站中搜索关键词
Stata或Stata连享会后关注我们。 - 点击推文底部【阅读原文】可以查看推文中的链接并下载相关资料。
- Stata连享会 计量专题 || 精彩推文
联系我们
- 欢迎赐稿: 欢迎将您的文章或笔记投稿至 [email protected],我们会保留您的署名;录用稿件达
五篇以上,即可免费获得 Stata 现场培训 (初级或高级选其一) 资格。您也可以从 连享会选题平台 → [002_备选主题] 中选择感兴趣的题目来撰写推文,网址为:https://gitee.com/Stata002/StataSX2018/wikis/Home。 - 招募英才: 欢迎加入我们的团队,一起学习 Stata。合作编辑或撰写稿件五篇以上,即可免费获得 Stata 现场培训 (初级或高级选其一) 资格。
- 联系邮件: [email protected]
往期精彩推文
Stata连享会 计量专题 || 精品课程 || 推文 || 公众号合集

 image
image