Resampling methods are an indispensable tool in modern statistics.
In this chapter, we discuss two of the most commonly used resampling methods, cross-validationand the bootstrap.
cross-validation can be used to estimate the test error associated with a given statistical learning method in order to evaluate its performance, or to select the appropriate level of flexibility.
The process of evaluating a model’s performance is known as model assessment , whereas model the process of selecting the proper level of flexibility for a model is known as model selection .
The bootstrap is used in several contexts, most commonly to provide a measure of accuracy of a parameter estimate or of a given statistical learning method.
Cross-Validation
The Validation Set Approach
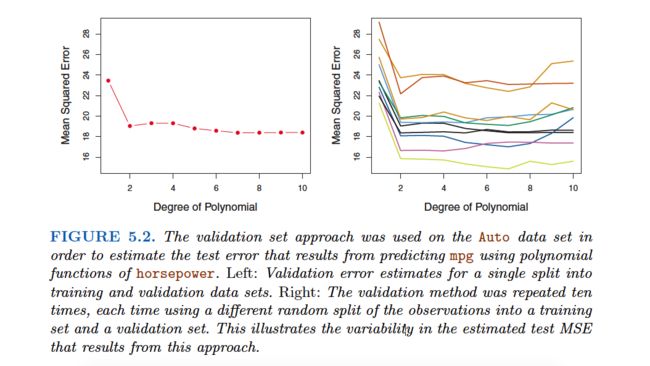
Leave-One-Out Cross-Validation
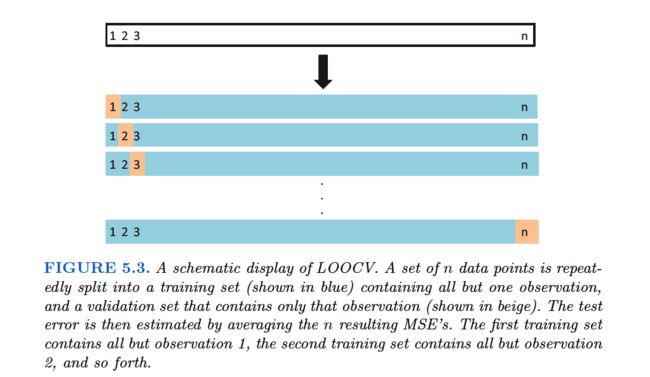
Leave-one-out cross-validation(LOOCV) is closely related to the validation set approach of Section 5.1.1, but it attempts to address that method’s drawbacks.
k-Fold Cross-Validation
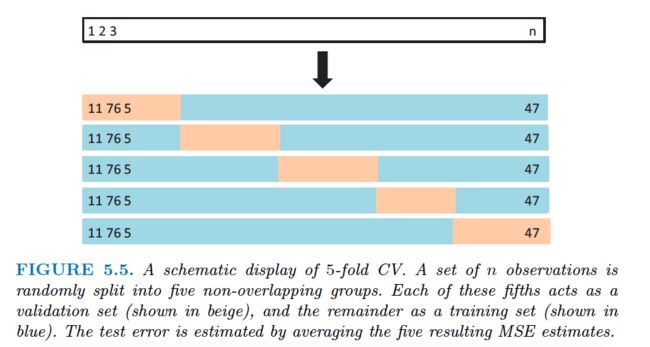
An alternative to LOOCV is k-fold CV. This approach involves randomly dividing the set of observations into k groups, or folds, of approximately equal size.
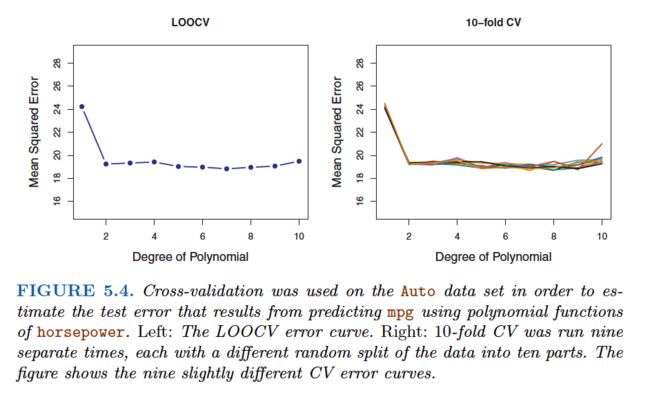
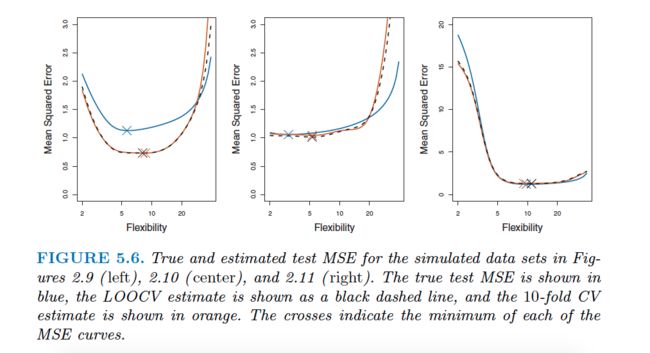
In practice, one typically performs k-fold CV using k= 5 or k= 10. What is the advantage of using k= 5 or k= 10 rather than k=n? The most obvious advantage is computational. LOOCV requires fitting the statistical learning method n times.
Bias-Variance Trade-Off fork-Fold Cross-Validation
More important advantage of k-fold CV is that it often gives more accurate estimates of the test error rate than does LOOCV. This has to do with a bias-variance trade-off.
From the perspective of bias reduction, it is clear that LOOCV is to be preferred to k-fold CV.
We must also consider the procedure’s variance. It turns out that LOOCV has higher variance than does k-fold CV with k < n. The test error estimate resulting from LOOCV tends to have higher variance than does the test error estimate resulting from k-fold CV.
To summarize, there is a bias-variance trade-off associated with the choice of k in k -fold cross-validation. Typically, given these considerations, one performs k -fold cross-validation using k= 5 or k= 10, as these values have been shown empirically to yield test error rate estimates that suffer neither from excessively high bias nor from very high variance.
Cross-Validation on Classification Problems
For instance, in the classification setting, the LOOCV error rate takes the form
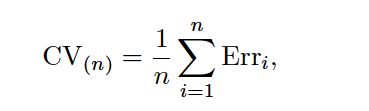
where Erri = I(yi = ˆyi). The k-fold CV error rate and validation set error rates are defined analogously.

The Bootstrap
The bootstrap is a widely applicable and extremely powerful statistical tool that can be used to quantify the uncertainty associated with a given estimator or statistical learning method.
Suppose that we wish to invest a fixed sum of money in two financial assets that yield returns of X and Y, respectively, where X and Y are random quantities. We will invest a fraction αof our money in X , and will invest the remaining 1 − αin Y. Since there is variability associated with the returns on these two assets, we wish to choose αto minimize the total risk, or variance, of our investment. In other words, we want to minimize Var(αX+(1 −α )Y). One can show that the value that minimizes the risk is given by
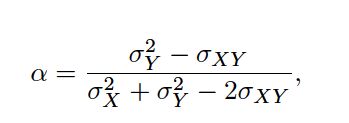
where σ2X = Var(X), σ2Y = Var(Y), and σXY= Cov(X, Y).

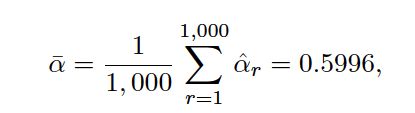
very close to α= 0. 6, and the standard deviation of the estimates is
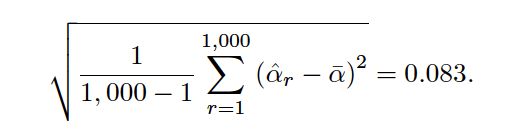
In practice, however, the procedure for estimating SE(ˆα) outlined above cannot be applied, because for real data we cannot generate new samples from the original population.
Rather than repeatedly obtaining independent data sets from the population, we instead obtain distinct data sets by repeatedly sampling observations from the original data set .

