本文由ChardLau原创,转载请添加原文链接https://www.chardlau.com/mean-shift/
今天的文章介绍如何利用Mean Shift算法的基本形式对数据进行聚类操作。而有关Mean Shift算法加入核函数计算漂移向量部分的内容将不在本文讲述范围内。实际上除了聚类,Mean Shift算法还能用于计算机视觉等场合,有关该算法的理论知识请参考这篇文章。
Mean Shift算法原理
下图展示了Mean Shift算法计算飘逸向量的过程:
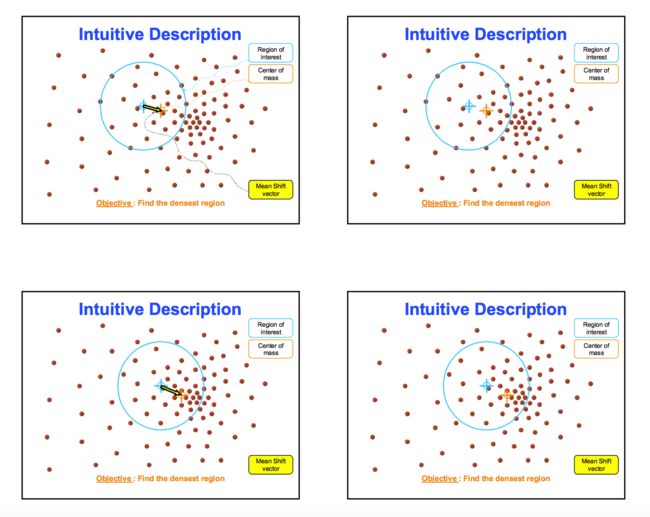
Mean Shift
Mean Shift算法的关键操作是通过感兴趣区域内的数据密度变化计算中心点的漂移向量,从而移动中心点进行下一次迭代,直到到达密度最大处(中心点不变)。从每个数据点出发都可以进行该操作,在这个过程,统计出现在感兴趣区域内的数据的次数。该参数将在最后作为分类的依据。
与K-Means算法不一样的是,Mean Shift算法可以自动决定类别的数目。与K-Means算法一样的是,两者都用集合内数据点的均值进行中心点的移动。
算法步骤
下面是有关Mean Shift聚类算法的步骤:
- 在未被标记的数据点中随机选择一个点作为起始中心点center;
- 找出以center为中心半径为radius的区域中出现的所有数据点,认为这些点同属于一个聚类C。同时在该聚类中记录数据点出现的次数加1。
- 以center为中心点,计算从center开始到集合M中每个元素的向量,将这些向量相加,得到向量shift。
- center = center + shift。即center沿着shift的方向移动,移动距离是||shift||。
- 重复步骤2、3、4,直到shift的很小(就是迭代到收敛),记住此时的center。注意,这个迭代过程中遇到的点都应该归类到簇C。
- 如果收敛时当前簇C的center与其它已经存在的簇C2中心的距离小于阈值,那么把C2和C合并,数据点出现次数也对应合并。否则,把C作为新的聚类。
- 重复1、2、3、4、5直到所有的点都被标记为已访问。
- 分类:根据每个类,对每个点的访问频率,取访问频率最大的那个类,作为当前点集的所属类。
算法实现
下面使用Python实现了Mean Shift算法的基本形式:
import numpy as np
import matplotlib.pyplot as plt
# Input data set
X = np.array([
[-4, -3.5], [-3.5, -5], [-2.7, -4.5],
[-2, -4.5], [-2.9, -2.9], [-0.4, -4.5],
[-1.4, -2.5], [-1.6, -2], [-1.5, -1.3],
[-0.5, -2.1], [-0.6, -1], [0, -1.6],
[-2.8, -1], [-2.4, -0.6], [-3.5, 0],
[-0.2, 4], [0.9, 1.8], [1, 2.2],
[1.1, 2.8], [1.1, 3.4], [1, 4.5],
[1.8, 0.3], [2.2, 1.3], [2.9, 0],
[2.7, 1.2], [3, 3], [3.4, 2.8],
[3, 5], [5.4, 1.2], [6.3, 2]
])
def mean_shift(data, radius=2.0):
clusters = []
for i in range(len(data)):
cluster_centroid = data[i]
cluster_frequency = np.zeros(len(data))
# Search points in circle
while True:
temp_data = []
for j in range(len(data)):
v = data[j]
# Handle points in the circles
if np.linalg.norm(v - cluster_centroid) <= radius:
temp_data.append(v)
cluster_frequency[i] += 1
# Update centroid
old_centroid = cluster_centroid
new_centroid = np.average(temp_data, axis=0)
cluster_centroid = new_centroid
# Find the mode
if np.array_equal(new_centroid, old_centroid):
break
# Combined 'same' clusters
has_same_cluster = False
for cluster in clusters:
if np.linalg.norm(cluster['centroid'] - cluster_centroid) <= radius:
has_same_cluster = True
cluster['frequency'] = cluster['frequency'] + cluster_frequency
break
if not has_same_cluster:
clusters.append({
'centroid': cluster_centroid,
'frequency': cluster_frequency
})
print('clusters (', len(clusters), '): ', clusters)
clustering(data, clusters)
show_clusters(clusters, radius)
# Clustering data using frequency
def clustering(data, clusters):
t = []
for cluster in clusters:
cluster['data'] = []
t.append(cluster['frequency'])
t = np.array(t)
# Clustering
for i in range(len(data)):
column_frequency = t[:, i]
cluster_index = np.where(column_frequency == np.max(column_frequency))[0][0]
clusters[cluster_index]['data'].append(data[i])
# Plot clusters
def show_clusters(clusters, radius):
colors = 10 * ['r', 'g', 'b', 'k', 'y']
plt.figure(figsize=(5, 5))
plt.xlim((-8, 8))
plt.ylim((-8, 8))
plt.scatter(X[:, 0], X[:, 1], s=20)
theta = np.linspace(0, 2 * np.pi, 800)
for i in range(len(clusters)):
cluster = clusters[i]
data = np.array(cluster['data'])
plt.scatter(data[:, 0], data[:, 1], color=colors[i], s=20)
centroid = cluster['centroid']
plt.scatter(centroid[0], centroid[1], color=colors[i], marker='x', s=30)
x, y = np.cos(theta) * radius + centroid[0], np.sin(theta) * radius + centroid[1]
plt.plot(x, y, linewidth=1, color=colors[i])
plt.show()
mean_shift(X, 2.5)
代码链接
上述代码执行结果如下:
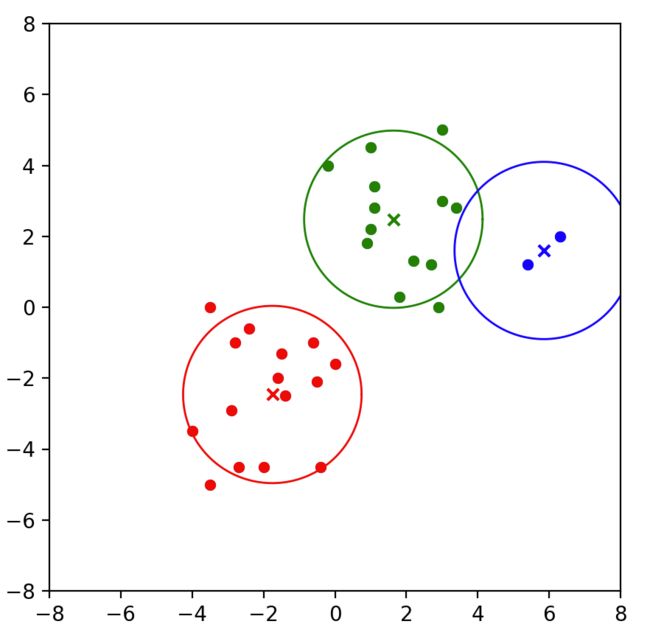
执行结果
其他
Mean Shift算法还有很多内容未提及。其中有“动态计算感兴趣区域半径”、“加入核函数计算漂移向量”等。本文作为入门引导,暂时只覆盖这些内容。