编译:AI100,本文经授权发布,转载请联系AI100.
英文:https://www.analyticsvidhya.com/blog/2017/03/introduction-to-gradient-descent-algorithm-along-its-variants/
前 言
无论是要解决现实生活中的难题,还是要创建一款新的软件产品,我们最终的目标都是使其达到最优状态。作为一名计算机科学专业的学生,我经常需要优化各种代码,以便提高其整体的运行速度。
一般情况下,最优状态会伴随问题的最佳解决方案。如果阅读近期发表的关于优化问题的文章的话,你会发现,优化问题在现实生活中扮演着非常重要的作用。
机器学习中的优化问题与我们刚刚提到的内容有些许不同。通常情况下,在优化的过程中,我们非常清楚数据的状态,也知道我们想要优化哪些区域。但是,在机器学习中,我们本就对“新数据”一无所知,更不要提优化问题了!
因此在机器学习中,我们对训练数据进行优化,随后再在全新的验证数据中检验其运行情况。
优化的广泛应用
目前,优化技术正被广泛应用于各种不同的领域中,例如:
结构——比如说:决定航天设计的外型。
经济——比如说:成本最低化。
物理——比如说:优化量子计算时间。
优化还有许多更为高级的应用,例如:提供最优运输路径,使货架空间最合理化等等。
许多受欢迎的机器算法都源于优化技术,例如:线性回归算法、K-最近邻算法、神经网络算法等等。在学术界以及各行各业中,优化研究比比皆是,优化应用随处可见。
在本篇文章中,我会向大家介绍梯度下降(GradientDescent)这一特殊的优化技术,在机器学习中我们会频繁用到。
目 录
什么是梯度下降?
运用梯度下降算法所面临的挑战
梯度下降算法的变式
梯度下降的实现过程
使用梯度下降算法的实用小贴士
附录
1. 什么是梯度下降?
我会以经典的登山案例来解释梯度下降的含义。
假设你现在在山顶处,必须抵达山脚下(也就是山谷最低处)的湖泊。但让人头疼的是,你的双眼被蒙上了无法辨别前进方向。那么,你会采取什么办法抵达湖泊处呢?

最好的办法就是查看一下周围的地势,观察有下降趋势的地面,这会帮助你迈出第一步。如果沿着下降的路线前进,那么你非常有可能到达湖泊。
以图形的形式呈现该处地势。注意下面的曲线图:
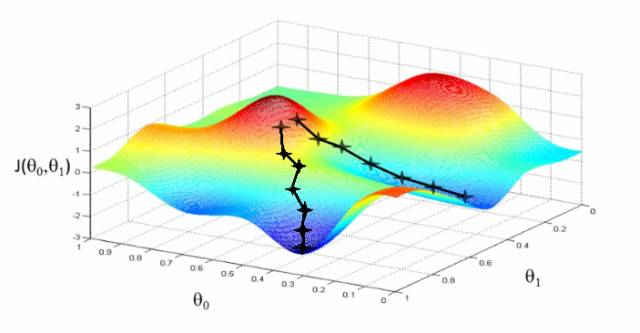
现在让我们用数学术语把这个情景绘制成地图吧。
为了学习梯度下降算法,假设我们需要找出最佳的参数(θ1)和(θ2)。与上述做法相似,在测绘“成本空间”时,我们需要找到相似的山脉和山谷。成本空间是指为参数选定了一个特殊值后,算法的运行情况。
所以,在Y轴上,我们让J(θ1)与X轴上的参数(θ1)以及Z轴上的参数(θ2)分别相交。在这里,数值高的红色区域代表山峰,数值低的蓝色区域代表山谷。
梯度下降算法的类型有很多种,主要分为两种:
基于数据的获取
1.全批梯度下降算法
2.随机梯度下降算法
在全批梯度下降算法中,需要利用全部数据同时计算梯度;然而在随机梯度下降算法中,通常只需选取其中一个样例来计算梯度。
基于微分技术
1.一阶微分
2.二阶微分
梯度下降需要通过成本函数微分来计算梯度。我们可以用一阶微分技术或者二阶微分技术来计算。
2. 运用梯度下降算法所面临的挑战
在大多数情况下,梯度下降是一种声音技术。但在很多情况下,梯度下降无法正常工作,甚至不工作。原因有三点:
数据挑战
梯度挑战
执行挑战
2.1 数据挑战
如果数据按照某种方式进行组合形成了一个非凸的优化问题,那么就很难利用梯度下降算法对其进行优化了。梯度下降算法只能解决那些意义非常明确的凸优化问题。
在优化凸问题时,可能会出现无数的极小点。最低点被称为全局最小值,其它的点被称为局部极小值。我们的目的是要达到全局极小值,而非局部极小值。
还有一个问题就是鞍点。梯度为零时,它是数据中的一个点,但是不是最优点。目前,我们还没有特定的方法来规避鞍点的出现,是一个新的研究领域。
2.2 梯度挑战
如果执行梯度下降算法时出现了错误,那么可能会导致诸如梯度消失或者梯度崩溃等的问题。当梯度太小或者太大时,就会出现这样的问题。也正因为这些问题,算法无法收敛。
2.3 执行挑战
通常情况下,大多数神经网络的开发者不会留意执行情况,但是观察网络资源利用率是非常重要的。比如,在执行梯度下降算法时,了解需要多少资源是非常重要的。如果应用程序的储存器太小,那么网络就会失败。
跟踪诸如浮点数的注意事项以及软/硬件的先决条件,也非常重要。
3. 梯度下降算法的变式
让我们来看一下最常用的梯度下降算法及其执行情况。
3.1 普通的梯度下降
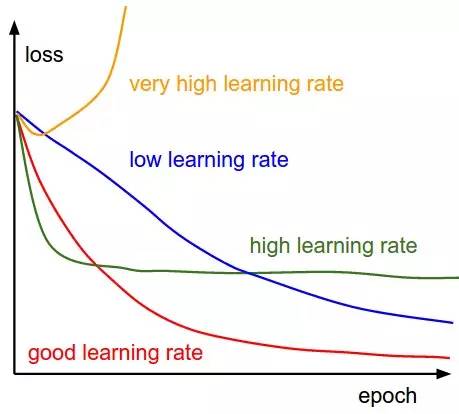
这是梯度下降技术中最简单的形式。此处的 vanilla 是纯净/不掺杂任何杂质的意思。它的主要特性就是,使我们向着成本函数梯度的最小值又迈进了一小步。
我们来看一下它的伪代码。
update=learning_rate*gradient_of_parameters
parameters=parameters-update
在这里,我们通过参数梯度来更新参数。而后通过学习率使其多样化,实质上,常数代表着我们期望的达到最小值的速率。学习率是一种超参数,其数值一旦确定,就需要我们认真对待。
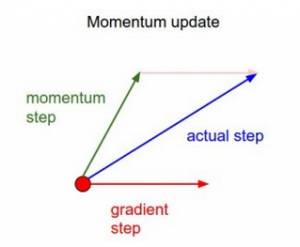
3.2 动量梯度下降
在进行下一步之前,我们先对之前的算法稍作调整,以便回顾前面的步骤。
这是一组伪代码。
update=learning_rate*gradient
velocity=previous_update*momentum
parameter=parameter+velocity–update
此处,更新后的代码与普通的梯度下降算法一样。但是考虑到之前的更新和常量(动量),我们引进了一个名为速率(velocity)的术语。
3.3 ADAGRAD 算法
ADAGRAD 算法使用了自适应技术来更新学习率。在这种算法中,我们会根据前期所有更迭的梯度变化情况,改变学习率。
这是一组伪代码。
grad_component=previous_grad_component+(gradient*gradient)
rate_change=square_root(grad_component)+epsilon
adapted_learning_rate=learning_rate*rate_change
update=adapted_learning_rate*gradient
parameter=parameter–update
在上述代码中,epsilon 是一个用于抑制学习率产生变动率的常量。
3.4 ADAM 算法
ADAM 算法是一种以 adagrad 算法为基础并且能进一步减少其缺点的更加自适应的技术。也就是说,你可以认为 ADAM 算法是动量和 ADAGRAD 算法的综合体。
这是一组伪代码。
adapted_gradient=previous_gradient+((gradient–previous_gradient)*(1–beta1))
gradient_component=(gradient_change–previous_learning_rate)
adapted_learning_rate=previous_learning_rate+(gradient_component*(1–beta2))
update=adapted_learning_rate*adapted_gradient
parameter=parameter–update
上述代码中的 beta1 和 beta2 是用来保持梯度和学习率不变的常量。
与此同时,还存在如 l-BFGS 等这样的二阶微分算法。你可以在 scipy 数据库中看到这种算法的执行情况。
4. 梯度下降的实现过程
现在我们来看一下利用 python 实现梯度下降的基础小案例。
在这里,我们将会利用梯度下降优化算法找出深度学习模型中图像识别应用问题的最佳参数。我们的问题是图像识别,从已给的28 x 28图像中分辨出其中的数字。我们有一个关于图像的子集,一部分图像用于训练模型,另一部分图像用于测试模型。在本篇文章中,我们会向大家介绍定义梯度下降算法的过程以及算法的运行过程。请参考这篇文章中有关利用 python 实现端到端运行的内容。
这是定义普通梯度下降算法的主代码:
params=[weights_hidden,weights_output,bias_hidden,bias_output]
defsgd(cost,params,lr=0.05):
grads=T.grad(cost=cost,wrt=params)
updates=[]
forp,ginzip(params,grads):
updates.append([p,p-g*lr])
returnupdates
updates=sgd(cost,params)
为了能更好的理解上述代码,接下来我们会分成不同的步骤详细讲解。
我们把 sgd 这个含有参数的函数分别定义为 cost、params 和 lr,分别代表上述例子中的 J(θ),θ是深度学习算法和学习率的参数。我们将默认的学习率设为0.05,但是学习率可以随着我们的喜好轻易地发生改变。
defsgd(cost,params,lr=0.05):
然后,我们定义关于这个成本函数的梯度参数。在这里,我们利用 theano 数据库来寻找梯度,T是我们将导入的 theano 数据:
grads=T.grad(cost=cost,wrt=params)
最后,通过所有参数的迭代找出所有可能需要更新的参数。大家可以看到,在这里我们使用的是普通梯度下降算法。
forp,ginzip(params,grads):
updates.append([p,p-g*lr]
接下来,我们可以利用这个函数找出神经网络中的最优参数。通过这个函数,我们发现神经网络非常擅长在图片中查找数据,如下图所示:
Predictionis:8

在这个实例中,我们了解到利用梯度下降算法能够得到深度学习算法中的最优参数。
5. 使用梯度下降算法的实用小贴士
对于上述提到的各种梯度下降算法,各有利弊。接下来,我会介绍一些能够帮助大家找到正确算法的实用方法。
如果是为了快速地获得原型,那就选取诸如Adam/Adagrad这样的自适应技术,这会让我们事半功倍,并且无须大量调优超参数。
如果是为了得到最好的结果,那就选取普通的梯度下降算法或者动量梯度下降算法。虽然利用梯度下降算法达到预期效果的过程很缓慢,但是大部分的结果比自适应技术要好得多。
如果你的数据偏小而且能够适应一次迭代,那么就可以选择诸如 l-BFGS这样的二阶技术。这是因为,二阶技术虽然速度非常快并且非常准确,但是只适用于数据偏小的情况。
还有一种是利用学习特性来预测梯度下降学习率的新兴方法(虽然我还没有尝试过这种新兴方法,但是看起来前途无量)。可以仔细地阅读一下这篇文章。
目前,无法学习神经网络算法的原因由很多。但是如果你能检查出算法出现错误的地方,对学习神经网络算法将会非常有帮助。
当选用梯度下降算法时,你可以看看这些能帮助你规避问题的小提示:
误码率——特定迭代之后,你应该检查训练误差和测试误差,并且确保训练误差和测试误差有所减少。如果事实并非如此,那么可能会出现问题!
隐含层数的梯度风气流——如果网络没有出现梯度消失或梯度爆炸问题,那么请检查一下网络。
学习率——选用自适应技术时,你应该检测一下学习率。
6. 附录
本篇文章参考了梯度下降优化算法概述(https://arxiv.org/abs/1609.04747)。
梯度下降 CS231n 课程教材(http://cs231n.github.io/neural-networks-3/)。
深度学习这本书的第四章(数值优化算法,http://www.deeplearningbook.org/contents/numerical.html)和第八章(深度学习模型的优化,http://www.deeplearningbook.org/contents/optimization.html)。
尾 声
我希望你喜欢这篇文章。在阅读完本篇文章后,你会对梯度下降算法及其变式有一定的了解。与此同时,我还在文章中向大家提供了执行梯度下降算法以及其变式算法的实用小贴士。希望对你有所帮助!
本文作者 Faizan Shaikh 是一名数据科学爱好者,目前正在研究深度学习,目标是利用自己的技能,推动 AI 研究的发展。