本博客在http://doc001.com/同步更新。
本文主要内容翻译自MySQL开发者Ulf Wendel在PHP Submmit 2013上所做的报告「Scaling database to million of nodes」。翻译过程中没有全盘照搬原PPT,按照自己的理解进行了部分改写。水平有限,如有错误和疏漏,欢迎指正。
本文是系列的第三篇,本系列所有文章如下:
- 百万节点数据库扩展之道(1): 传统关系型数据库
- 百万节点数据库扩展之道(2): NoSQL理论与Amazon Dynamo
- 百万节点数据库扩展之道(3): Google Bigtable
- 百万节点数据库扩展之道(4): Google Spanner
- 百万节点数据库扩展之道(5): NoSQL再讨论
Google Bigtable
GFS:概述
GFS(Google file sysem)是构建Bigtable的基石,运行在通用硬件和Linux之上。对比于关系型数据库,通用硬件和Linux等同于磁盘,提供原始存储资源;GFS等同于文件系统,提供文件存取功能;Bigtable当然就等同于传统数据库本身。
GFS被设计用于存储大文件。每一个大文件被切割成很多的块(chunk),存储在被称之为chunkserver的服务器上。默认情况下,每个chunk有3个副本。3副本是很多可靠存储系统的标配,一般都是2个副本位于同一机架,1个副本位于其它机架。
GFS有一个master节点,管理chunk的元数据信息,供用户查询文件的位置。因为元数据信息尺寸相当的小,master将它们都存储在内存中。master通过心跳包监测chunkserver的活跃状态,以及了解chunk分布情况。
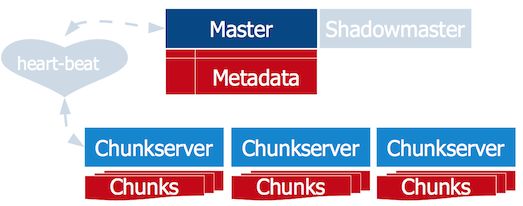
GFS:读操作
一个GFS读操作分为几个步骤:
- 客户端向master询问欲读取的数据的位置信息(在哪个chunkserver)。
- master返回一个租约(lease),和数据的位置信息。客户端缓存该信息,缓存信息可减少master的查询压力。
- 客户端联系相应的chunkserver,提供租约。
- 如果租约有效,chunkserver发送被请求的文件给客户端。
GFS的客户端读到的数据可能是一致的,也可能是不一致的。这点在后面会进一步描述。
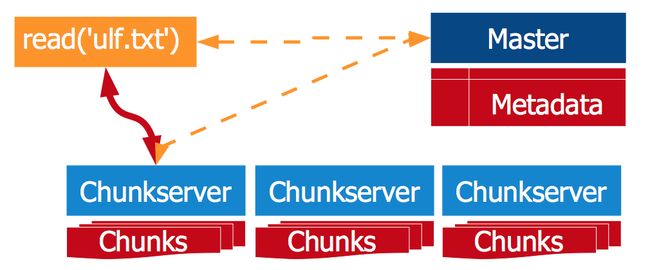
GFS:写操作
GFS执行写操作前,先由master决定所写chunk的主副本(primary)。主副本确保所有副本都以相同的顺序接收更新操作。与Dynamo相比,主副本的存在使得GFS的数据备份非常简单。
GFS采用了一个弱一致性模型,并发的写操作之间并不相互隔离。没有分布式锁管理器来阻止客户端并发写同一个文件。GFS牺牲了一致性,以换取更高的并发性能。
GFS:追加操作
GFS提供一个类似于O_APPEND的追加操作,追加到chunk的具体位置由GFS决定。GFS保证数据至少会被原子的写一次。客户端在写过程中遭遇失败时会重试,因而可能导致重复记录或空白记录。客户端需要处理这些重复记录和空白记录,不过GFS已经提供了一些常见的处理策略。
追加操作不需要全局锁。但是,数据在不同副本的偏移位置可能不一样(重复记录、空白记录导致的)。
Chubby:概述
Chubby是Bigtable依赖的一个分布式锁服务,为客户端提供粗粒度的、建议性质的共享/排它锁。粗粒度的含义是每个锁至少持有数分钟。建议性质意味着,锁并不阻止对真实资源的访问,恶意的客户端完全可以忽略锁的存在,直接访问资源。
出于可扩展性考虑,Google部署了很多Chubby单元(cell)。每个数据中心有一个或多个单元。每个单元一般有5个Chubby副本。副本很少失效,即使失效也可以在数秒钟之内恢复。Chubby缓存文件、元数据、句柄、锁,一致的缓存使得一个Chubby单元能够及时处理数万客户端的并发请求。
Chubby:中心锁服务
中心锁服务是一个简洁的共享资源并发解决方案。对开发者来说,使用这种的锁和使用本地的互斥锁非常相似,两者的最大区别在于前者是基于RPC的。
Chubby:不为事务设计
分布式锁服务并不意味着可以轻易地实现事务逻辑。Chubby不光没有实现细粒度锁,而且需要客户端处理很多事情。
原PPT中举的例子没有看得很明白,原文如下:
For example, the application must acquire locks following two-phase locking. Two phase locking says that you have to acquire all locks and then, afterwards, release them. Once you have released a lock you must not acquire a new lock. Here's why, ask yourself what state the other process will observe and base his decisions on:
Acquire('src');
Release('src'); /* other process scheduled to run now */;
Acquire('dest');
Release('dest');
似乎是想说,因为需要和远程Chubby服务器交互,Release('src')不能原子地完成,所以,释放锁的过程中,其它进程看到的状态可能是模棱两可的。但是这个会导致问题吗?Chubby已经保证了所有的Acquire要么失败,要么成功,不存在中间状态,那么其它进程判断锁的状态的时候,也应该以Chubby为准,那就不存在模棱两可的问题。是这样吗?求指教!
Chubby:命名服务(naming service)
Chubby可以用于存储应用的元信息(例如,配置)。
举一个例子,一个分布式的应用需要找到它的master的IP地址,这个信息存储在Chubby中。如果Chubby是全球部署的,它存储在/ls/global/myapp/;如果Chubby是本地部署的,它存储在/ls/local/myapp/。首先,分布式应用程序通过DNS找到全球Chubby或本地Chubby,然后向Chubby请求相应路径的信息。
Chubby:一致问题
Chubby提供中心式的锁服务,但是Chubby本身不能导致单节点故障,因此Chubby必然包含多个节点。
Fischer-Lynch-Patersion(FLP)不可能结论证明了,在一个异步系统中,哪怕只有一个进程不可靠,让一组进程对一个值达成一致都是不可能的。怎样判断一个系统是异步的呢?如果消息传输的时间不存在上限,且处理器的速度也不确定,那么,这个系统是一个异步系统。在这样的系统中,无法区分两种情况:机器崩溃了,或机器太慢。崩溃的机器需要运行恢复协议,而太慢的机器只能等待。幸运的是,就像CAP,该问题也有相关理论和实践。其中一个解决方案就是Paxos协议家族。
Paxos:概述
Paxos的特点概括如下:
- 安全
- 合法性(non-triviality):只有提议的值会被学习到
- 一致同意性:两个节点不能通过不同的值
- 可终止性:正常运行的节点最终通过一个值
- 容错
- 如果少于一半的节点失败,剩余的节点最终能够达成共识
Paxos:分布式状态机
一个常用的副本方法是使用副本状态机(replicated state machine)。一个状态机有一个明确的起始点。接收到的每一个输入经过迁移(transition)和输出函数,产生一个新的输出状态。如果以相同的顺序接收相同的输出,同一状态机能够确保多个副本产生的输出一致。
对于分布式的系统来说,每一个节点都是一个状态机,所有节点组成一个分布式状态机集合。现在的主要问题在于,由于分布式环境固有的不确定性,输入在传输过程中可能会丢失、出错、乱序,怎样才能保证所有的输入无差错、顺序正确地被处理,是一个难题。
Paxos:提议号(sequence number)
在一个异步系统中,消息到达的顺序可能发生变化,两个消息不保证以发送顺序送达。这个特点和副本状态机不兼容,因为副本状态机要求所有的状态机以相同顺序处理消息或输入,以确保所有的状态机产生相同的状态。
为了解决这个问题,Paxos的每一个提议都包含一个提议号,所有的消息接收者按照提议号确定消息顺序。
Paxos:朴素算法
我们首先尝试提出一个简单的算法,称之为「朴素算法」,该算法与二阶段提交协议2PC类似。
算法首进入提议阶段。一个节点(即proposer)提议一个值,并将提议发送给另外一些节点(即acceptor)。acceptor可以接受或拒绝提议。它们决定后,将结果返回给proposer。如果proposer收到的所有结果都是「接受提议」,那么提议被接受,进入提交阶段,proposer发起提交过程,所有acceptor接到propser指令后更新提议值。只要有一个acceptor拒绝了提议,提议就不会被提交。
然而,在这个过程中,如果一个acceptor未能成功返回结果,该怎么处理?根据FLP,我们无法把整个过程进行下去,因为无法确定acceptor到底是崩溃了,还是处理速度太慢。前者需要重启协议过程,后者只需要等待。整个协议就这样僵持住了。
参考前面的Dynamo实现,我们很容易想到的一个变通方案就是,确定一个最小的acceptor集合,只要该集合的acceptor都接受了提议,整个提议就可以被提交。
Paxos:多数法定人数算法
根据前面的讨论,我们进一步提出「多数法定人数算法」。
这次的算法要求一个决议的通过需要获得至少(n/2+1)个accptor的选票(即接受提议),其中,n是accptor的总数。这种方法的基础是,任何两个提议至少会有一个公共的acceptor,该acceptor知晓所有历史提议的结果,从而可以确保被接受的提议是不矛盾、合法的。
但是,这种算法还不能处理多个提议并发的情况。
想象一个双提议并发的场景。
第一个proposer提议将值设为'a',收到该提议的acceptor数量刚好达到法定人数,这些accptor决定返回accept('a')。但是很不幸,其中一个acceptor恰好失效,未来得及发出accept('a')。该提议于是成为一个悬案,proposer无法做出决定,只能继续等待。
同时,第二个proposer提议将值设为'b',且该提议者的提议号比第一个proposer的提议更大,因此,acceptor们会欣然接受该提议。超过法定人数的acceptor确认了该提议,因此,其proposer认为提议值通过。
就在这时候,第一个提议的失效acceptor恢复,它的悬而未决的accept('a')也发出了。终于,第一个proposer的决议也通过了。
显然,现在出现了两个矛盾的的决议。
出现这个问题的关键在于,acceptor在一个提议未达成结论之前,贸然接受了另外一个矛盾的提议。
Paxos:合法提议算法
Paxos对上述的算法进行改进,确保只会出现唯一的正确值。它利用了这个现象,即任何两个提议的法定人数集合至少有一个共同节点。这个/些共同节点可以暗示后一个提议的proposer,告知它已经存在一个决议中的建议值了,在决议达成之前,不应该再提出新的提议。
换一种描述就是:在上一个提议达成一致之前,针对同一个对象/数据的其它的提议会被拒绝。
Paxos:协议描述
经过前面的讨论,我们终于可以得到了Paxos算法。算法中,一个完整的Paxos提议分为3个阶段:
- 建议阶段
- 一个节点决定发起提议,成为proposer/leader
- proposer生成一个比以往提议号更大的提议号N,提议号将被发送给acceptor
- 一个acceptor可能接受的提议号必须比之前看到的都大。如果条件满足,acceptor设置本地看到的最大提议号high=N,回复(OK,上一次接受的提议号,上一次接受的值);否则acceptor拒绝提议
- 接受阶段
- proposer检查同意提议的acceptor数量是否达到法定人数,达到才能继续。否则,提议要么终止(提议号不大于已知提议号),要么等待(收到的回复数量不足)
- 从acceptor们的回复中,proposer找到「上一次接受的提议号」最大的回复,其值为V。如果V=NULL,即该acceptor从未接受过值,那么proposer可以选择一个值,否则,它只能提议相同的值V。设选定的提议值为V'
- proposer发送(提议号N,提议值V')
- 如果high>N,acceptor拒绝V'(在这期间可能有其它提议,所以必须再做一次检查),否则接受V',设high=N,上一次接受的提议值v=V',上一次接受的提议号n=N
- 决定阶段
- 如果提议无法被多数proposer接受,本次提议延迟,重启
- 否则,proposer认为提议结束,提议值成功设定
Paxos被认为是解决分布式系统一致性问题唯一的正确算法。但是Paxos实现难度很大,且出现竞争的情况下,算法效率低下,收敛速度非常慢。目前,已经有很多Paxos的简化实现(Chubby、ZooKeeper等),它们或多或少存在一定的缺陷,但是在实践中运行得相当好。
Bigtable:概述
终于到正题了。
Bigtable是Google公开的第一个面向结构化数据的分布式存储系统。它是一个海量规模的键值(key-value)存储系统,被应用于网页索引、Google Analytics、Google Earth等产品。它的数据模型是一个稀疏、分布式、持久化的多维排序映射表(map)。每个记录的索引是一个行健(row key)、一个列(column)、一个时间戳(timestamp),值是一个二进制字符串,即:
(row:string,column:string,timestamp:int64)-->string
行健:按照字典顺序排序,key是任意的字符串,最大64KB,一般10~100B。对每一个row key数据的读写是串行的,即row是保证事务一致性的单位。连贯key的row被组织成表,是负载均衡和数据分发的基本单位。
列:列被组织「列家族(column family)」集合,是基本的访问控制单元。存储在一个列家族的数据通常是同一类型的。一个表中列家族的数量应该尽可能地少,而且操作中,列家族很少发生变化。列家族的语法是family:qualifier,名字必须是可打印的,qualifer可以是任何字符串。
时间戳:一个行健和一个列组成一个单元(cell),cell可以包含同一数据的多个版本,每一个版本由一个64位整数表示的时间戳区分。不同的版本按照时间戳降序排列。为了进行垃圾回收,客户端可以指定至少保存n个版本的数据,或者只包含足够新的数据。
行健也是字符串,最大可达64KB大小,一般也就10~100B。映射表按照行健字典排序。
结构化数据(structured data):具有确定数据模型,可以存储在关系型数据库。例如关系型数据库中的表。
半结构化数据(semi-structured data):具有一定的结构性,但是结构灵活性较大。例如XML数据。
非结构化数据(unstructured data):没有结构,无法直接获知内容。例如视频、图片。
Bigtable:数据分布
Bigtable动态地将表按照行健范围分割成更小的子表(tablet),tablet是数据分布和负载均衡的最小单位。每一个table的大小在100~200MB,存储在tablet server。通过仔细地选择行健,客户端可能使查询更加区域化、分散化。Bigtable的查询依赖行健范围扫描实现,区域化能够在查询时能够降低行健扫描的范围,从而减少通信机器的数量,提高查询效率。
用户可以将多个列家族组织成一个局部组(locality group)。locality group内的数据在物理层面上会被存储到一起。这类似于垂直分区。
举一个例子,一个客户端需要频繁地访问「anchor:」列家族,且很少同时访问另外一个列家族「contents:」。用户可以将「anchor:」列家族存储到一个locality group。这样,查询的时候,只会读取「anchor:」数据,而「contents:」不会被读取。读取的数据量减少了,查询的速度快了。

Bigtable:物理存储
一个tablet被存储为多个SSTable。一个SSTable是一个GFS文件,存储的是不可变的、排序的key-value键值对。数据可以原地删除,但是不可以原地更新。新的记录会写到新的文件。
旧文件会被按需回收。GFS的副本机制为Bigtable提供了强一致性保证。
客户端可以要求SSTable惰性加载到内存中,以提高性能。SSTable的块大小是可配置的。
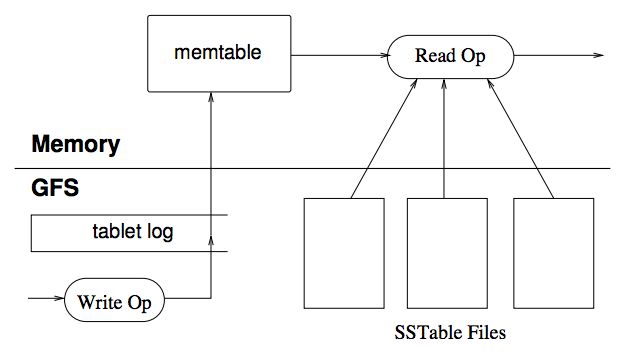
在Bigtable中,更新被首先提交到commit log文件中,作为redo记录。最近的更新被存储到内存memtable,较老的更新被存储到硬盘SSTable。
随着操作的进行,memtable的大小开始增长。当memtable的大小到达一个阈值,memtable冻结,新的memtable创建,冻结的memtable转化为SSTable,保存到GFS中。这个过程称之为次合并(minor compaction)。
次合并的目的有两个:减少内存占用,以及加速服务器恢复。每一次次合并都会创建一个新的SSTable。这些表周期性的在后台执行归并合并,将数个SSTable和memtable的内容进行合并,合并完后,原有的SSTable和memtable被丢弃。
所有SSTable合并成一个SSTable的过程称之为主合并(major compaction)。次合并产生的SSTable会包含一些删除信息。主合并会将这些删除信息去除。
Bigtable:压缩
Bigtable使用一个反范式的存储模式,许多客户端使用两阶段压缩策略压缩数据。给定一个文本格式的数据副本,我们可以使用gzip或其它压缩算法对数据进行压缩,但是这样的压缩率只能达到1:3,而两阶段压缩算法可以达到1:10。
Bigtable的压缩策略首先对大块数据进行压缩,其假设是认为大块数据的重复更常见。通常,这样的大块数据包含同一数据的多个版本,例如同一个HTML文件的多个版本,每个版本只有细微区别。接着,Bigtable进行第二轮压缩,将相似的小块数据进行压缩,每一个小块是16KB。
2006年的性能数据表明,Bigtable压缩的吞吐量在100200MB/s,解压缩的吞吐量在4001000MB/s。
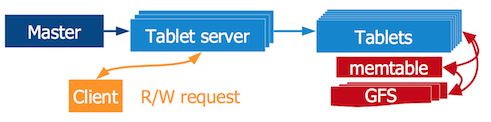
Bigtable:系统视角
每一个Bigtable集群包括一个master、许多tablet server、一个GFS集群和Chubby。客户端可以缓存tablet的位置信息,以直接访问tablet server读写数据,降低master的负载。
master只负责管理任务:
- 监视、管理tablet server
- 分配tablet给tablet server(负载均衡,故障迁移)
- GFS文件垃圾回收
- 协调模式变换,如创建新表、增加或移除列家族
Bigtable:tablet索引
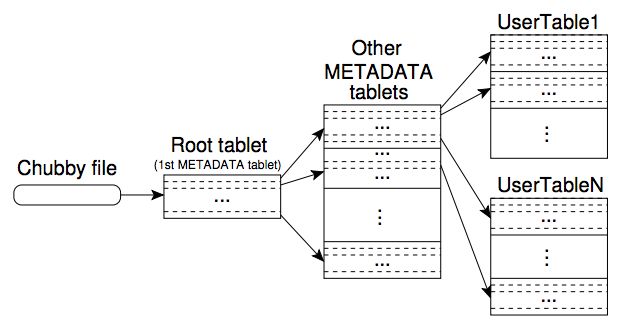
tablet的位置信息存储在一个称之为METADATA表的特殊Bigtable系统表中。METADATA表包含每一个用户表的位置信息,通过二元组(table_id,end_row)索引。客户端查询METADATA表获取tablet和tablet server信息,并可以缓存这些信息。为了找到METADATA的root tablet(即第一个tablet)的位置,客户端需要询问Chubby。
这实际上是一个递归设计,表信息本身也存储在表中。
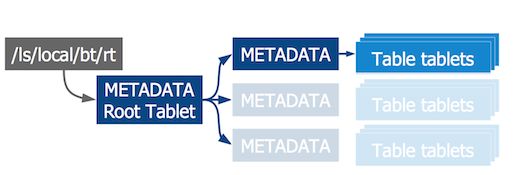
概括地讲,整个结构类似于一个B+树。
- 第一层:root tablet文件,位置信息存储在Chubby文件中。root tablet维护METADATA表tablet的索引。实际上root tablet是METADATA的一部分,是其第一个tablet。root tablet始终作为一个整体,不会被细分,这保证了B+数不超过3级。
- 第二层:每一个METADATA tablet存储用户数据tablet位置信息,存储的信息包括tablet的行健范围、tablet所在的tablet server。每一个METADATA行消耗近1KB内存。假设每一张METADATA的大小限制为128MB(这是一个适中的大小),整个三级索引可以索引$234$个tablet(即$(128*1024)2$)。
- 第三层:用户数据tablet。
Bigtable:tablet分配
每一个tablet一个时刻只能分配给一个tablet server。msater维护活跃tablet server的信息,以及每一个tablet的分配信息。当一个tablet没有分配给任何一个tablet server时,master将为其选择一个tablet server。
tablet server的信息是通过Chubby来维护的。当一个tablet server上线时,在一个特殊的Cubby文件夹下建立一个唯一的文件,并持有该文件的排它锁。master监视这个特殊文件夹,以发现tablet server。如果一个tablet server因为网络等原因失去排它锁,将不再提供服务。
master需要探测tablet server的状态,在tablet server失效时要尽快对其上的tablet进行重新分配。为此,master周期性地询问每个tablet server,了解它们持有的排它锁的状态。
如果一个tablet server报告,它已经丢失了锁;或者,在最近的几个周期,master都无法与tablet server取得联系,master就会自己去尝试获取该tablet server的排它锁。如果master无法获得排它锁,说明Chubby不可用,或者master自己出现了问题,无论怎样,整个系统都无法正常工作了。如果master可以获得这个锁,那么,Chubby是可用的,表明tablet server要么已经死亡,要么无法与Chubby通信。主服务器因此从Chubby中删除这个tablet server的文件,从而确保这个tablet server不再能够提供服务。一旦一个服务器文件被删除,master就可以把tablet server上所有的tablet标记为未分配状态,然后将它们分配给其它tablet server。GFS可以保证tablet server下线不会导致tablet数据文件丢失。
为了保证一个BigTable集群不会轻易受到master和Chubby之间的网络故障的影响,master也需要维持与Chubby的会话状态。一旦master的Chubby会话过期了,这个master就会自杀。
当一个master启动时,它需要恢复所有的tablet分配关系,然后才能处理tablet的相关操作。恢复过程包括以下步骤:
- 从Chubby获得master锁;
- 扫描Chubby的服务器文件夹,发现所有活跃的tablet server;
- 向活跃的tablet server询问tablet的分配信息,并更新它们的当前master信息;
- master扫描METADATA表,了解tablet的集合,从而找到所有未分配的tablet。
已有的tablet在几种情况下会发生变化:表创建/删除/合并/分裂。除了分裂操作外,所有的操作均由master发起,只有分裂操作由tablet server发起。tablet server通过在METADATA表里提交记录信息来分裂表;提交完信息后,通知master。如果此间发生信息丢失,当master请求tablet server加载tablet时能够发现新表。
Bigtable与CAP
Bigtable成功证明了,即使在CAP约束下,同样可以创建大规模、高扩展的分布式系统。实际上,Bigtable考虑了很多故障因素,不局限于网络分区:
- 内存和网络故障
- 时钟不同步
- 服务器宕机
- 软件故障、管理节点不可用
- 网络分区
Bigtable是强一致的,使用GFS,行操作是原子的。其可用性取决于Chubby,而Chubby的可用性经测量在99.99%(最低)到99.995%(平均)之间。Chubby会话帮助系统快速检测到网络分区,Paxos可以用于主选举。状态存储在Chubby和GFS中,这使得系统组件的重启非常迅速。整体上,Bigtable更倾向于CP。
Bigtable相关开源系统
-
HBase
HBase是Bigtable的开源实现,构建在Hadoop之上。其中,Hadoop提供MapReduce和HDFS分布式文件系统;ZooKeeper类似Chubby,提供分布式配置管理、一致性、订阅消息系统;Chukwa提供实时监控;Hive和Pig提供集群搜索的额外支持,其中Hive的查询语言HiveQL实现了SQL92的一个子集。
-
Facebook Presto
Facebook最近宣布了一个面向ad-hoc数据分析的SQL引擎Presto,该引擎可以工作在HBase之上。Presto号称CPU效率和性能要高于Hive。Hive最初也是Facebook开发的。
Hive使用MapReduce作业。MapReduce批作业顺序地执行,将中间结果保存到硬盘上。而在Presto中,必要时会创建Java JVM字节码,通过wroker以流水线的方式处理作业,中间结果尽可能地存储在内存中。
-
Cloudera Impala
Impala是根据Google Dremel论文实现的分布式查询引擎,工作于HDFS和HBase之上。
总结
Bigtable及其类似系统的数据模型有以下特点:
- 键值存储,(string, column, timestamp) > (binary)
- 存储自解释的二进制大文件(basic large object,BLOB)
- 基本的扫描操作、键值查询、MapReduce
- 切片、垂直分区
- 通过行健、locality group的选取可以影响数据存储物理位置
Bigtable及其类似系统适用于大数据处理,不适用于事务。
未完待续...
下一部分将介绍另外一种重要的Google Spanner,参见:
- 百万节点数据库扩展之道(4): Google Spanner