第一步:获取演奏区当天所有口琴投稿信息
- 连接上mysql数据库之后使用下列sql语句来获取当天的b站口琴投稿信息。(我们使用的是霜落XXS开发并维护的爬虫数据库)
SELECT s.aid,s.title,s.pubdate,up.name,s.mid,s.duration,d.view, s.videos,d.danmaku,d.favorite,d.coin,d.SHARE,d.reply,d.like,d.dislike FROM
(SELECT aid, VIEW,danmaku,reply,favorite,coin,SHARE,`like`,dislike FROM video_dynamic_180924 ) AS d,
(SELECT aid,MID,pubdate,tid,title,duration,videos FROM video_static WHERE ((tid=59) AND (title LIKE '%口琴%') AND(pubdate BETWEEN '2018-08-08' AND '2018-08-15')) )AS s,
(SELECT MID, NAME FROM up_data) AS up
WHERE d.aid=s.aid AND s.mid = up.mid
ORDER BY DATE(pubdate) ASC LIMIT 10000000;
-
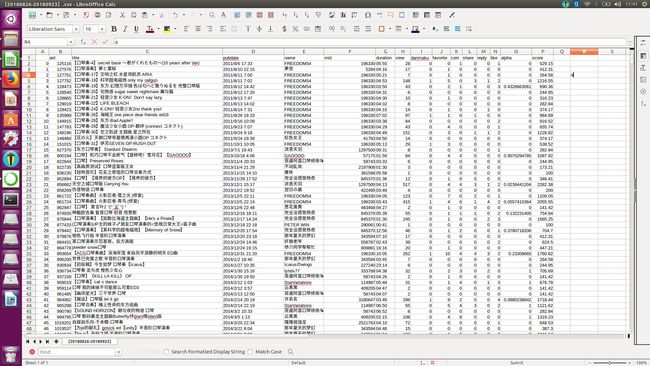
将获取到的数据储存为CSV格式,如下图:

第二步:计算得分
- 对于历史投稿,首先计算该月数据与上月数据的差值,然后计算分数。
- 对于新增投稿,直接计算分数。
import time
import sys
import importlib
import math
import pandas as pd
import numpy as np
import threading
import queue
aid1 = []
title1 = []
name1 = []
view1 = []
score1 = []
mid1 = []
duration1 = []
videos1 = []
danmaku1 = []
favorite1 = []
coin1 = []
share1 = []
reply1 = []
like1 = []
alpha1 = []
pubdate1 = []
df=pd.read_csv('test1.csv', encoding="GBK")
df1 = pd.read_csv('20180923.csv', encoding="GBK")
df2 = pd.read_csv('20180826.csv', encoding="GBK")
df3=pd.merge(df1,df2,on='aid',how='left')
df3.to_csv('20180826-20180923.csv', encoding="GBK")
class myThread (threading.Thread):
def __init__(self, thread_id, q):
threading.Thread.__init__(self)
self.thread_id = thread_id
self.q = q
def run(self):
while True:
try:
t = self.q.get(block=True, timeout=0)
except queue.Empty:
break
try:
if not math.isnan(df3.MID_y[t]) :
aid=df3.aid[t]
title=df3.title_x[t]
pubdate=df3.pubdate_x[t]
name=df3.NAME_x[t]
mid=df3.MID_x[t]
duration=time.strftime("%M:%S", time.localtime(df3.duration_x[t]))
videos=df3.videos_x[t]
view=df3.VIEW_x[t]-df3.VIEW_y[t]
danmaku=df3.danmaku_x[t]-df3.danmaku_y[t]
favorite=df3.favorite_x[t]-df3.favorite_y[t]
coin=df3.coin_x[t]-df3.coin_y[t]
share=df3.SHARE_x[t]-df3.SHARE_y[t]
reply=df3.reply_x[t]-df3.reply_y[t]
like=df3.like_x[t]-df3.like_y[t]
if ((view>0)and(danmaku>=0)and(favorite>=0)and(coin>=0)and(share>=0)and(reply>=0)and(like>=0)):
view_fixed=math.sqrt(10000*view)*(4/(videos+3))
k=(coin*favorite*400)/(view**2)
alpha=k if k<1 else 1
favorite_alpha=round(alpha*30, 2)
coin_alpha=round(alpha*20, 2)
share_alpha=round(alpha*50, 2)
reply_alpha=round(alpha*10, 2)
score=round(view_fixed+(share*50+favorite*30+coin*20+reply*10)*alpha, 2)
aid1.append(aid)
title1.append(title)
name1.append(name)
pubdate1.append(pubdate)
view1.append(view)
score1.append(score)
mid1.append(mid)
duration1.append(duration)
videos1.append(videos)
danmaku1.append(danmaku)
favorite1.append(favorite)
coin1.append(coin)
share1.append(share)
reply1.append(reply)
like1.append(like)
alpha1.append(alpha)
else:
aid=df3.aid[t]
title=df3.title_x[t]
pubdate=df3.pubdate_x[t]
name=df3.NAME_x[t]
mid=df3.MID_x[t]
duration=time.strftime("%M:%S", time.localtime(df3.duration_x[t]))
videos=df3.videos_x[t]
view=df3.VIEW_x[t]
danmaku=df3.danmaku_x[t]
favorite=df3.favorite_x[t]
coin=df3.coin_x[t]
share=df3.SHARE_x[t]
reply=df3.reply_x[t]
like=df3.like_x[t]
view_fixed=math.sqrt(10000*view)*(4/(videos+3))
k=(coin*favorite*400)/(view**2)
alpha=k if k<1 else 1
favorite_alpha=round(alpha*30, 2)
coin_alpha=round(alpha*20, 2)
share_alpha=round(alpha*50, 2)
reply_alpha=round(alpha*10, 2)
score=round(view_fixed+(share*50+favorite*30+coin*20+reply*10)*alpha, 2)
aid1.append(aid)
title1.append(title)
name1.append(name)
pubdate1.append(pubdate)
view1.append(view)
score1.append(score)
mid1.append(mid)
duration1.append(duration)
videos1.append(videos)
danmaku1.append(danmaku)
favorite1.append(favorite)
coin1.append(coin)
share1.append(share)
reply1.append(reply)
like1.append(like)
alpha1.append(alpha)
print(t)
except:
pass
q = queue.Queue()
#把JOBS排入队列
for i in range(0,df3.shape[0]-1):
q.put(i)
n = 16
thread_list = [myThread(i, q) for i in range(n)]
#fork NUM个线程等待队列
for i in range(n):
thread_list[i].start()
#等待所有JOBS完成
for i in range(n):
thread_list[i].join()
columns = {'aid': aid1, 'title': title1, 'pubdate':pubdate1,'name': name1,'mid':mid1,'duration':duration1,'view': view1,'danmaku':danmaku1,'favorite':favorite1,'coin':coin1,'share':share1,'reply':reply1,'like':like1,'alpha':alpha1,'score':score1 }
df = pd.DataFrame(columns)
df = df[['aid','title','pubdate','name','mid','duration','view','danmaku','favorite','coin','share','reply','like','alpha','score']]
df.to_csv('【20180826-20180923】.csv', encoding="GBK")
-
处理后的数据如下:
第三步:制作模板图片
首先准备好空白模板

- 按照排名往里面填充对应数据
from PIL import Image,ImageFont,ImageDraw #引入相关库
import pandas as pd
df=pd.read_csv('【20180826-20180923】.csv', encoding="GBK")
i=0
##前十
while i<10:
t=i+1
k1="NEW !!" if df.pubdate[i] > '2018/8/26 00:00' else "Old !!"
k3=df.duration[i]
k4=df.score[i]
k5=df.aid[i]
k6=df.pubdate[i]
k7=df.title[i]
k8=df.name[i]
k9=df.reply[i]
k10=df.view[i]
k11=df.favorite[i]
k12=df.share[i]
k13=df.coin[i]
font1=ImageFont.truetype('1.TTF',150) #名次
font2=ImageFont.truetype('BRDWAYN.TTF',60) #NEW&Old
font3=ImageFont.truetype('1.TTF',60) #time
font4=ImageFont.truetype('1.TTF',50) #right-white
font5=ImageFont.truetype('1.TTF',40)
def mytext(self, pos, text, font, fill, border='black', bp=1):
x, y = pos
shadowcolor = border
self.text((x-bp, y), text, font=font, fill=shadowcolor)
self.text((x+bp, y), text, font=font, fill=shadowcolor)
self.text((x, y-bp), text, font=font, fill=shadowcolor)
self.text((x, y+bp), text, font=font, fill=shadowcolor)
# thicker border
self.text((x-bp, y-bp), text, font=font, fill=shadowcolor)
self.text((x+bp, y-bp), text, font=font, fill=shadowcolor)
self.text((x-bp, y+bp), text, font=font, fill=shadowcolor)
self.text((x+bp, y+bp), text, font=font, fill=shadowcolor)
# now draw the text over it
self.text((x, y), text, font=font, fill=fill)
im=Image.open('10.png')
draw=ImageDraw.Draw(im)
mytext(draw, (1580,20), '{}'.format(t), font=font1, fill='red', border='white', bp=4) # order
mytext(draw, (1610,185), '{}'.format(k1), font=font2, fill=(255,240,0), border='white', bp=0) # NEW
mytext(draw, (1610,300), '{}'.format(k3), font=font3, fill='white', border='white', bp=0) # time
mytext(draw, (1170,873), '{}'.format(k4), font=font4, fill='red', border='white', bp=2) # score
mytext(draw, (230,880), '{}'.format(k5), font=font5, fill='white', border='white', bp=0) # aid
mytext(draw, (620,880), '{}'.format(k6), font=font5, fill='white', border='white', bp=0) # date
mytext(draw, (100,965), '{}'.format(k7), font=font5, fill='black', border='black', bp=0) # title
mytext(draw, (620,1035), '{}'.format(k8), font=font5, fill='white', border='white', bp=0) # up
mytext(draw, (1750,484), '{}'.format(k9), font=font4, fill='white', border='white', bp=0) # reply
mytext(draw, (1750,638), '{}'.format(k12), font=font4, fill='white', border='white', bp=0) # share
mytext(draw, (1710,405), '{}'.format(k10), font=font4, fill='black', border='black', bp=0) # view
mytext(draw, (1710,560), '{}'.format(k11), font=font4, fill='black', border='black', bp=0) # favorite
mytext(draw, (1710,715), '{}'.format(k13), font=font4, fill='black', border='black', bp=0) # coin
im.save('target{}.png'.format(i) )
i+=1
-
得到最终图片

- 副榜同理
##副榜31-110
i=0
while i<1:
font1=ImageFont.truetype('1.TTF',150) #名次
font2=ImageFont.truetype('BRDWAYN.TTF',30) #NEW&Old
font3=ImageFont.truetype('1.TTF',60) #time
font4=ImageFont.truetype('1.TTF',50) #right-white
font5=ImageFont.truetype('1.TTF',40)
font6=ImageFont.truetype('1.TTF',30)
font7=ImageFont.truetype('1.TTF',20)
def mytext(self, pos, text, font, fill, border='black', bp=1): #字体描边函数
x, y = pos
shadowcolor = border
self.text((x-bp, y), text, font=font, fill=shadowcolor)
self.text((x+bp, y), text, font=font, fill=shadowcolor)
self.text((x, y-bp), text, font=font, fill=shadowcolor)
self.text((x, y+bp), text, font=font, fill=shadowcolor)
# thicker border
self.text((x-bp, y-bp), text, font=font, fill=shadowcolor)
self.text((x+bp, y-bp), text, font=font, fill=shadowcolor)
self.text((x-bp, y+bp), text, font=font, fill=shadowcolor)
self.text((x+bp, y+bp), text, font=font, fill=shadowcolor)
# now draw the text over it
self.text((x, y), text, font=font, fill=fill)
im=Image.open('110.png')
draw=ImageDraw.Draw(im)
j=0
while j<8:
t=30+(i)*8+j+1
k1="NEW !!" if df.pubdate[i] > '2018/8/26 00:00' else ""
k3=df.duration[30+(i)*8+j+1]
k4=df.score[30+(i)*8+j+1]
k5='av{}'.format(df.aid[30+(i)*8+j+1])
k6=df.pubdate[30+(i)*8+j+1]
k7=df.title[30+(i)*8+j+1]
k8=df.name[30+(i)*8+j+1]
k9=df.reply[30+(i)*8+j+1]
k10='播放增量:{}'.format(df.view[30+(i)*8+j+1])
k11='收藏增量:{}'.format(df.favorite[30+(i)*8+j+1])
k12=df.share[30+(i)*8+j+1]
k13='硬币增量:{}'.format(df.coin[30+(i)*8+j+1])
mytext(draw, (1770,80+120*j), '{}'.format(t), font=font3, fill='red', border='white', bp=4) # 名次
mytext(draw, (1835,90+120*j), '{}'.format(k1), font=font2, fill='green', border='white', bp=0) # NEW
# mytext(draw, (1650,185), '{}'.format(k2), font=font2, fill=(255,240,0), border='white', bp=0)
# mytext(draw, (630,130+120*j), '{}'.format(k3), font=font7, fill='black', border='black', bp=0) # time
mytext(draw, (1600,90+120*j), '{}'.format(k4), font=font5, fill='black', border='black', bp=0) #score
mytext(draw, (430,130+120*j), '{}'.format(k5), font=font7, fill='black', border='black', bp=0) #aid
mytext(draw, (750,130+120*j), '{}'.format(k6), font=font7, fill='black', border='black', bp=0) #date
mytext(draw, (420,80+120*j), '{}'.format(k7), font=font6, fill='black', border='black', bp=0) #title
mytext(draw, (540,130+120*j), '{}'.format(k8), font=font7, fill='black', border='black', bp=0) #up
# mytext(draw, (1750,484), '{}'.format(k9), font=font4, fill='white', border='white', bp=0) #评论
# mytext(draw, (1750,638), '{}'.format(k12), font=font4, fill='white', border='white', bp=0) #分享
mytext(draw, (1000,130+120*j), '{}'.format(k10), font=font7, fill='green', border='green', bp=0) #播放
mytext(draw, (1200,130+120*j), '{}'.format(k11), font=font7, fill='green', border='green', bp=0) #收藏
mytext(draw, (1400,130+120*j), '{}'.format(k13), font=font7, fill='green', border='green', bp=0) #硬币
j+=1
im.save('target{}.png'.format(30+i) )
i+=1
副榜效果图

第四步:选取视频片段
-
下载视频
image.png 选取片段(一般为高潮部分)
第五步:剪辑视频
-
用PR剪辑视频
- 渲染生成最终作品