最近由于需要在带有标注的VID视频数据集上利用caffe工具训练模型,所以需要将该种类型的原始数据文件转换成为lmdb格式的数据文件。在可获得的资料上可以查到SSD: Single Shot MultiBoxDetector,这种目标检测方法效果不错而且利用的是专门用来进行视频目标检测的数据集VOC2007/2012进行数据处理的,和我所需要处理的数据格式类似。所以首先简单的利用作者github上的文件进行了复现,感觉该方法的处理效果不错,速度相比fast-rcnn快但还是较慢,我使用的显卡是gtx950m显卡,测试中速度大概FPS=8左右,还是较慢。而且当检测的图片/视频文件内目标增多时,出现目标丢失/漏检的情况比较多。。。下面是实验的过程:
- 在~/work/ssd/目录下clone作者github下的caffe文件包
git clone https://github.com/weiliu89/caffe.git
cd caffe
git checkout ssd(出现“分支”则说明copy-check成功...作者caffe目录下有三个分支fcn/master/ssd,利用git checkout来切换分支,否则只有master目录下的文件)
- 配置caffe所需文件进行编译
cp Makefile.config.example Makefile.config
根据电脑具体的配置修改Makefile.config(cudnn,opencv pythonpath等设置)具体可以参考Ubuntu16.04+CUDA8.0+caffe配置里面的Makefile.config和Makefile的设置。
make -j 8 all
make -j 8 runtest
make -j 8 pycaffe #model是通过python编写的文件进行训练的
tips:如果在make all的时候出现/src/caffe/util/xxx.cpp报错,如io.cpp,bbox_util.cpp等报错问题,根据查到的一些资料显示可能是作者在生成ssd的时候用的是opencv2.0,而此处我用的是opencv3.2,这两个版本的opencv有很多不同的地方导致了这个错误,[Opencv 3.0环境下编译SSD的问题以及解决方法。]。所以我按照下面的这种方法Ubuntu 16.04 + Opencv3.0 + gtx1080 + caffe(SSD) + ROS(Kinetic)可以配置成功:
cd ~/caffe
make clean
mkdir build
cd build
cmake ..
make all -j16
make install
make runtest
make pycaffe
- 下载预训练模型
链接:http://pan.baidu.com/s/1miDE9h2
密码:0hf2
将它放入caffe/models/VGGNet/目录下 - 下载VOC2007和VOC2012数据集,放到/home/data(需要在home目录下生成data文件夹)
cd ..
mkdir data
cd data/
- 下载数据集
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCtrainval_11-May-2012.tar
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtrainval_06-Nov-2007.tar
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtest_06-Nov-2007.tar
然后解压数据集,这样数据就准备好了,注意这里选择讲数据放置在/home/data内是因为训练时的脚本文件内的数据路径是这里,也可以不放置在该文件夹内,但是需要在脚本文件内更新数据的路径。
tar -xvf VOCtrainval_11-May-2012.tar
tar -xvf VOCtrainval_06-Nov-2007.tar
tar -xvf VOCtest_06-Nov-2007.tar
将图片转化为LMDB文件,用于训练。注意这两个文件对于我们训练ilsvrc数据集很有帮助!
cd ..
cd caffe/
./data/VOC0712/create_list.sh
./data/VOC0712/create_data.sh
- 开始训练
python examples/ssd/ssd_pascal.py
经过120000次的训练之后,我们可以得到所需要的带有超参数的训练model。
I0505 06:15:46.453992 7203 solver.cpp:596] Snapshotting to binary proto file models/VGGNet/VOC0712/SSD_300x300/VGG_VOC0712_SSD_300x300_iter_120000.caffemodel
I0505 06:15:47.089884 7203 sgd_solver.cpp:307] Snapshotting solver state to binary proto file models/VGGNet/VOC0712/SSD_300x300/VGG_VOC0712_SSD_300x300_iter_120000.solverstate
I0505 06:15:48.236326 7203 solver.cpp:332] Iteration 120000, loss = 4.45728
I0505 06:15:48.236359 7203 solver.cpp:433] Iteration 120000, Testing net (#0)
I0505 06:15:48.236398 7203 net.cpp:693] Ignoring source layer mbox_loss
I0505 06:24:21.998587 7203 solver.cpp:546] Test net output #0: detection_eval = 0.570833
I0505 06:24:22.015635 7203 solver.cpp:337] Optimization Done.
I0505 06:24:22.028441 7203 caffe.cpp:254] Optimization Done.
- 模型测试
(1)图片数据集上测试
python examples/ssd/score_ssd_pascal.py
输出为:
I0505 10:32:27.929069 16272 caffe.cpp:155] Finetuning from models/VGGNet/VOC0712/SSD_300x300/VGG_VOC0712_SSD_300x300_iter_120000.caffemodel
I0505 10:32:28.052016 16272 net.cpp:761] Ignoring source layer mbox_loss
I0505 10:32:28.053956 16272 caffe.cpp:251] Starting Optimization
I0505 10:32:28.053966 16272 solver.cpp:294] Solving VGG_VOC0712_SSD_300x300_train
I0505 10:32:28.053969 16272 solver.cpp:295] Learning Rate Policy: multistep
I0505 10:32:28.197612 16272 solver.cpp:332] Iteration 0, loss = 1.45893
I0505 10:32:28.197657 16272 solver.cpp:433] Iteration 0, Testing net (#0)
I0505 10:32:28.213793 16272 net.cpp:693] Ignoring source layer mbox_loss
I0505 10:42:04.390517 16272 solver.cpp:546] Test net output #0: detection_eval = 0.570833
I0505 10:42:04.414819 16272 solver.cpp:337] Optimization Done.
I0505 10:42:04.414847 16272 caffe.cpp:254] Optimization Done.
可以看到图片数据集上的检测结果为57.0833%。利用caffe/examples/ssd_detect.ipynb文件可以用单张图片测试检测效果(注意文件内加载文件的路径,如果报错修改为绝对路径):
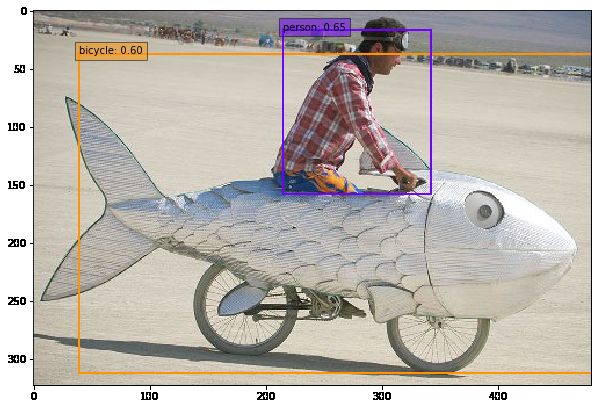
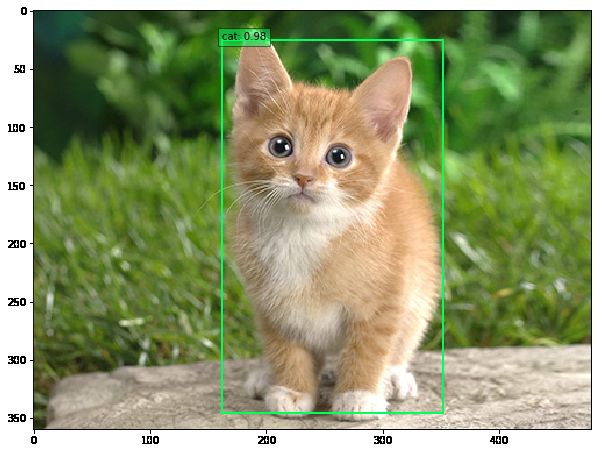

(2)视频数据测试
python examples/ssd/ssd_pascal_video.py
可得到测试结果:

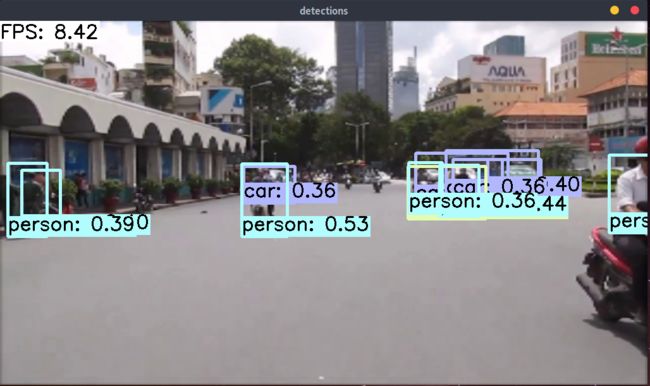
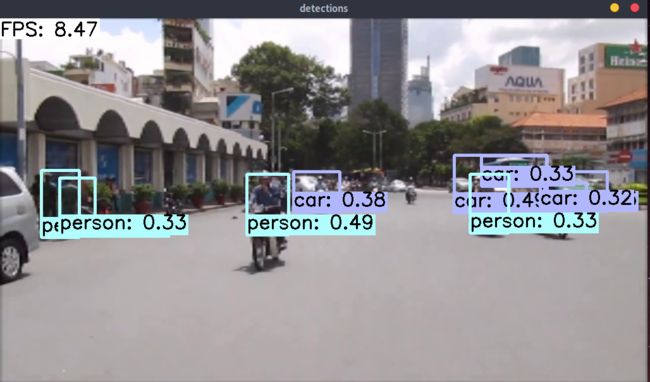
通过上面的检测结果可以看出测试的准确性还可以,但是也存在漏检的情况,而且速度也只有FPS=8左右。
(3)摄像头上测试:
python examples/ssd/ssd_pascal_webcam.py
因此通过SSD的方法可以用来训练和检测交通标志,文本检测或人脸检测等等,也可以用此方法来讲带有标记信息的视频目标检测数据集进行转换,生成所需要的lmdb格式的数据文件。