一. 什么是hadoop
hadoop是一个具有分布式存储和分布式计算能力的分布式软件系统
hadoop基本特点
- 可靠性(数据冗余)
- 成本低(把数据存储在普通的计算机上)
- 效率高(把计算分发到多个节点)
- 可扩容(根据需求, 动态的调整节点集群的大小)
二. 解决的问题
- 海量数据可靠存储
- 海量数据分析与计算
三. 应用场景
- 搜索引擎
- 日志分类和检索
- 数据报表(一般是内网, 不需要公网访问)
四. NFS
NFS即网络文件系统, 多台主机共享服务器中的数据
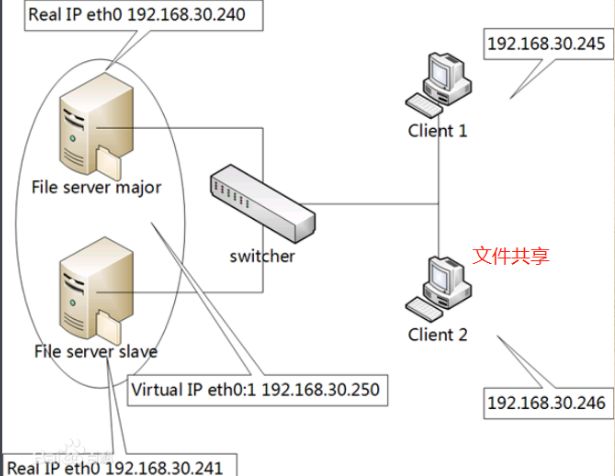
但是这种文件系统存在一些缺陷
- 缺少数据冗余
- 数据集中, 无法进行分布式计算
五. 系统架构
主要分为三部分
- 海量数据存储: hdfs
- 海量数据分析: mapreduce
- 资源调度: yarn
5.1 HDFS
HDFS是一个可靠的有容错机制的分布式文件系统
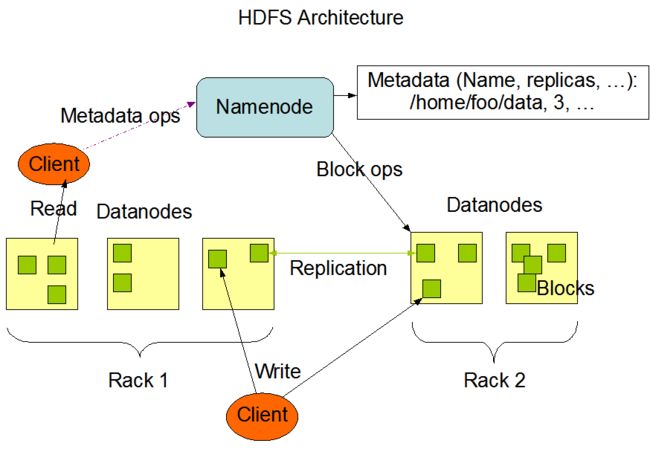
- HDFS系统由一个命名节点(nameNode)和多个数据节点(dataDode)构成
- 写数据可以在dataNode中直接写, 也可以先通过nameNode再随机选一个dataNode
- 读取数据的时候, 通过nameNode查询映射关系,再查询指定的数据节点
- 支持构造一个伪分布式系统, 在一台机器上运行多个数据节点
- nameNode响应用户请求,执行mkdir put get list等文件管理操作
5.1.1 数据分块
一个文件被分为多个数据块, 数据块的大小可配置, 除了最后一个数据块以外, 其他的数据块大小一样, 默认128M

5.1.2 副本选择
5.1.2.1 数据块写
每个数据块的冗余副本数可配置

首先了解下rack的概念, rack, 机架, 通过配置将一个区域的机器放到一个机架中, 通常一个机架内部节点之间的通信速度较快
(简单理解为一个机房即可)
副本选择算法如下:
- 数据块插入的节点存储数据块的第一副本(如果是通过nameNode插入, 那么随机选一个数据节点存储数据块的第一副本)
- 选择其他的rack(机架), 将第二和第三副本写入这个rack(机架)的两个不同的数据节点
- 如果副本数配置大于3, 则剩余的副本随机分不到不同的dataNode节点
这种策略既保证了数据的可靠性, 又一定程度上提高了性能
示例:

该架构中,存在1个hadoop集群, 3个机架(rack), 一个nameNode, 8个dataNode分布在3个机架上
以下是写请求的全过程:
首先客户端对文件进行切分
- 客户端向nameNode发起写请求
- nameNode创建文件名称, 返回需要插入的节点列表信息
- 客户端向host2写入block1
3.1. host2数据写成功后向客户端返回响应信息
3.1.1. 客户端通知nameNode,block1数据写入host2成功
3.2. host2数据写成功后, host2向rack2(集群中其他的随机rack)中的host1写入block1
3.2.1. host1数据写成功后, 向nameNode同步信息
3.2.2. host1数据写成功后, host1向rack2(2号副本和3号副本写入的rack是相同的)中的host3写入block1
3.2.2.1. host3数据写入成功后, 向nameNode同步信息
3.3. host2数据写成功后,向nameNode同步信息 - 客户端向host7写入block2
4.1. host7数据写成功后向客户端返回响应信息
4.1.1. 客户端通知nameNode,block2数据写入host7成功
4.2. host7数据写成功后, host7向rack3(集群中其他的随机rack)中的host8写入block2
4.2.1. host8数据写成功后, 向nameNode同步信息
4.2.2. host8数据写成功后, host8向rack3(2号副本和3号副本写入的rack是相同的)中的host4写入block2
4.2.2.1. host4数据写入成功后, 向nameNode同步信息
4.3. host2数据写成功后,向nameNode同步信息 - 文件写入完成
注:
- 3.1和3.2和3.3并行执行
- 4.1和4.2和4.3并行执行
- 3.2.1和3.2.2并行执行
- 4.2.1和4.2.2并行执行
在hadoop支持存储类型和存储策略之后, 保存文件的时候可以指定存储策略, 只有支持对应的存储类型的数据节点上才可以
保存这种数据, 如果支持这种存储策略的节点不足(少于副本数配置),则执行备选方案
5.1.2.2 数据库读
读取数据的时候优先选择离用户最近的rack(机架)
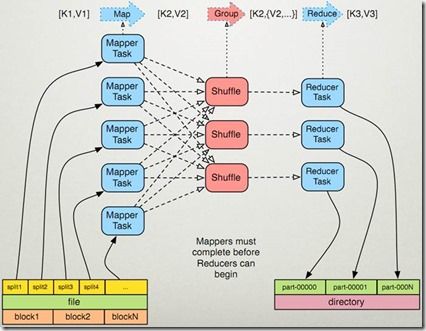
5.2 MapReduce
主要用于分布式数据计算, 可以使用上次分享的spark来替代
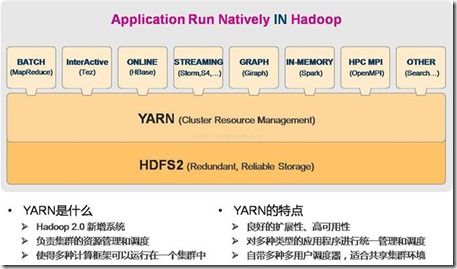
5.3 Yarn
主要用于资源调度, 2.x版本引入, 是hadoop重要组件
hadoop1.0和2.0的区别
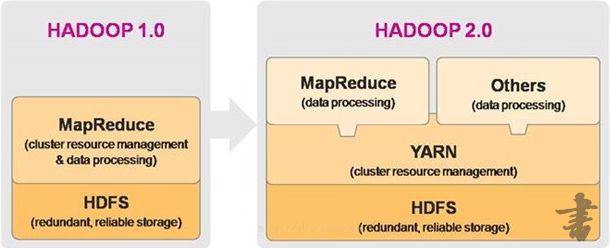
yarn在hadoop中的角色
yarn运行过程
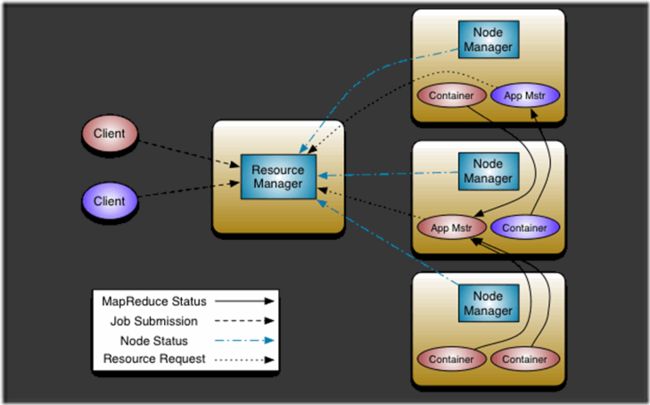
- resourceManager: 资源管理器, 全局只有一个
- nodeManager: 节点管理器, 每个节点对应一个,向resourceManager同步节点信息(CPU内存等等)
- application master: 应用管理器,负责处理节点内部的任务的分配
- container: 资源的抽象, application master负责分配自己所在节点的资源给某个task(任务),这组资源就被抽象为container
客户端提交任务到resourceManager, 然后resourceManager进行资源分配
数据节点之间使用RPC通信,比如Container处理后的数据传递给其他节点的application master
六. 安装
- 安装JDK1.8
- 安装hadoop3.1.2
七. 配置
单机伪分布式
1.配置环境变量~/.bashrc
export JAVA_HOME=/root/jdk1.8.0_121
export PATH=$PATH:$JAVA_HOME/bin
export HADOOP_HOME=/root/hadoop-3.1.2
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
- 配置hadoop-env.sh
export JAVA_HOME=/root/jdk1.8.0_121
export HDFS_NAMENODE_USER="root"
export HDFS_DATANODE_USER="root"
export HDFS_SECONDARYNAMENODE_USER="root"
export YARN_RESOURCEMANAGER_USER="root"
export YARN_NODEMANAGER_USER="root"
- 配置core-site.xml
fs.defaultFS
hdfs://server1:9000
io.file.buffer.size
131072
- 配置mapred-site.xml
mapreduce.framework.name
yarn
mapreduce.map.memory.mb
1500
每个Map任务的物理内存限制
mapreduce.reduce.memory.mb
3000
每个Reduce任务的物理内存限制
mapreduce.map.java.opts
-Xmx1200m
mapreduce.reduce.java.opts
-Xmx2600m
mapreduce.framework.name
yarn
- 配置workers
server1 # 本机
- 配置yarn-site.xml
yarn.resourcemanager.hostname
server1
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.application.classpath
/root/hadoop-3.1.2/etc/hadoop:/root/hadoop-3.1.2/share/hadoop/common/lib/*:/root/hadoop-3.1.2/share/hadoop/common/*:/root/hadoop-3.1.2/share/hadoop/hdfs:/root/hadoop-3.1.2/share/hadoop/hdfs/lib/*:/root/hadoop-3.1.2/share/hadoop/hdfs/*:/root/hadoop-3.1.2/share/hadoop/mapreduce/lib/*:/root/hadoop-3.1.2/share/hadoop/mapreduce/*:/root/hadoop-3.1.2/share/hadoop/yarn:/root/hadoop-3.1.2/share/hadoop/yarn/lib/*:/root/hadoop-3.1.2/share/hadoop/yarn/*
yarn.nodemanager.resource.memory-mb
22528
每个节点可用内存,单位MB
yarn.scheduler.minimum-allocation-mb
1500
单个任务可申请最少内存,默认1024MB
yarn.scheduler.maximum-allocation-mb
16384
单个任务可申请最大内存,默认8192MB
- 配置hdfs-site.xml
dfs.namenode.name.dir
/var/lib/hadoop/hdfs/name/
dfs.blocksize
268435456
dfs.namenode.handler.count
100
dfs.datanode.data.dir
/var/lib/hadoop/hdfs/data/
dfs.replication
1
dfs.http.address
server1:50070
八. 启动
start-dfs.sh
start-yarn.sh
两个网站被启动
server1:50070 文件查看
server:8088 节点状态查看
九. 基本操作
hadoop fs -mkdir /testdir
hadoop fs -put /root/xxx /testdir
hadoop fs -get xxx xxx
hadoop fs -ls /
# 计算圆周率
hadoop jar hadoop-mapreduce-examples-3.1.2.jar pi 5 5
# word count
hadoop jar hadoop-mapreduce-examples-3.1.2.jar wordcount /wordcount/input /wordcount/output
十. 文件目录
- 启动命令执行目录: /hadoop-3.1.2/sbin
- 配置文件目录: /hadoop-3.1.2/etc/hadoop
- mapreduce example所在目录: /hadoop-3.1.2/share/hadoop/yarn
十一. 探讨
- 数据分块后, 数据就不完整了, 各个节点是否可以处理各自的数据块? 比如一个很大的文本文件
答: mapreduce进行文件split操作后, 除了第一个split块, 其他的split块自动跳过第一行, 该行数据不作处理
参考: https://wiki.jikexueyuan.com/project/hadoop/read-data.html - 为啥不把整个文件多所有数据块写入同一个rack?
答: 因为写入多个rack, 读取的时候从不同的rack获取数据, 可以提高读取数据的速度, 不会因为单个rack的带宽瓶颈
而降低IO性能
参考: https://blog.csdn.net/u010670689/article/details/82715181
参考
安装教程
https://blog.csdn.net/dream_an/article/details/80258283
hdfs 架构
http://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html
hdfs rack只看一张图
https://blog.51cto.com/zengzhaozheng/1347777
hadoop生态-图片好
https://www.cnblogs.com/zhangwuji/p/7594725.html
yarn 架构
https://www.cnblogs.com/wcwen1990/p/6737985.html