从词袋到Transfomer,NLP十年突破史

作者 | Zelros AI
译者 | 夕颜
出品 | AI科技大本营(ID:rgznai100)
【导读】通过 Kaggle 竞赛视角,观察 NLP 十年发展简史。
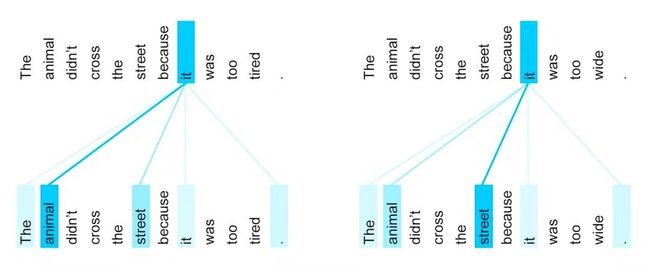 根据上下文(这里指句子的最后一个词),“它”可以指“动物”或“街道”。
图源 | Google Transfomer 介绍。
根据上下文(这里指句子的最后一个词),“它”可以指“动物”或“街道”。
图源 | Google Transfomer 介绍。
自 2010 年创立以来,著名的数据科学竞赛平台 Kaggle 一直是机器学习趋势演变的绝佳观察场。这里见证了机器学习史上的历代突破,吸引了成千上万从业者在这里交流讨论。
这个在线平台发布了各种类型的竞赛挑战(计算机视觉、语音等),其中自然语言处理(NLP)如今引起了特别的关注。确实,近几个月以来,该领域正在见证数项令人兴奋的创新。最新的一个技术是 Transfomer 和预训练语言模型的问世。
今天,从 Kaggle 平台的视角,我们来简单回顾一下 NLP 的发展历史。
2016年之前:词袋和TF-IDF“一统天下”
在 2016 年左右往前,解决(并赢得胜利!)Kaggle NLP 挑战的标准方法是使用词袋(基本上就是计算一个单词在文档中出现的次数)来创建功能,以供机器学习分类器使用,例如典型的Naive Bayes。TF-IDF 略有改进。
例如,在 StumbleUpon Evergreen 分类挑战赛中使用了这种方法(顺便说一句,由 FrançoisChollet 于 2013年获胜,就是那个两年之后创建 Keras 的人)。
2016–2019年:
词嵌入+ Keras和Tensorflow的兴起
2015年,出现了用于密集单词表示的库,例如 Gensim(包括 Word2vec 和 GloVe)。随后出现了其他预训练的嵌入,例如 Facebook FastText 和 Paragram。
同时,被广泛采用、简单易用的神经网络框架的 Keras 和 Tensorflow 的第一个版本流行起来。有了它们,就可以开始按单词顺序捕获含义,而不再仅按词袋捕获。
为了运行深度神经网络,要解决的最后一个大障碍是:获得很高的处理能力。这个可以通过使用低成本 GPU 解决。2017 年 3 月 Kaggle 被 Google 收购后更加开放,Kaggle 在其平台上(通过协作 Notebooks 内核)免费开放。
从那时起,万事俱备,单词嵌入和神经网络(RNN、LSTM、GRU 等…以及诸如注意力等改进)成为解决 Kaggle 上 NLP 任务的标准方法。这么长的TF-IDF…
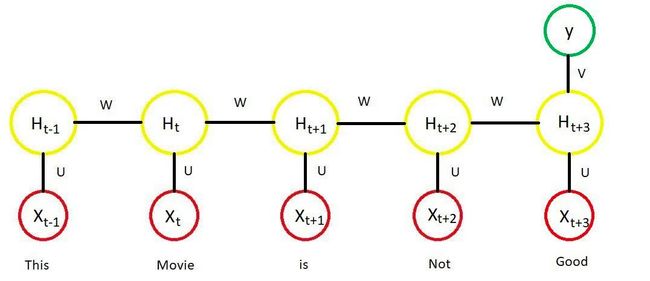 用递归神经网络编码单词序列
用递归神经网络编码单词序列
2018–2019年:PyTorch的突破
近几个月以来,一种新的神经网络框架在数据科学界越来越受关注:PyTorch。
我们不讨论 Tensorflow 和 PyTorch 哪个更优,但是可以确定的是,在 Kaggle上,PyTorch 参赛者社区蓬勃发展起来。平台上会定期发布 PyTorch notebook 和教程。
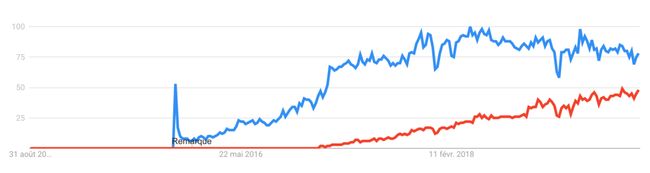 Tensorflow(蓝色)与PyTorch(红色)搜索趋势(来源 | Google Trend)
Tensorflow(蓝色)与PyTorch(红色)搜索趋势(来源 | Google Trend)
2019:
Transfomer和预训练语言模型诞生
如前几节所述,到目前为止,解决 NLP 任务的标准方法是使用单词嵌入(在大量未标记的数据上进行预训练),使用它们来初始化神经网络的第一层,并在其上训练其他层特定任务的数据(可能是文本分类、问题解答、自然语言推断等)。
仔细想一下,问题是这种方法不是最佳的。确实,对于新任务,这种方法都必须几乎从零开始重新学习所有的东西。用词嵌入初始化的模型始终需要从头开始学习如何从词序列中得出含义,尽管这是语言理解的核心。
2018年,NLP 的关键范式转变——Transfomer 诞生了:从仅初始化模型的第一层到使用分层表示对整个模型进行预训练。这开辟了全新的工作方式:将信息从预先训练的语言模型转移到下游任务(也称为迁移学习)。
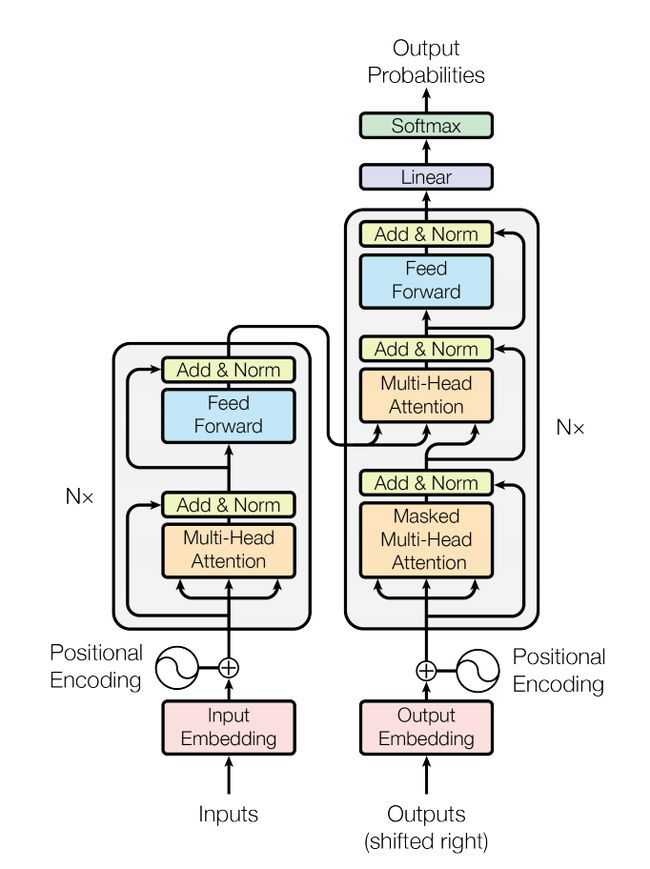 Transfomer 模型架构,摘自论文 Attention is All You Need
Transfomer 模型架构,摘自论文 Attention is All You Need
在实践中,如今,利用预训练语言模型的最佳方法是使用 Hugging Face(由现在居住在美国的法国企业家和 Station F Microsoft AI Factory 的校友创建)的 Transfomer 库。现在它与PyTorch 和 TensorFlow 兼容。如果你想完成诸如文本分类之类的简单任务,可以试试 simple-transformers。
另外,如果你专注非英语文本,那么另一个值得关注的库是 fast.ai,该库旨在结合针对不同语言的预训练模型,由 Kaggle 前总裁兼首席科学家 Jeremy Howard 创建。
下一步是什么?
每个人现在都可以使用最新一代预训练语言模型的现成库。这使得我们可以快速实验,用上最先进的 NLP 技术。
关注未来Kaggle NLP 比赛中会如何使用这些技术将很有趣,比如最近的 TensorFlow 2.0 问题解答挑战一样,这个挑战可以识别有关 Wikipedia 页面内容的真实用户问题的答案。敬请关注!
参考链接:
https://medium.com/@Zelros/from-bag-of-words-to-transformers-10-years-of-practical-natural-language-processing-8ccc238f679a
(*本文为AI科技大本营编译文章,转载请微信联系 1092722531)
◆
精彩推荐
◆
2019 中国大数据技术大会(BDTC)再度来袭!豪华主席阵容及百位技术专家齐聚,15 场精选专题技术和行业论坛,超强干货+技术剖析+行业实践立体解读,深入解析热门技术在行业中的实践落地。
6.6 折票限时特惠(立减1400元),学生票仅 599 元!
